实现用户活跃度排行榜
需求分析
用户活跃度榜单是一个能够鼓励用户参与社区活动的有效手段。
用户活跃度计算方式:
- 用户每访问一个新的页面+1分
- 对于一篇文章,点赞、收藏+2分;取消点赞、取消收藏,将之前的活跃分收回
- 文章评论+3分,删除评论,将之前的活跃分收回
- 关注用户 +2分,取消关注,将之前的活跃分收回
- 发布—篇审核通过的文章+10分,删除文章,将之前的活跃分收回
榜单(分为月榜和日榜):
- 展示活跃度最高的前三十名用户
方案设计
首先是存储单元,针对一个排行榜,思考排行榜上面每一位需要存储哪些信息:
1 | //用来表明具体的用户 |
我们可以使用Redis中的 zset 数据结构来实现,zset维护了一个带权重的有序集合:
- set:集合确保里面的每个元素只出现一次
- 权重:就是我们的score
- zset:根据score进行排序的集合
从zset的特性来看,我们每个用户的积分,丢到zset中,就是一个带权重的元素,而且是已经排好序的了,只需要获取元素对应的index,就是我们预期的排名,非常方便。
如何实现
业务流程
先来梳理一下业务流程,注意我们要考虑幂等性,防止重复加活跃度:
- 根据业务实体,计算需要增加/减少的活跃度
- 对于增加活跃度时:
- 做一个幂等,防止重复添加,因此需要判断下之前有没有重复添加过相关活跃度
- 若幂等了,说明之前增加过活跃度了,则直接返回;否则,执行更新,并做好幂等保存
- 对于减少活跃度时:
- 判断之前有没有加过活跃度,防止扣减为负数
- 之前没有加过,则不可以减少,原样不动
- 之前加过,则执行扣减,并移除幂等判定
- 判断之前有没有加过活跃度,防止扣减为负数
幂等策略
详细的幂等策略可以查看这篇文章如何实现API接口的幂等性 | Raining的小站
我们在这里实现幂等的方式是这样的,直接将用户的每个加分项直接记录在Redis中,在每次加分的时候,查看是否存在记录,从而实现幂等判断。
数据结构
用户的加分项(即记录)如下所示:
1 | //HASH |
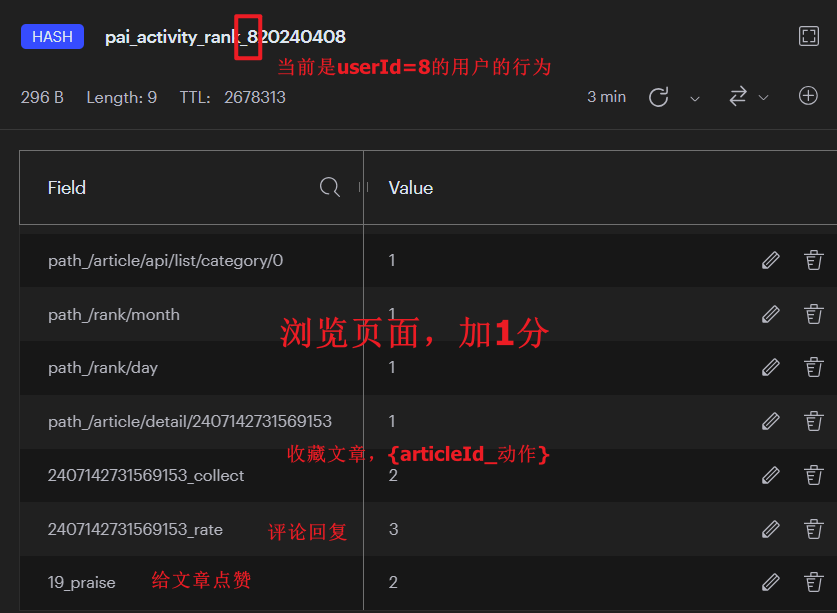
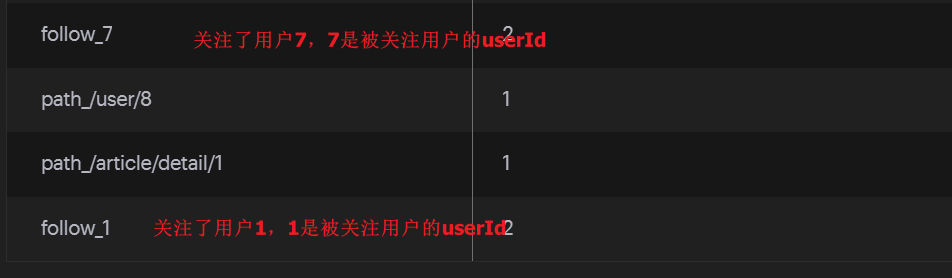
排行榜数据结构如下:
1 | // zset |
这里的 key 就对应着每一天或者每一个月的排行榜,field 是用户 id,value 是活跃度:
1 | activity_rank_202404 {8:50} 表示2024年4月,userId=8的用户活跃度是50 |
实现逻辑
- 计算活跃度score(正为加活跃度,负为减活跃度)和加分项记录field
- 进行幂等判断,判断之前是否更新过相关的活跃度(时间范围为当天内)
- 之前没有记录过
- 如果是加分操作
- 增加加分项记录
- 更新当天和当月的活跃度排行榜,如果是首次初始化榜单,则设置过期时间(日活跃榜单,保存31天;月活跃榜单,保存1年)、
- 如果是减分操作,说明是之前点过赞,今天取消点赞,这样我们不做处理
- 如果是加分操作
- 之前记录过
- 如果是加分操作
- 不做处理,因为之前记录过说明已经加过分了,不重复加分。
- 如果是减分操作
- 删除加分项记录
- 更新当天和当月的活跃度排行榜
- 如果是加分操作
- 之前没有记录过
这里要注意一个细节:
昨天收藏,今天取消收藏,那么按照实际的业务场景,我们应该是要扣减昨天的活跃度(如果扣减今天的活跃度,那就可能成负数了)
但是问题在于,在实际的业务场景中,跨天之后,历史的活跃度─般是固化的,如果你现在去扣减之前的活跃度,给用户的感觉就是我昨天的活跃度100,今天操作—下,咋的昨天活跃度还降低了呢?
所以这种情况我们就不处理了。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Raining的小站!
相关推荐






评论




