如何搭建一个社区系统 —— 4. Filter之全局上下文与全链路traceId
在项目中,我们使用拦截器filter拦截所有的web请求,主要做以下两件事情:
- 实现用户身份识别,并将识别出来的用户信息,保存到
ThreadLocal对应的上下文中,这样在后续的请求链路中,在任何地方都可以直接获取当前的登录用户,从而减少查询数据库的次数。 - 打印请求日志,记录请求耗时,通过MDC添加全链路的traceId,方便追踪定位。
Filter基础知识
Filter称为过滤器,主要用来拦截http请求,在请求之前或者之后做一些事情。

Filter和Interceptor的区别:

具体的流程如下所示:

filter的应用场景主要包括:
- 在filter层,来获取用户的身份
- 可以考虑在filter层做一些常规的校验(如参数校验,referer校验、权限控制等)
- 可以在filter层做运维、安全防护相关的工作(如全链路打点,可以在filter层分配一个
traceld;也可以在这一层做限流等)
具体做法
在过滤器的
doFilter方法中,分为三部分:doBefore:表示将请求转发到Controller执行之前- 记录开始执行时间
- 记录请求相关信息(ThreadLocal变量ReqInfoContext)
- 向MDC中添加全链路的traceId,用于日志跟踪和日志输出
- 访问的域名,访问路径path,clientIp,referer,表单参数,userAgent,token,userId,userInfo,deviceId,最后在线时间,未读消息数。
- 注意:登录认证就是在这里做的,如果登录成功,则userId和userInfo就有值,否则为null
- 打印日志
doFilter:即将请求转发到Controller去执行doAfter:Controller方法执行完- 记录结束时间,计算执行耗时
日志输出
- 一个链路请求完毕,清除MDC,ReqInfoContext
保存请求计数(IP)
ReqInfoContext变量
1 | import lombok.Data; |
Filter写法
1 |
|
关于MDC
简介
MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 、logback及log4j2 提供的一种方便在多线程条件下记录日志的功能。MDC 可以看成是一个与当前线程绑定的哈希表,可以往其中添加键值对。
MDC 中包含的内容可以被同一线程中执行的代码所访问。当前线程的子线程会继承其父线程中的 MDC 的内容。当需要记录日志时,只需要从 MDC 中获取所需的信息即可。MDC 的内容则由程序在适当的时候保存进去。对于一个 Web 应用来说,通常是在请求被处理的最开始保存这些数据。
API说明
- clear() => 移除所有MDC
- get (String key) => 获取当前线程MDC中指定key的值
- put(String key, Object o) => 往当前线程的MDC中存入指定的键值对
- remove(String key) => 删除当前线程MDC中指定的键值对
优点
代码简洁,日志风格统一,不需要在log打印中手动拼写traceId,即LOGGER.info("traceId:{} ", traceId)。
根据MDC 的基本使用规则,只需要通过 %X{LogId}或者%mdc{LogId}(在下图中定义),然后就可以把添加到日志跟踪号添加到日志打印当中了。
1 | [%d{yyyy-MM-dd HH:mm:ss:SSS}] [%-5level] [%t] [%X{LogId}] [%c(%L)] %m%n |
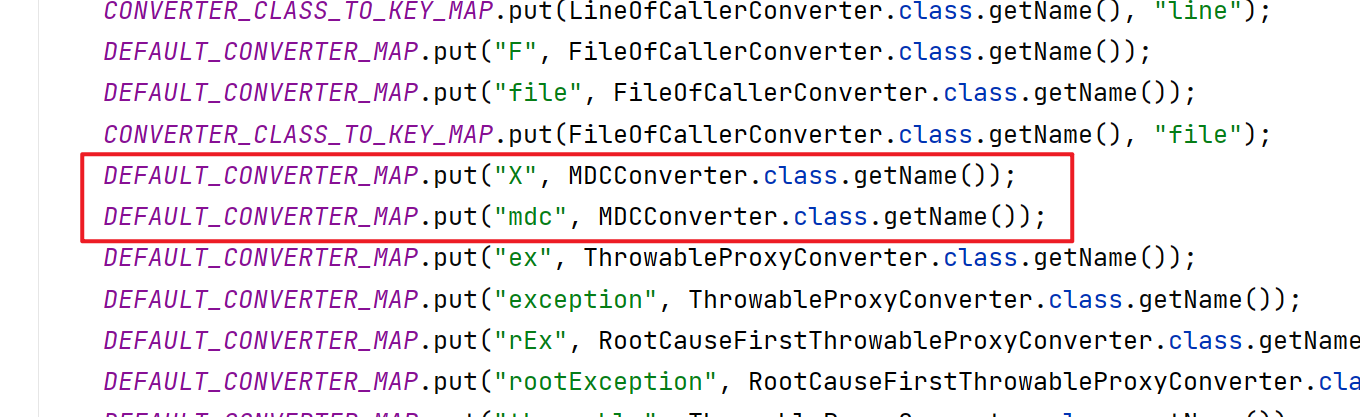
底层原理
MDC底层的实现是ThreadLocal变量,我们来看一下源码:

查看put方法,
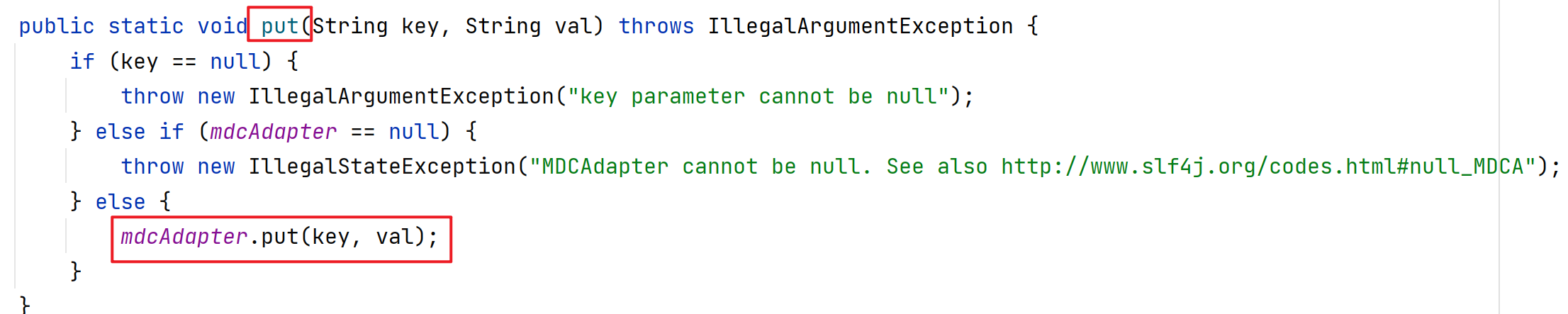
所以关键的地方是这个mdcAdapter变量,继续深入,原来这是个接口!

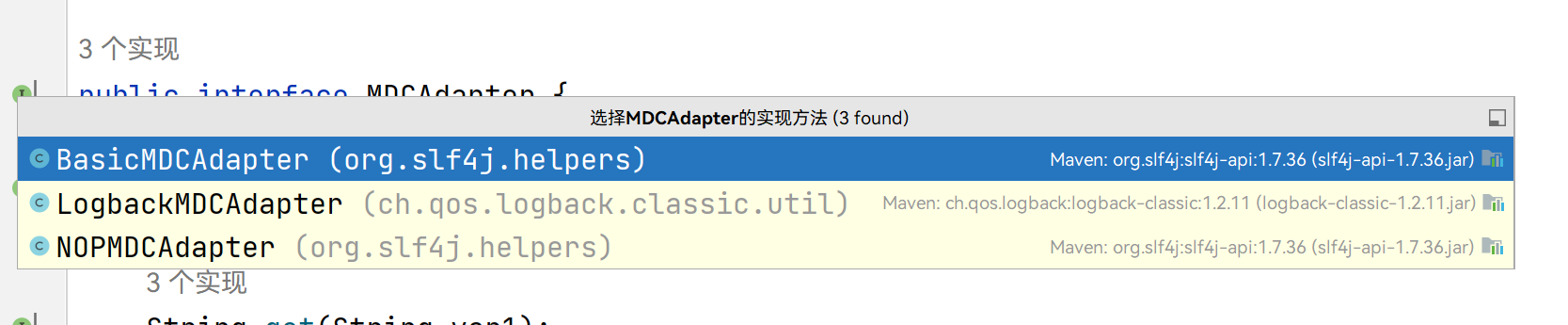
在 Java 的世界里,应该都知道定义接口的目的:就是为了定义规范,让子类去实现。
MDCAdapter 就和 JDBC 的规范类似,专门用于定义操作规范。JDBC 是为了定义数据库操作规范,让数据库厂商(MySQL、DB2、Oracle 等)去实现;而 MDCAdapter 则是让具体的日志组件(logback、log4j等)去实现。
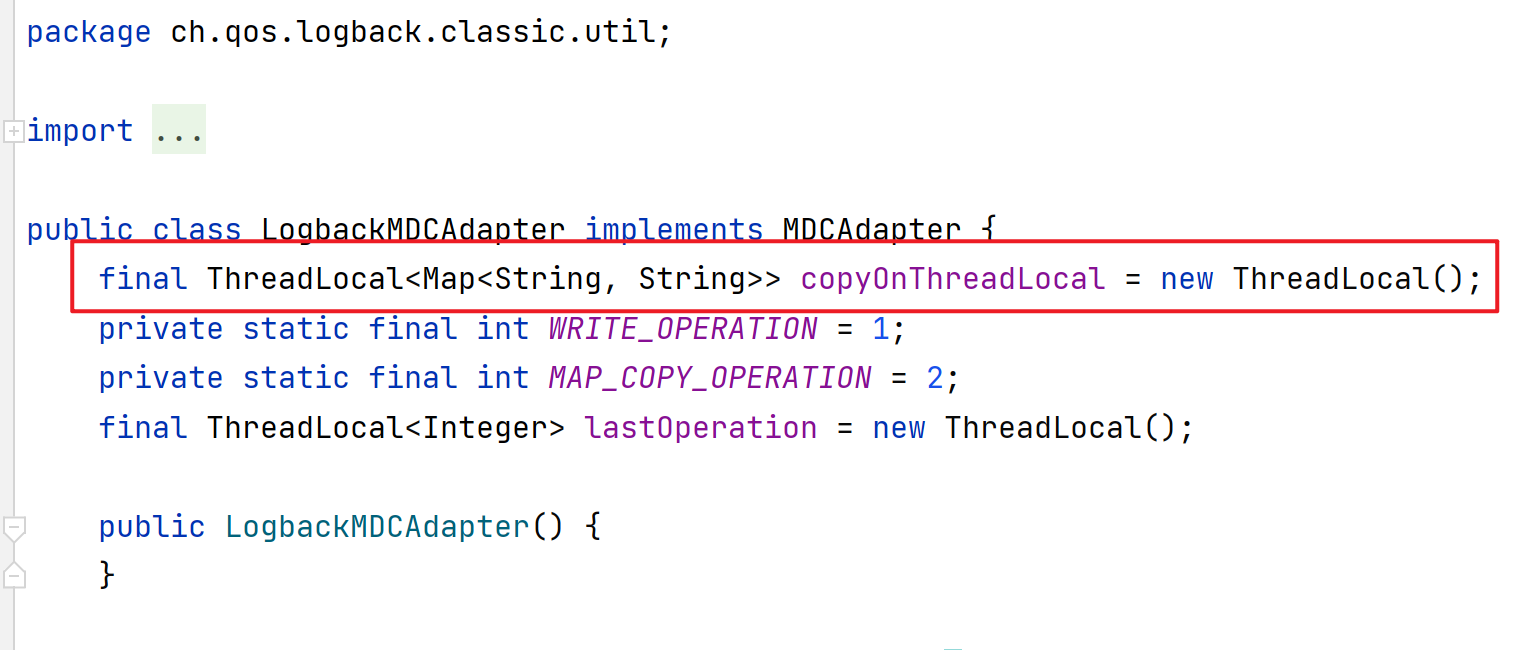
LogbackMDCAdapter实现了MDCAdapter ,如下图所示,可以发现底层就是使用了一个ThreadLocal变量。
traceId
为什么需要traceId?
当我们的系统是分布式或者微服务时,一个用户可能会穿过多个服务,每个服务可能都会生成一些日志,但由于系统是微服务/分布式的,会运行在不同的物理机器上,如果没有一个统一的标识符来链接这些日志,就很难理解一个请求的完整过程。
traceid 就是这样一个标识符,它在请求进入系统时生成,然后沿着请求的执行路径传递给所有参与处理该请求的服务。这些服务在生成日志时,会把traceid包含在日志中。这样,通过搜索同一traceid的所有日志,就可以追踪到整个请求的执行过程。
如何生成traceId?
目前有很多开源项目的实现,我们可以直接使用他们的生成策略,也可以自己去实现。
- SOFATracer 是蚂蚁金服基于 OpenTracing 规范开发的分布式链路跟踪系统。
- SkyWalking是一款开源的应用性能监控系统,它支持对分布式系统中的服务进行追踪、监控和诊断。
SOFATracer
SOFATracer 是蚂蚁金服基于 OpenTracing 规范开发的分布式链路跟踪系统,其核心理念就是通过一个全局的 TraceId 将分布在各个服务节点上的同一次请求串联起来。通过统一的 TraceId 将调用链路中的各种网络调用情况以日志的方式记录下来,同时也提供远程汇报到 Zipkin 进行展示的能力,以此达到透视化网络调用的目的。
https://help.aliyun.com/document_detail/151840.html
SOFATracer 通过 TraceId 来将一个请求在各个服务器上的调用日志串联起来,TraceId 一般由接收请求经过的第一个服务器产生。
产生规则是: 服务器 IP + ID 产生的时间 + 自增序列 + 当前进程号 ,比如:
前 8 位
0ad1348f即产生 TraceId 的机器的 IP,这是一个十六进制的数字,每两位代表 IP 中的一段,我们把这个数字,按每两位转成 10 进制即可得到常见的 IP 地址表示方式10.209.52.143,您也可以根据这个规律来查找到请求经过的第一个服务器。后面的 13 位
1403169275002是产生 TraceId 的时间。之后的 4 位1003是一个自增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。最后的 5 位56696是当前的进程 ID,为了防止单机多进程出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。
SkyWalking
Skwalking的TraceId的生成是通过GlobalIdGenerator的generate()方法来生成的,总共包含三部分:
第一部分:具体是应用程序实例 ID
第二部分:线程 ID
第三部分:时间戳*10000+当前线程中的 seq,seq的值介于 0(包含)和 9999(包含)之间
三部分通过.来分隔开。
内容我也贴在这里了:
1 | package org.apache.skywalking.apm.agent.core.context.ids; |
我们的策略
我们自定义了一个traceId生成器,其中的 generate 方法如下所示,其实原理都差不多。
1 | /** |
参考
- MDC是什么?用法、源码一锅端:https://zhuanlan.zhihu.com/p/469070410
- Spring Boot 中使用 MDC 追踪一次请求全过程:https://blog.csdn.net/u012410733/article/details/109406093
- SpringBoot+MDC实现全链路调用日志跟踪:https://juejin.cn/user/2576910985986056/posts)https://juejin.cn/post/6844904101483020295
- Filter和Interceptor的联系和区别:https://zhuanlan.zhihu.com/p/456610808
- 分布式链路追踪:TraceIdFilter + MDC + Skywalking:https://juejin.cn/post/7278498472860581925
- 全链路追踪体验—TraceId的生成:https://juejin.cn/post/7135611432808218661










