Java类文件结构——以HelloWorld为例逐字节分析
本文旨在通过对HelloWorld代码编译后的类文件进行逐字节分析,讲解Class类文件的结构。
准备工作
先准备一段 Java 代码
1 | package com.raining; |
然后,用 javac 编译,得到class文件

class文件是一组以字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在文件中。注意是大端机(高位在前)的存储方式。
准备工具WinHex,WinHex可以轻松的以十六进制的格式打开文本文件,方便我们查看class文件中的二进制码。使用WinHex打开class文件,界面如下图所示:

文字版如下:
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
可以看到,这里是按字节寻址,一个地址上面存放一个字节(1byte=8bit),即8位,用两个16进制表示,比如,在地址0x0000000位置上,存放着CA。在十六进制值中:
- C代表着十进制中的12,换算成二进制是
1100 - A代表着十进制中的10,换算成二进制是
1010
也就是说,地址0x0000000位置上存放着11001010。
下文我们将用很大篇幅详细分析上述文件。
类文件结构
Class文件格式采用一种类似C语言结构体的伪结构来存储数据,这种伪结构只有两种数据结构,无符号数和表:
- 无符号数属于基本的数据类型,以u1,u2,u4,u8来分别代表1个字节,2个字节,4个字节,8个字节的无符号数。无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成的字符串值。
- 表是由多个无符号数或者其他表作为数据项构成的符合数据结构,为了便于区分,所有表的命名都习惯性地以
_info结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上也可以视作一张表。
Class文件的结构格式如下表所示:
| 类型 | 名称 | 数量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count - 1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
详细分析
1. 魔数与Class文件版本号
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
结合类结构规定分析:
1 | u4 magic 1 |
Class文件开头首先是4个字节,代表魔数(magic number),唯一的作用就是确定这个文件是否是一个能被虚拟机接受的Class文件(类似文件拓展名)。
0x00000004和0x00000005两个字节,代表着次版本号(minor_version)。从JDK1.2以后,直到JDK12均为使用,全部固定为零。0x00000006和0x00000007两个字节,代表着主版本号(major_version)。Java的版本号从45开始,比如JDK1.1是45,JDK1.2是46,…,那么JDK11是55,换算成十六进制是37H,正好与上面字节对应。
这里有一个需要注意的地方,因为Class文件采用的是大端机存储模式,所以
00(低位)37(高位)代表的是0037,而不是3700。
2.常量池
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
同样,我们来看一下类文件的格式规定:
1 | u2 constant_pool_count 1 |
地址0x00000008和0x00000009存储了constant_pool_count,值位1D,换算为十进制为29,代表存储了28个常量,索引为[1-28]。
如何查看常量池中的每一个常量,我们还需要 1 张表格(常量池的项目类型):
| 类型 | 标志 | 描述 |
|---|---|---|
| CONSTANT_Utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | int类型字面值 |
| CONSTANT_Float_info | 4 | float类型字面值 |
| CONSTANT_Long_info | 5 | long类型字面值 |
| CONSTANT_Double_info | 6 | double类型字面值 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | String类型字面值 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的部分符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MethodType_info | 16 | 表示方法类型 |
| CONSTANT_Dynamic_info | 17 | 表示一个动态计算常量 |
(1)第 1 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
0x0000000A存储了0A,对应着表中第10项CONSTANT_Methodref_info。然后,再查阅对应的表格:
| 常量CONSTANT_Methodref_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为10 | |
| index | u2 | 指向声明字段的类或者接口描述符CONSTANT_Class_info的索引项 | |
| index | u2 | 指向字段描述符CONSTANT_NameAndType的索引项 |
info代表这个常量是一个“表”结构,共有三项:
第二项是u2,于是向后查看 2 个字节,是0006,代表着指向第6个索引。
第三项是u2,于是再向后查看 2 个字节,是000F,代表着指向第 15 个索引。
(2)第 2 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x0000000F位置存储了09,查阅表格,发现是CONSTANT_Fieldref_info类型。然后,查阅对应的表格:
| 常量CONSTANT_Fieldref_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为9 | |
| index | u2 | 指向声明字段的类或者接口描述符CONSTANT_Class_info的索引项 | |
| index | u2 | 指向字段描述符CONSTANT_NameAndType的索引项 |
info代表这个常量是一个“表”结构,共有三项:
第二项是u2,于是向后查看 2 个字节,是0010,代表着指向第16个索引。
第三项是u2,于是再向后查看 2 个字节,是0011,代表着指向第 17 个索引。
(3)第 3 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x00000014位置存储了08,查阅表格,发现是CONSTANT_String_info类型,说明第 2 个常量是字段的符号引用。然后,查阅对应的表格:
| 常量CONSTANT_String_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为8 | |
| index | u2 | 指向字符串字面量的索引 |
info代表这个常量是一个“表”结构,共有2项:
第二项是u2,于是向后查看 2 个字节,是0012,代表着指向第18个索引。
(4)第 4 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x00000017位置存储了0A,查阅表格,发现是CONSTANT_Methodref_info类型。然后,查阅对应的表格:
| 常量CONSTANT_Methodref_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为10 | |
| index | u2 | 指向声明字段的类或者接口描述符CONSTANT_Class_info的索引项 | |
| index | u2 | 指向字段描述符CONSTANT_NameAndType的索引项 |
info代表这个常量是一个“表”结构,共有三项:
第二项是u2,于是向后查看 2 个字节,是0013,代表着指向第19个索引。
第三项是u2,于是再向后查看 2 个字节,是0014,代表着指向第 20 个索引。
(5)第 5 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x0000001C位置存储了07,查阅表格,发现是CONSTANT_Class_info类型。然后,查阅对应的表格:
| 常量CONSTANT_Class_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为7 | |
| index | u2 | 指向全限定名常量项的索引 |
info代表这个常量是一个“表”结构,共有2项:
第二项是u2,于是向后查看 2 个字节,是0015,代表着指向第21个索引。
(6)第 6 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x0000001F位置存储了07,查阅表格,发现是CONSTANT_Class_info类型。然后,查阅对应的表格:
| 常量CONSTANT_Class_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为7 | |
| index | u2 | 指向全限定名常量项的索引 |
info代表这个常量是一个“表”结构,共有2项:
第二项是u2,于是向后查看 2 个字节,是0016,代表着指向第22个索引。
(7)第 7 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x00000022位置存储了01,查阅表格,发现是CONSTANT_Utf8_info类型。然后,查阅对应的表格:
| 常量CONSTANT_Utf8_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为1 | |
| length | u2 | UTF-8编码的字符串占用的字节数 | |
| bytes | u1 | 长度为length的UTF-8编码的字符串 |
info代表这个常量是一个“表”结构,共有3项:
第二项是u2,于是向后查看 2 个字节,是0006,代表着该字符串的长度为6个字节。
第三项是u1,但是并不是向后查看1个字节,而是长度为length的字节。
查阅ASCII码转换表,可以得到字符串<init>,说明第 7 个常量是字符串值。
1 | 3C696E69743E |
(8)第 8 个常量
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
继续向后看一个字节u1,0x0000002B位置存储了01,查阅表格,发现是CONSTANT_Utf8_info类型。然后,查阅对应的表格:
| 常量CONSTANT_Utf8_info | 项目 | 类型 | 描述 |
|---|---|---|---|
| tag | u1 | 值为1 | |
| length | u2 | UTF-8编码的字符串占用的字节数 | |
| bytes | u1 | 长度为length的UTF-8编码的字符串 |
info代表这个常量是一个“表”结构,共有3项:
第二项是u2,于是向后查看 2 个字节,是0003,代表着该字符串的长度为3个字节。
第三项是u1,但是并不是向后查看1个字节,而是长度为length的字节。
查阅ASCII码转换表,可以得到字符串()V,说明第 8 个常量是字符串值。
1 | 282956 |
(9)其他常量……javap!
相信读者到这里已经理解Class文件常量的组织方式了,其他常量不再详细分析。
Oracle公司其实已经为我们准备好了一个专门用于分析Class文件字节码的工具:javap。运行下面的代码:
1 | javap -v HelloWorld.class |
输出信息为:
1 | Classfile /C:/Users/chao/Desktop/Java_Perf/Demo/JVMSDemo/src/com/raining/HelloWorld.class |
其中,常量池为:
1 | Constant pool: |
可以看到,javap 已经帮我们把整个常量池中的28个常量都计算出来了,读者可以自行与我们之前计算的结果对比。
3.访问标志
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
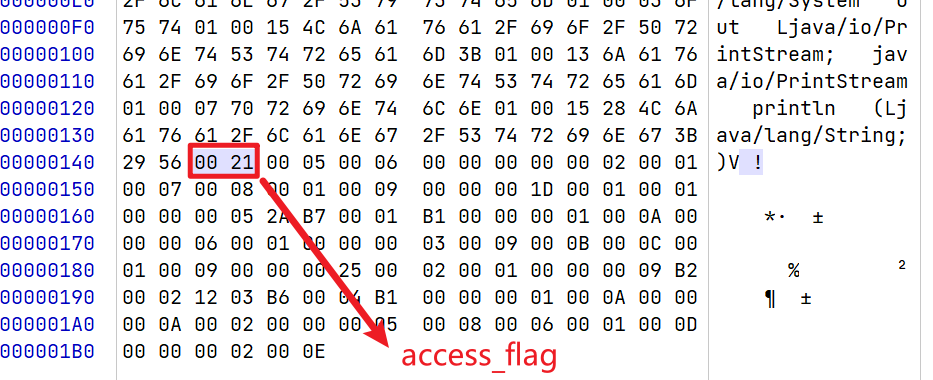
在常量池结束之后,紧接着的 2 个字节代表访问标志(access_flag)
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | access_flags | 1 |
因为占用 2 个字节(2 * 8bit = 16位),所以一共有16个标志位可以使用,但是当前只定义了9个,没有用到的标志位要求一律为零。具体的标志位和含义如下:
| 标志名称 | 标志位 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 是否为public类型 |
| ACC_FINAL | 0x0010 | 是否被声明为final,只有类可以设置 |
| ACC_SUPER | 0x0020 | 是否允许使用invokespecial字节码指令的新语义,invokespecial指令的予以在JDK1.2发生过变化,为了区别,JDK1.0.2之后编译出来的类的这个标志必须为真 |
| ACC_INTERFACE | 0x0200 | 标记这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 是否为abstract类型,对于接口或者抽象类来说,此标志值为真,其他类型值为假 |
| ACC_SYNTHETIC | 0x1000 | 标识这个类并非由用户的代码产生的 |
| ACC_ANNOTATION | 0x2000 | 标识这是一个注解 |
| ACC_ENUM | 0x4000 | 标识这是一个枚举 |
| ACC_MODULE | 0x8000 | 标识这是一个模块 |
21代表着这是一个ACC_PUBLIC的普通类,使用了JDK1.2之后的编译器进行编译。这也可以从javac命令得到的输出中看出,互相验证。
1 | flags: (0x0021) ACC_PUBLIC, ACC_SUPER |
4.类索引、父类索引与接口索引集合
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
类索引(this_classs)和父类索引(super_class)都是一个u2类型的数据,接口索引集合(interfaces)是一组u2类型的数据的集合。

向后看 2 个字节u2,0x00000144和0x00000145位置存储了0005,查阅表格,发现是CONSTANT_Class_info类型。最终,找到为:
1 | #5 = Class #21 // com/raining/HelloWorld |
向后看 2 个字节u2,0x00000146和0x00000147位置存储了0006,查阅表格,发现是CONSTANT_Class_info类型。最终,找到为:
1 | #6 = Class #22 // java/lang/Object |
向后看 2 个字节u2,0x00000148和0x00000149位置存储了0000,说明接口数量为 0。
5.字段表集合
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
字段表结构:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
对于每一个field,结构如下表所示:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | access_flags | 1 |
| u2 | name_index | 1 |
| u2 | descriptor_index | 1 |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
向后看 2 个字节u2,0x0000014A和0x0000014B位置存储了0000,说明fields_count=0,没有field。所以这里就不再展开。
6.方法表集合
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
方法表结构:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
Class文件存储格式中对method的描述与对字段的描述采用了几乎完全一致的方式。对于每一个method,结构如下:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | access_flags | 1 |
| u2 | name_index | 1 |
| u2 | descriptor_index | 1 |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
向后看 2 个字节u2,0x0000014C和0x0000014D位置存储了0002,说明methods_count=2,存在两个method。
(1)第 1 个method
向后看 2 个字节u2,0001,对应access_flags,对应ACC_PUBLIC。
向后看 2 个字节u2,0007,对应name_index,对应一个UTF-8字符串,为<init>。
向后看 2 个字节u2,0008,对应descriptor_index,对应一个UTF-8字符串,为()V。
向后看 2 个字节u2,0001,对应attributes_count,代表有 1 个attribute。
突然,我们发现进行不下去了,attribute_info这个表的结构是什么……,这里插入讲解一下,注意保持住思路,别被突如其来的表格打乱。
attribute_info表的结构如下所示:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | info | attribute_length |
其中Code属性的结构表:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | max_stack | 1 |
| u2 | max_loacls | 1 |
| u4 | code_length | 1 |
| u1 | code | code_length |
| u2 | exception_table_length | 1 |
| exception_info | exception_table | exception_table_length |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
好了,有了表结构,我们就知道这么取值了。
向后看 2 个字节u2,0009,对应attribute_name_index,它是一项指向CONSTANT_Utf-8_info型常量的索引,查表为Code,它代表了该属性的属性名称。
根据Code属性的结构表:
向后看 4 个字节u4,00 00 00 1D,对应attribute_length,长度为29,如下所示。
1 | 00 01 00 01 00 00 00 05 2A B7 00 01 B1 00 00 00 01 00 0A 00 00 00 06 00 01 00 00 00 03 |
向后看 2 个字节u2,0001,对应max_stack,值为1
向后看 2 个字节u2,0001,对应max_loacls,值为1
向后看 4 个字节u4,00 00 00 05,对应code_length,值为5
向后看 5 个字节code_length,这就是所谓的字节码!!!
1 | 2A B7 00 01 B1 |
向后看 2 个字节u2,0000,对应exception_table_length,值为0,说明没有exception_table
向后看 2 个字节u2,0001,对应attributes_count,值为1,说明有一个attribute。
接下来又是一个attribute:
向后看 2 个字节u2,000A,对应attribute_name_index,它是一项指向CONSTANT_Utf-8_info型常量的索引,查表为LineNumberTable,它代表了该属性的属性名称。
LineNumberTable 表的结构如下所示:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | line_number_table_length | 1 |
| line_number_info | line_number_table | line_number_table_length |
其中,line_number_info表包含start_pc和line_number两个u2类型的数据项前者是字节码行号,后者是Java源码行号。
向后看 4 个字节u4,00000006,对应attribute_length,值为6。
向后看 2 个字节u2,0001,对应line_number_table_length,值为1。
接下来就是一项line_number_info:
- 向后看 2 个字节
u2,0000,对应start_pc,字节码行号 - 向后看 2 个字节
u2,0003,对应line_number,Java源码行号
总结一下:
1 | //第一个方法 |
(2)第 2 个method
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
再将每个method的结构表贴一遍:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | access_flags | 1 |
| u2 | name_index | 1 |
| u2 | descriptor_index | 1 |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
向后看 2 个字节u2,0009,对应access_flags,对应ACC_PUBLIC和ACC_STATIC。
向后看 2 个字节u2,000B,对应name_index,对应一个UTF-8字符串,为main。
向后看 2 个字节u2,000C,对应descriptor_index,对应一个UTF-8字符串,为([Ljava/lang/String;)V。
向后看 2 个字节u2,0001,对应attributes_count,代表有 1 个attribute。
接下来分析这个attribute:
向后看 2 个字节u2,0009,对应attribute_name_index,它是一项指向CONSTANT_Utf-8_info型常量的索引,查表为Code,它代表了该属性的属性名称。
根据Code属性的结构表:
向后看 4 个字节u4,00 00 00 25,对应attribute_length,长度为37(十进制),如下所示。
1 | 00 02 00 01 00 00 00 09 B2 00 02 12 03 B6 00 04 B1 00 00 00 01 00 0A 00 00 |
向后看 2 个字节u2,0002,对应max_stack,值为2
向后看 2 个字节u2,0001,对应max_loacls,值为1
向后看 4 个字节u4,00 00 00 09,对应code_length,值为9
向后看 9 个字节code_length,字节码!!!
1 | B2 00 02 12 03 B6 00 04 B1 |
向后看 2 个字节u2,0000,对应exception_table_length,值为0,说明没有exception_table
向后看 2 个字节u2,0001,对应attributes_count,值为1,说明有一个attribute。
接下来分析这个attribute:
向后看 2 个字节u2,000A,对应attribute_name_index,它是一项指向CONSTANT_Utf-8_info型常量的索引,查表为LineNumberTable。
接下来分析这个LineNumberTable:
向后看 4 个字节u4,0000000A,对应attribute_length,值为10。
向后看 2 个字节u2,0002,对应line_number_table_length,值为2。
接下来就是 2 项line_number_info:
- 第一项:
- 向后看 2 个字节
u2,0000,对应start_pc,字节码行号 - 向后看 2 个字节
u2,0005,对应line_number,Java源码行号
- 向后看 2 个字节
- 第二项:
- 向后看 2 个字节
u2,0008,对应start_pc,字节码行号 - 向后看 2 个字节
u2,0006,对应line_number,Java源码行号
- 向后看 2 个字节
总结一下:
1 | //第 2 个方法 |
7.属性表集合
大家绕了那么久,不要忘记我们还有最后一项属性表集合,前文所有的attribute_info都是子属性!
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
1 | Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F |
向后看 2 个字节u2,0001,对应attributes_count,值为1,说明有一个attribute。
接下来分析这个attribute:
向后看 2 个字节u2,000D,对应attribute_name_index,它是一项指向CONSTANT_Utf-8_info型常量的索引,查表为SourceFile。
SourceFile的属性结构表如下:
| 类型 | 名称 | 数量 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | sourcefile_index | 1 |
向后看 4 个字节u4,00000002,对应attribute_length,值为2,说明这个attribute长度为2。
所以向后看 2 个字节,000E,对应sourcefile_index,它是一项指向CONSTANT_Utf-8_info型常量的索引,查表为HelloWorld.java。
总结一下:
1 | SourceFile: HelloWorld.java |
字节码指令
<init>函数
我们先来看一下<init函数的字节码指令:
1 | Code: |
查表翻译得到:
1 | aload_0 //将第1个引用类型本地变量推送到栈顶 |
main函数
main方法的字节码指令:
1 | Code: |
查表翻译得到:
1 | getstatic //获取指定类的静态域,并将其值压入栈顶 |
由于本文的主旨是分析类文件结构,而不是专门探究字节码指令,所以不详细展开,读者若希望深入分析,可以自行查阅相关资料。
参考
- 《深入理解Java虚拟机》,周志明。








