引言 什么是JVM?
定义:英文Java Virtual Machine,一种能够运行java bytecode的虚拟机,以堆栈结构机器来进行实做。最早由Sun微系统所研发并实现第一个实现版本,是Java平台的一部分,能够运行以Java语言写作的软件程序。(维基百科)
好处:
一次编写,到处运行
自动内存管理,垃圾回收功能
数组下标越界检查
多态
比较(jvm,jre,jdk):
学习JVM有什么用?
常见的JVM
学习路线
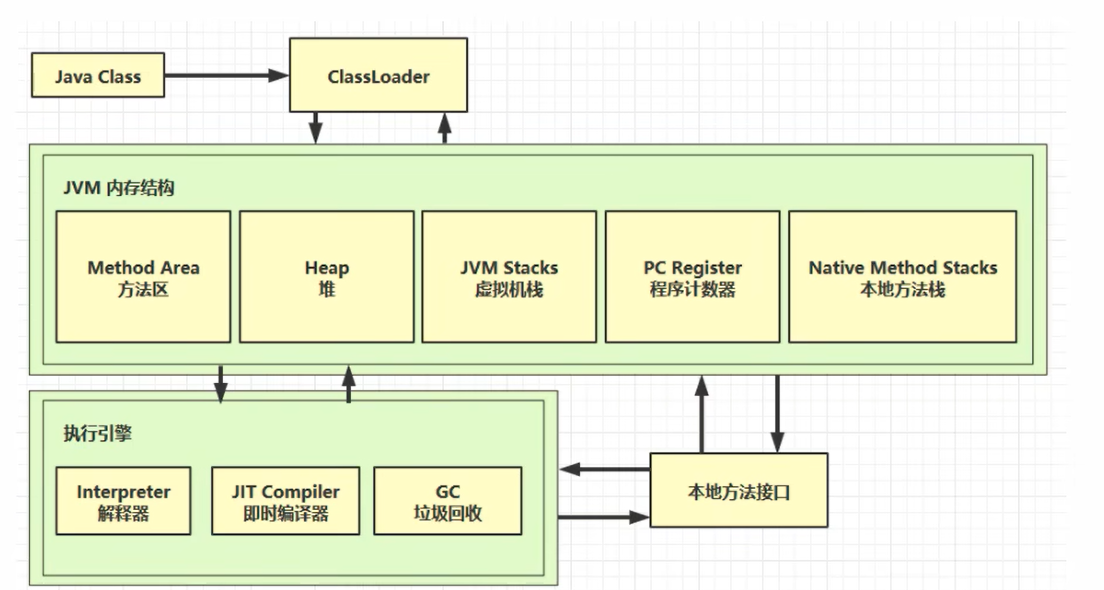
类从Java源代码编译为Java字节码,通过类加载器加载到JVM中去运行。
类被存放在方法区,类的实例,对象放在堆里,堆里的对象在调用方法时,会用到虚拟机栈,程序计数器,本地方法栈。
方法执行时,每行代码由解释器逐行执行,方法中的热点代码由JIT即时编译,优化。
GC模块会对堆里面一些不再使用的对象进行垃圾回收。
一些Java代码不方便实现的功能,需要和操作系统打交道,所以需要调用本地方法接口。
学习顺序:
JVM内存结构
垃圾回收机制
类的字节码结构与编译器优化
类加载器
运行期即时编译器
JVM的内存结构 程序计数器 定义:Program Counter Register程序计数器(寄存器)
特点:
虚拟机栈 定义 Java Virtual Machine Stacks(Java虚拟机栈)
每个线程运行时所需要的内存,称为虚拟机栈。
每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存(参数,局部变量,返回地址)。
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。
问题辨析:
垃圾回收是否涉及栈内存?
栈内存分配越大越好吗?
答:不是,栈越大,能进行更多次的方法递归调用,但是总共可以开出的栈的数量就会减小,相应支持的线程数就会减小。
方法内的局部变量是否线程安全?
答:
如果方法内的局部变量没有逃离方法的作用范围,它是线程安全的。
如果局部变量引用了对象,并逃离了方法的作用范围,需要考虑线程安全。
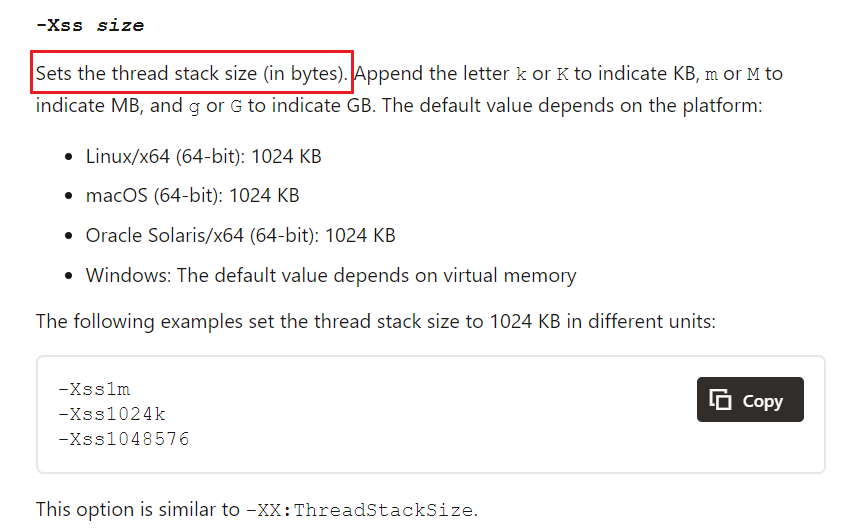
可以通过-Xss调节虚拟机栈的大小:
栈内存溢出
(1)栈帧过多(递归调用)
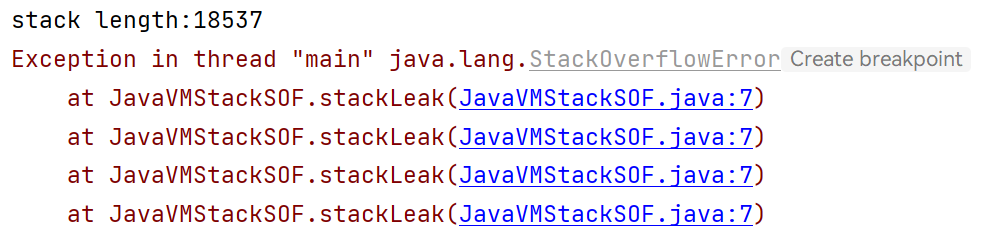
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class JavaVMStackSOF { private int stackLength = 1 ; public void stackLeak () { stackLength++; stackLeak(); } public static void main (String[] args) throws Throwable{ JavaVMStackSOF oom = new JavaVMStackSOF (); try { oom.stackLeak(); } catch (Throwable e) { System.out.println("stack length:" + oom.stackLength); throw e; } } }
报错如下StackOverflowError:
(2)第三方库错误(循环依赖)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 package demo;import com.fasterxml.jackson.annotation.JsonIgnore;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jackson.databind.ObjectMapper;import java.util.Arrays;import java.util.List;public class StackDemo2 { public static void main (String[] args) throws JsonProcessingException { Dept d = new Dept (); d.setName("Market" ); Emp e1 = new Emp (); e1.setName("Zhang" ); e1.setDept(d); Emp e2 = new Emp (); e2.setName("Li" ); e2.setDept(d); d.setEmps(Arrays.asList(e1, e2)); ObjectMapper mapper = new ObjectMapper (); System.out.println(mapper.writeValueAsString(d)); } } class Emp { private String name; @JsonIgnore private Dept dept; public String getName () { return name; } public void setName (String name) { this .name = name; } public Dept getDept () { return dept; } public void setDept (Dept dept) { this .dept = dept; } } class Dept { private String name; private List<Emp> emps; public String getName () { return name; } public void setName (String name) { this .name = name; } public List<Emp> getEmps () { return emps; } public void setEmps (List<Emp> emps) { this .emps = emps; } }
报错如下StackOverflowError:
可以通过添加@JsonIgnore注解解决报错。
线程运行诊断 (1)案例1:CPU占用过多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.io.PrintStream;public class HelloWorld { public static void main (String[] args) { PrintStream out = System.out; out.println(1 ); out.println(2 ); out.println(3 ); int a = 1 ; while (true ) { if (a < 0 ) break ; } out.println(4 ); out.println(5 ); } }
top命令:实时显示系统中各个进程的资源占用情况,可以定位到进程,拿到异常的进程编号PID。ps命令,查看所有线程的信息,H是打印进程树,-eo是指定显示哪些感兴趣的信息。
ps H -eo pid,tid,%cpu也可以直接筛选ps H -eo pid,tid,%cpu | grep PID
jps也可以直接使用jps命令获得进程ID。jstack命令,可以根据线程ID找到有问题的线程,进一步定位到问题代码的源码行数。
使用:jstack 进程ID
找到出现问题的行数(while true模拟)
(2)案例2:程序运行很长时间没有结果
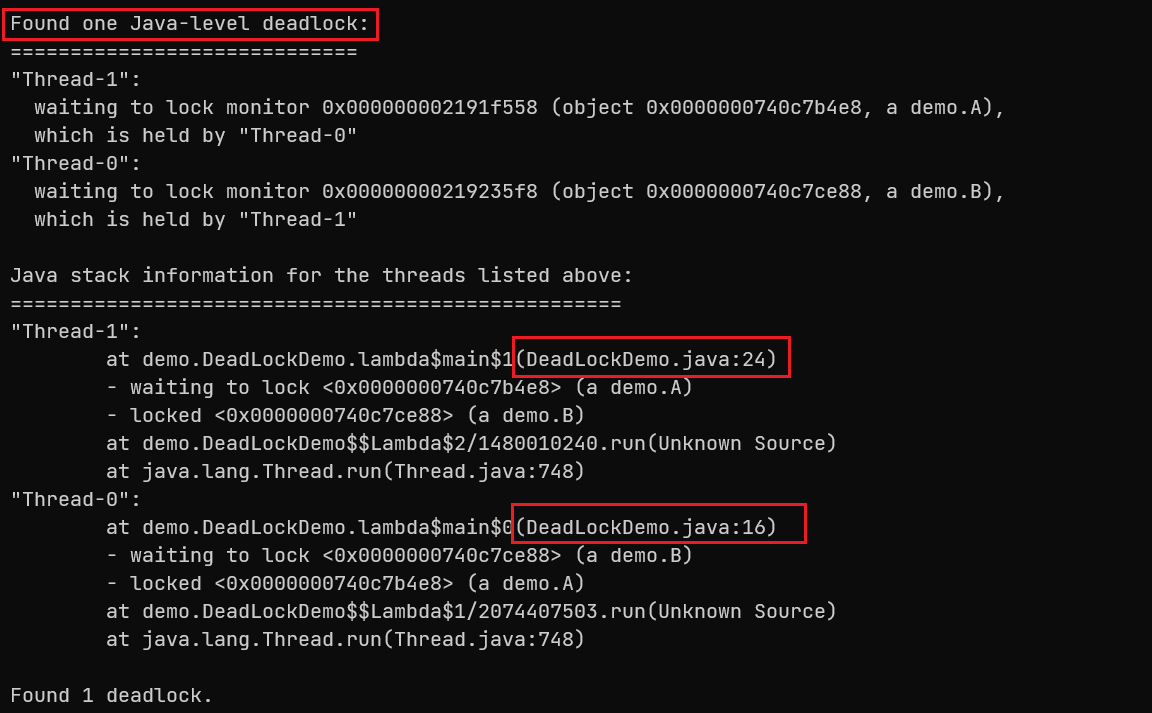
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package demo;public class DeadLockDemo { static A a = new A (); static B b = new B (); public static void main (String[] args) throws InterruptedException { new Thread (() -> { synchronized (a) { try { Thread.sleep(2000 ); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (b) { System.out.println("我获得了a和b" ); } } }).start(); Thread.sleep(1000 ); new Thread (() -> { synchronized (b) { synchronized (a) { System.out.println("我获得了a和b" ); } } }).start(); } } class A {};class B {};
使用jstack发现死锁。
本地方法栈 定义:Java虚拟机调用本地方法时,需要给本地方法提供的内存空间。native方法,比如在Object类中就有很多本地方法。
堆 定义 Heap堆:通过new关键字,创建的对象都会使用堆内存。
它是线程共享的,堆中对象都需要考虑线程安全的问题。
有垃圾回收机制。
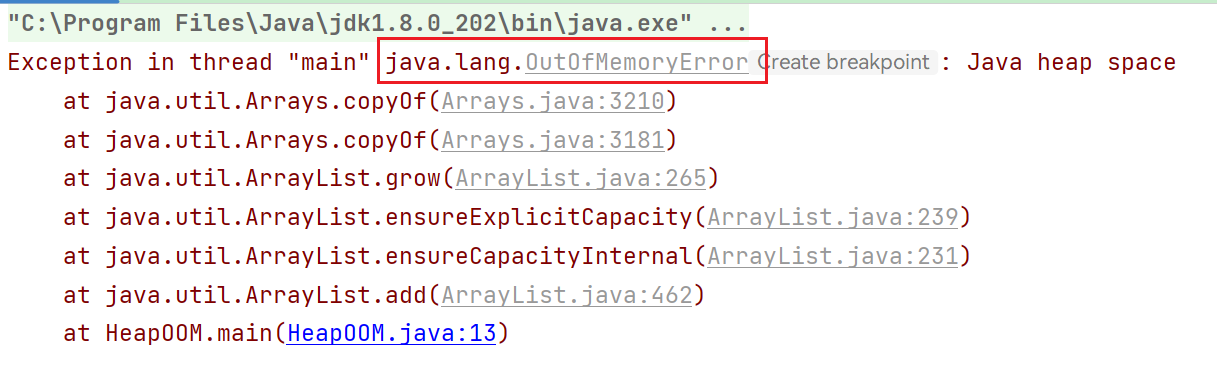
堆内存溢出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.ArrayList;import java.util.List;public class HeapOOM { static class OOMObject { } public static void main (String[] args) { List<OOMObject> list = new ArrayList <OOMObject>(); while (true ) { list.add(new OOMObject ()); } } }
报错信息:
堆内存诊断
jps工具
jmap工具
查看堆内存占用情况。
jhsdb jmap --heap --pid 进程ID
jconsole工具
visualvm工具
(1)使用jmap分析示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package demo;public class HeapDemo { public static void main (String[] args) throws InterruptedException { System.out.println("1..." ); Thread.sleep(30000 ); byte [] array = new byte [1024 *1024 *10 ]; System.out.println("2..." ); Thread.sleep(20000 ); array = null ; System.gc(); System.out.println("3..." ); Thread.sleep(1000000L ); } }
(2)使用jconsole监测示例:
概览:
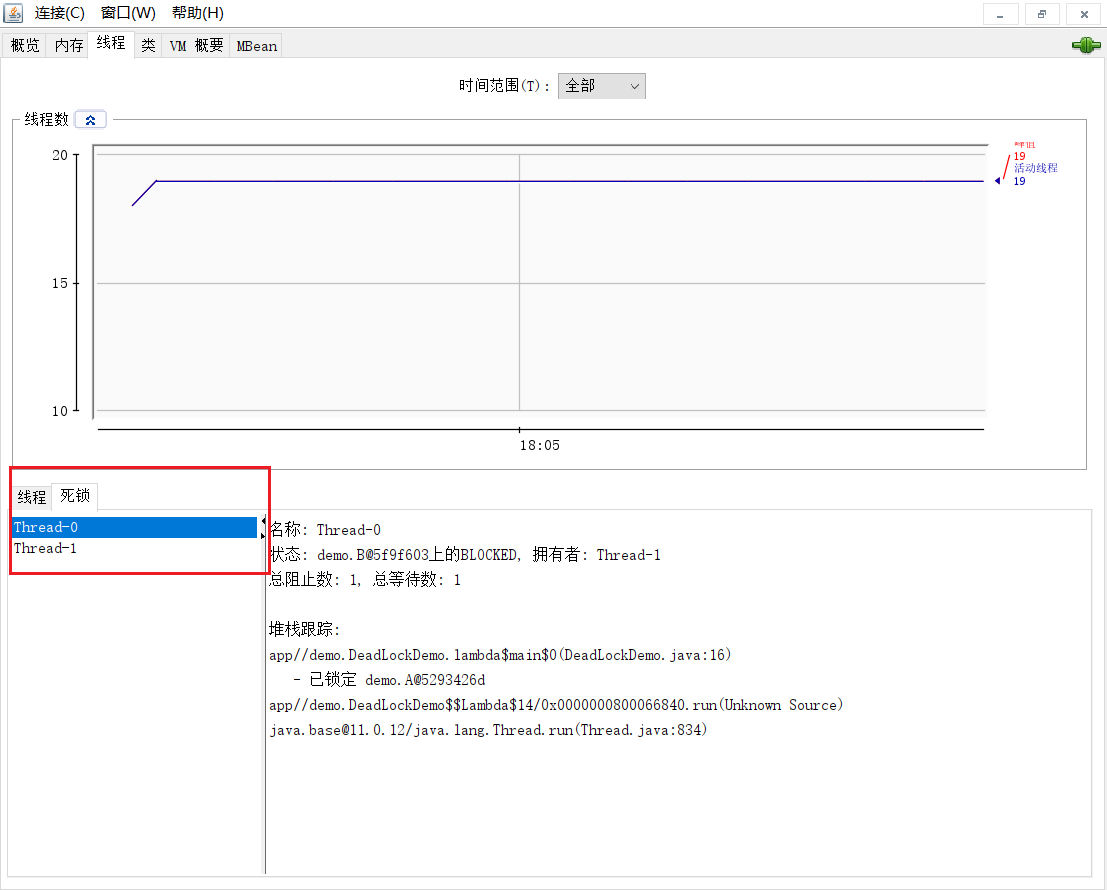
检测死锁:
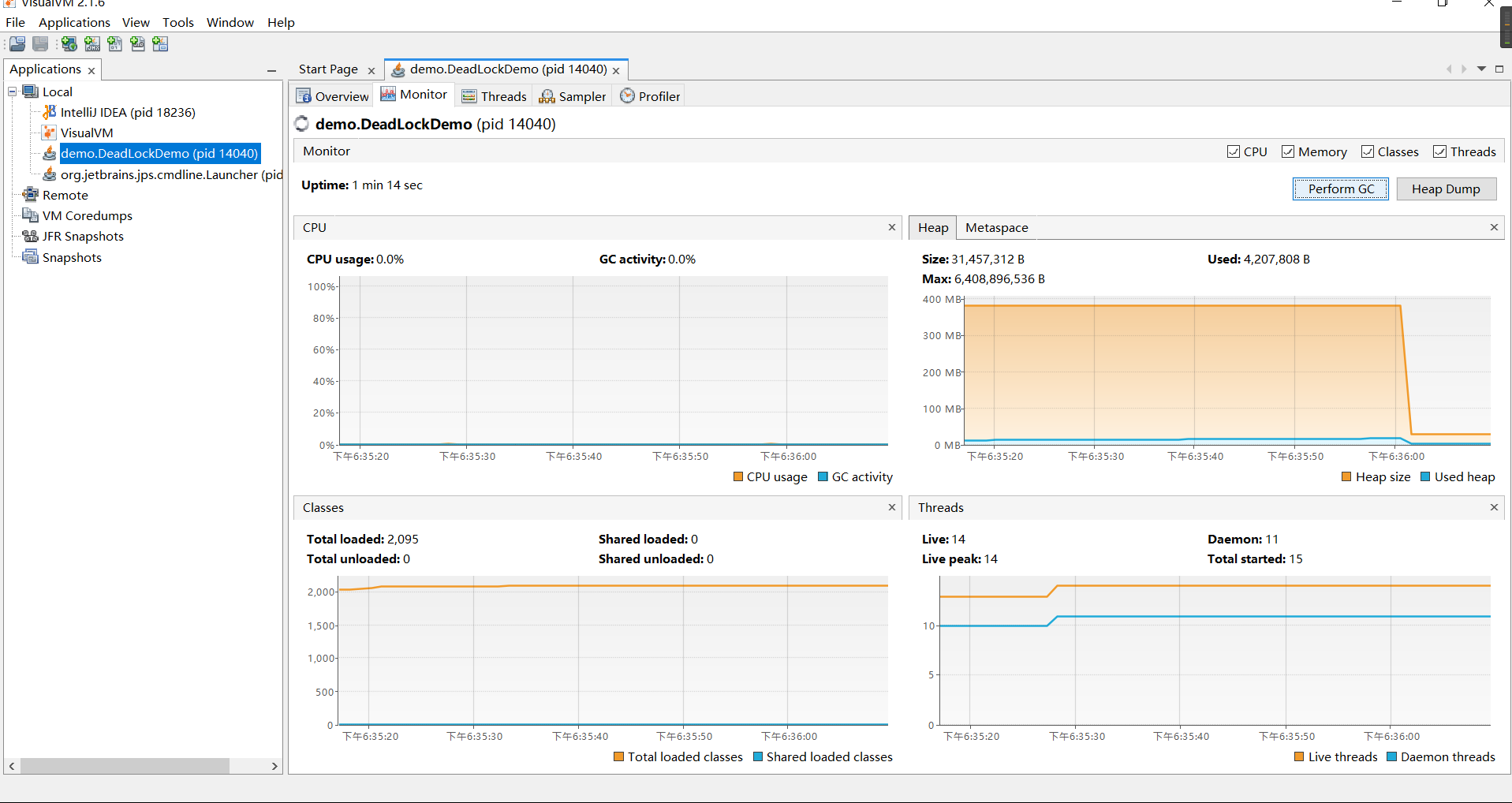
(3)visualvm示例:
在高版本JDK(大于1.8或后期更新的1.8版本)中已经不会再自动集成VisualVM,安装教程 。
堆转储后查看快照:
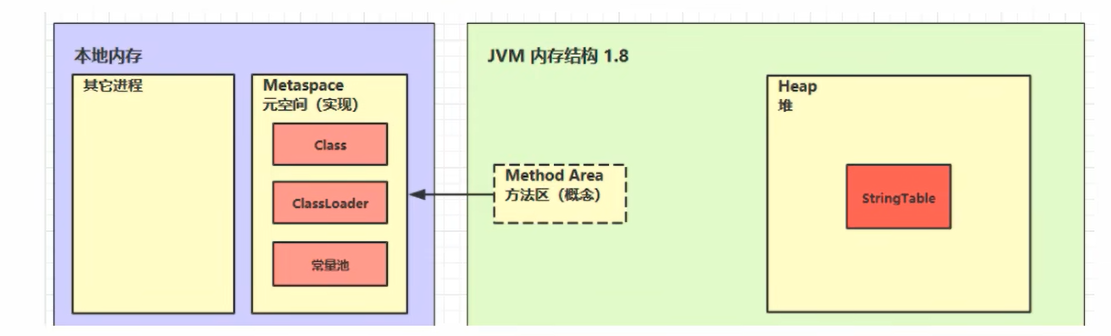
方法区 定义 方法去(Method Area)是各个线程共享的内存区域,用于存储已经被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它有一个别名“非堆”(Non-Heap),目的是与Java堆区分开来。OutOfMemoryError异常。
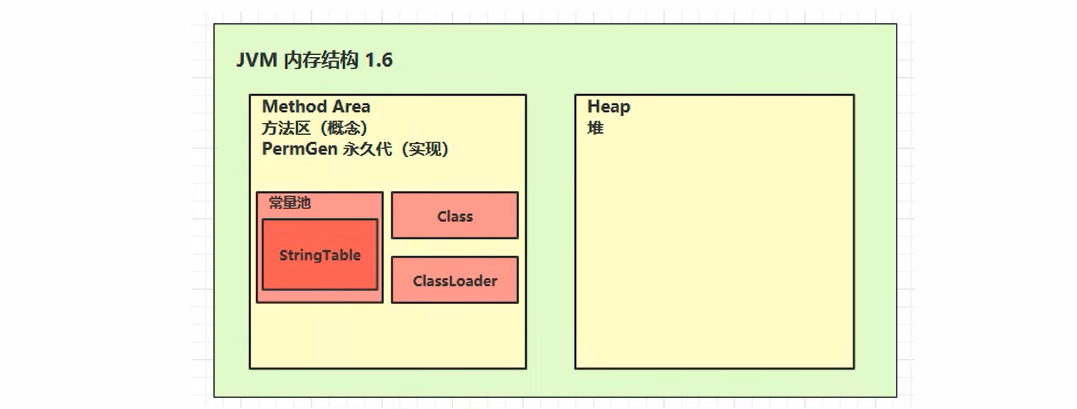
方法区内存溢出 (1)1.8以前会导致永久代内存溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package demo;import org.objectweb.asm.ClassWriter;import org.objectweb.asm.Opcodes;public class MethodAreaDemo extends ClassLoader { public static void main (String[] args) { int j = 0 ; try { MethodAreaDemo test = new MethodAreaDemo (); for (int i = 0 ; i < 1000000 ; i++, j++) { ClassWriter cw = new ClassWriter (0 ); cw.visit(Opcodes.V1_7, Opcodes.ACC_PUBLIC, "Class" +i, null , "java/lang/Object" , null ); byte [] code = cw.toByteArray(); test.defineClass("Class" +i, code,0 ,code.length); } } finally { System.out.println(j); } } }
报错信息:
场景:动态代理cglib
运行时常量池 定义:
常量池:就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。
运行时常量池:常量池是*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
一段Java代码,运行之前首先需要被编译为二进制字节码,字节码文件中包含了:
源程序HelloWorld.java:
1 2 3 4 5 public class HelloWorld { public static void main (String[] args) { System.out.println("Hello, World!" ); } }
编译为HelloWorld.class文件后,通过javap工具反编译得到字节码文件:
javap -v HelloWorld.class,-v显示详细信息
得到的字节码文件如下,其中Constant pool就是常量池:
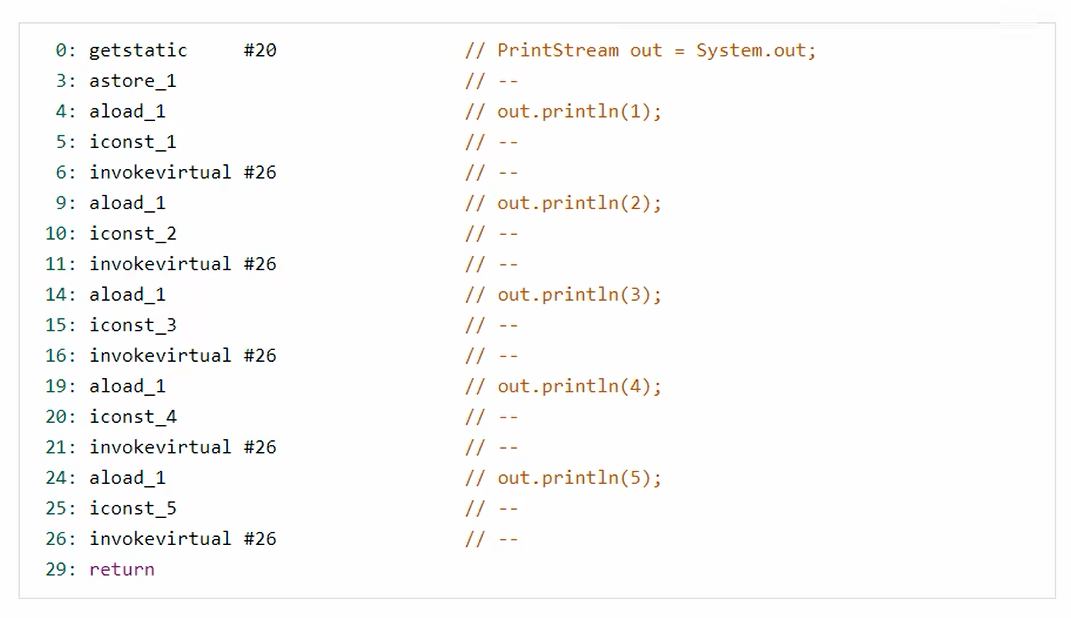
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 Classfile ../../HelloWorld.class Last modified 2023 年7 月23 日; size 535 bytes MD5 checksum 1b9cb5cc3bac2e04d2cb911d0dc1c0f7 Compiled from "HelloWorld.java" public class HelloWorld minor version: 0 major version: 55 flags: (0x0021 ) ACC_PUBLIC, ACC_SUPER this_class: #5 super_class: #6 interfaces: 0 , fields: 0 , methods: 2 , attributes: 1 Constant pool: #1 = Methodref #6. #20 #2 = Fieldref #21. #22 #3 = String #23 #4 = Methodref #24. #25 #5 = Class #26 #6 = Class #27 #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 LHelloWorld; #14 = Utf8 main #15 = Utf8 ([Ljava/lang/String;)V #16 = Utf8 args #17 = Utf8 [Ljava/lang/String; #18 = Utf8 SourceFile #19 = Utf8 HelloWorld.java #20 = NameAndType #7 :#8 #21 = Class #28 #22 = NameAndType #29 :#30 #23 = Utf8 Hello, World! #24 = Class #31 #25 = NameAndType #32 :#33 #26 = Utf8 HelloWorld #27 = Utf8 java/lang/Object #28 = Utf8 java/lang/System #29 = Utf8 out #30 = Utf8 Ljava/io/PrintStream; #31 = Utf8 java/io/PrintStream #32 = Utf8 println #33 = Utf8 (Ljava/lang/String;)V { public HelloWorld () ; descriptor: ()V flags: (0x0001 ) ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : invokespecial #1 4 : return LineNumberTable: LocalVariableTable: 0 5 0 this LHelloWorld; public static void main (java.lang.String[]) ; descriptor: ([Ljava/lang/String;)V flags: (0x0009 ) ACC_PUBLIC, ACC_STATIC Code: stack=2 , locals=1 , args_size=1 0 : getstatic #2 3 : ldc #3 5 : invokevirtual #4 8 : return LineNumberTable: line 3 : 0 line 4 : 8 LocalVariableTable: Start Length Slot Name Signature 0 9 0 args [Ljava/lang/String; } SourceFile: "HelloWorld.java"
真正CPU执行的指令为:
1 2 3 4 0 : getstatic #2 3 : ldc #3 5 : invokevirtual #4 8 : return
常量池的作用就是给指令提供常量符号。
StringTable相关知识
常量池中的字符串仅仅是符号,第一次用到时才变为对象
利用串池的机制,来避免重复创建字符串对象
字符串变量拼接的原理是StringBuilder(1.8)
字符串常量拼接的原理是编译器优化
可以使用intern方法,主动将串池中还没有的字符串对象放入串池。
JDK1.8,将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池。最后会把串池的对象返回。
JDK1.6,将这个字符串对象尝试放入串池,如果有则不会放入,如果没有则会把此对象复制一份,放入串池。最后会把串池的对象返回。
StringTable位置:
定义
针对以下代码:
1 2 3 4 5 6 7 8 public class StringTableDemo { public static void main (String[] args) { String s1 = "a" ; String s2 = "b" ; String s3 = "ab" ; } }
编译为.class文件后,通过javap -v StringTableDemo.class反编译为字节码文件,得到下面的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 Classfile /C:/Users/chao/Desktop/Java_Perf/Demo/JVMSDemo/out/production/JVMSDemo/ StringTableDemo.class Last modified 2023 年7 月24 日; size 497 bytes MD5 checksum 952ed13c07628966f743dde2f3bf8782 Compiled from "StringTableDemo.java" public class StringTableDemo minor version: 0 major version: 55 flags: (0x0021 ) ACC_PUBLIC, ACC_SUPER this_class: #5 super_class: #6 interfaces: 0 , fields: 0 , methods: 2 , attributes: 1 Constant pool: #1 = Methodref #6. #24 #2 = String #25 #3 = String #26 #4 = String #27 #5 = Class #28 #6 = Class #29 #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 LStringTableDemo; #14 = Utf8 main #15 = Utf8 ([Ljava/lang/String;)V #16 = Utf8 args #17 = Utf8 [Ljava/lang/String; #18 = Utf8 s1 #19 = Utf8 Ljava/lang/String; #20 = Utf8 s2 #21 = Utf8 s3 #22 = Utf8 SourceFile #23 = Utf8 StringTableDemo.java #24 = NameAndType #7 :#8 #25 = Utf8 a #26 = Utf8 b #27 = Utf8 ab #28 = Utf8 StringTableDemo #29 = Utf8 java/lang/Object { public StringTableDemo () ; descriptor: ()V flags: (0x0001 ) ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : invokespecial #1 :()V 4 : return LineNumberTable: line 1 : 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this LStringTableDemo; public static void main (java.lang.String[]) ; descriptor: ([Ljava/lang/String;)V flags: (0x0009 ) ACC_PUBLIC, ACC_STATIC Code: stack=1 , locals=4 , args_size=1 0 : ldc #2 2 : astore_1 3 : ldc #3 5 : astore_2 6 : ldc #4 8 : astore_3 9 : return LineNumberTable: line 4 : 0 line 5 : 3 line 6 : 6 line 7 : 9 LocalVariableTable: Start Length Slot Name Signature 0 10 0 args [Ljava/lang/String; 3 7 1 s1 Ljava/lang/String; 6 4 2 s2 Ljava/lang/String; 9 1 3 s3 Ljava/lang/String; } SourceFile: "StringTableDemo.java"
LocalVariableTable:main方法栈帧中的局部变量。ldc #2会把 a 符号变为 “a” 字符串对象,然后,会以 a 符号为键,将字符串对象存入一个串池StringTable中。ldc #3会把 b 符号变为 “b” 字符串对象,然后,如果StringTable中不存在 b 符号,则会以 b 符号为键,将字符串对象存入一个串池StringTable中。
字符串变量拼接 然后,如果增加一个字符串对象拼接操作,会怎么样呢?
1 2 3 4 5 6 7 8 9 public class StringTableDemo { public static void main (String[] args) { String s1 = "a" ; String s2 = "b" ; String s3 = "ab" ; String s4 = s1 + s2; } }
注意,在jdk8和jdk11中的结果不同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 0 : ldc #2 2 : astore_13 : ldc #3 5 : astore_26 : ldc #4 8 : astore_39 : new #5 12 : dup13 : invokespecial #6 16 : aload_117 : invokevirtual #7 20 : aload_221 : invokevirtual #7 24 : invokevirtual #8 27 : astore 4 29 : return
逐行阅读,可以看出,String s4 = s1 + s2;这行字符串拼接操作的代码,实际上是创建了一个StringBuilder对象,然后执行append方法,即:
1 new StringBuilder ().append("a" ).append("b" ).toString();
String对象,在堆 中。
1 2 3 4 5 6 7 8 9 10 11 12 0 : ldc #2 2 : astore_13 : ldc #3 5 : astore_26 : ldc #4 8 : astore_39 : aload_110 : aload_211 : invokedynamic #5 , 0 16 : astore 4 18 : return
我们可以看到,JDK11用的是动态调用(InvokeDynamic),其实,从JDK9开始,字符串拼接操作就开始使用makeConcatWithConstants操作了。
invokestatic调用类方法(静态绑定,速度快)invokevirtual调用实例方法(动态绑定)invokespecial调用实例方法(静态绑定,速度快)invokeinterface调用引用类型为interface的实例方法(动态绑定)invokedynamicJDK 7引入的,主要是为了支持动态语言的方法调用
字符串常量拼接 如果是字符串常量拼接呢?
1 2 3 4 5 6 7 8 9 10 public class StringTableDemo { public static void main (String[] args) { String s1 = "a" ; String s2 = "b" ; String s3 = "ab" ; String s4 = s1 + s2; String s5 = "a" + "b" ; } }
String s5 = "a" + "b";这句代码,反编译结果为:
1 2 29 : ldc #4 31 : astore 5
所以,它其实是从串池中寻找字符串,所以s3==s5为true。对比 :
String s5 = "a" + "b",其实是javac在编译期间的优化,结果已经在编译期间确定为ab。String s4 = s1 + s2,s1和s2是变量,在运行时引用的值可能被修改,所以必须在运行期间动态拼接。
字符串延迟加载 一个测试demo,可以通过逐行调试的方式验证字符串的延迟加载机制。
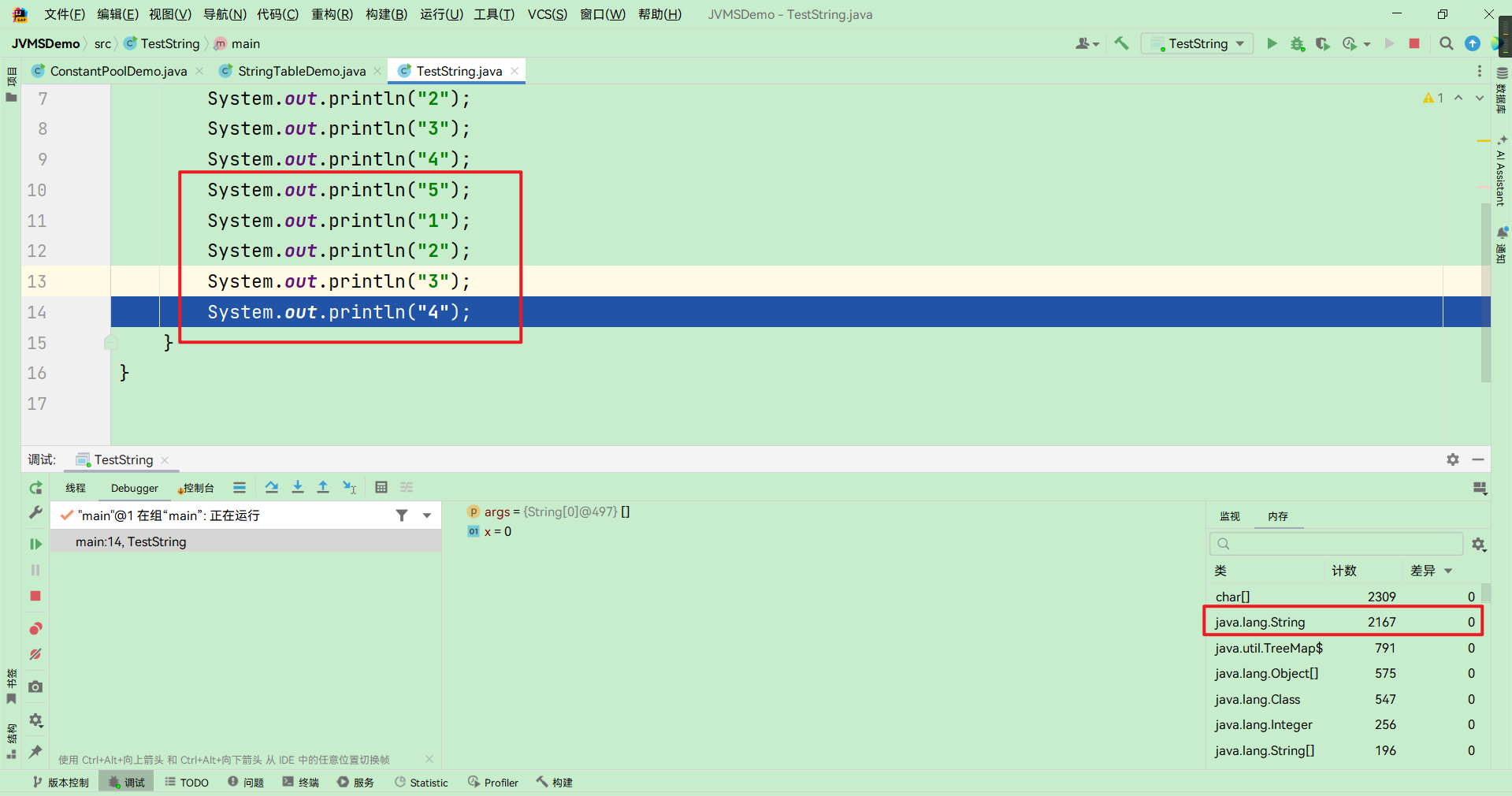
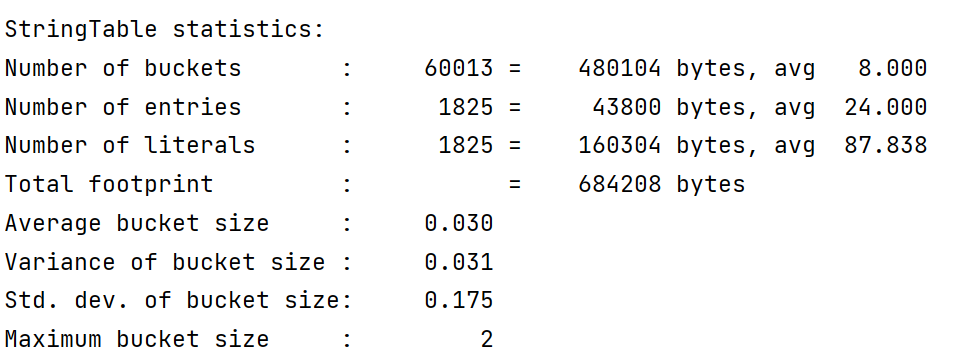
StringTable垃圾回收 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class StringTableGC { public static void main (String[] args) { int i = 0 ; try { } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } } }
运行之后,得到的结果:
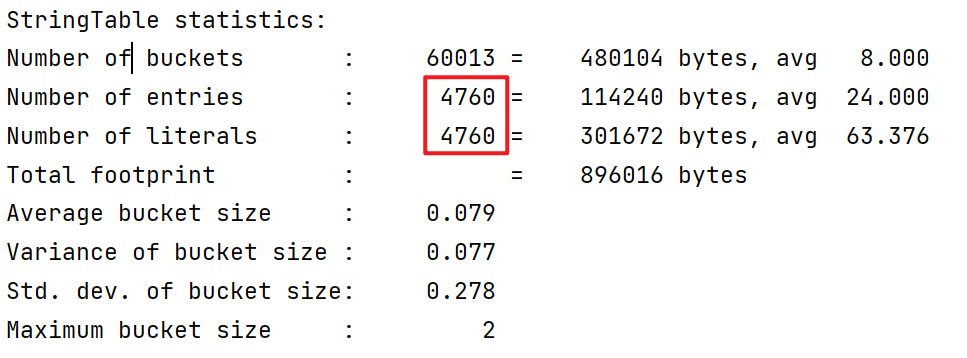
添加一段代码,向StringTable里面添加100个字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class StringTableGC { public static void main (String[] args) { int i = 0 ; try { for (int j = 0 ; j < 100 ; j++) { String.valueOf(j).intern(); i++; } } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } } }
结果为:(哈希表)j改为10000,添加10000个字符串,这个时候,发生了垃圾回收。首先看到entries和literals只有4760。
StringTable性能调优
调整-XX:StringTableSize=桶个数
考虑将字符串对象是否入池
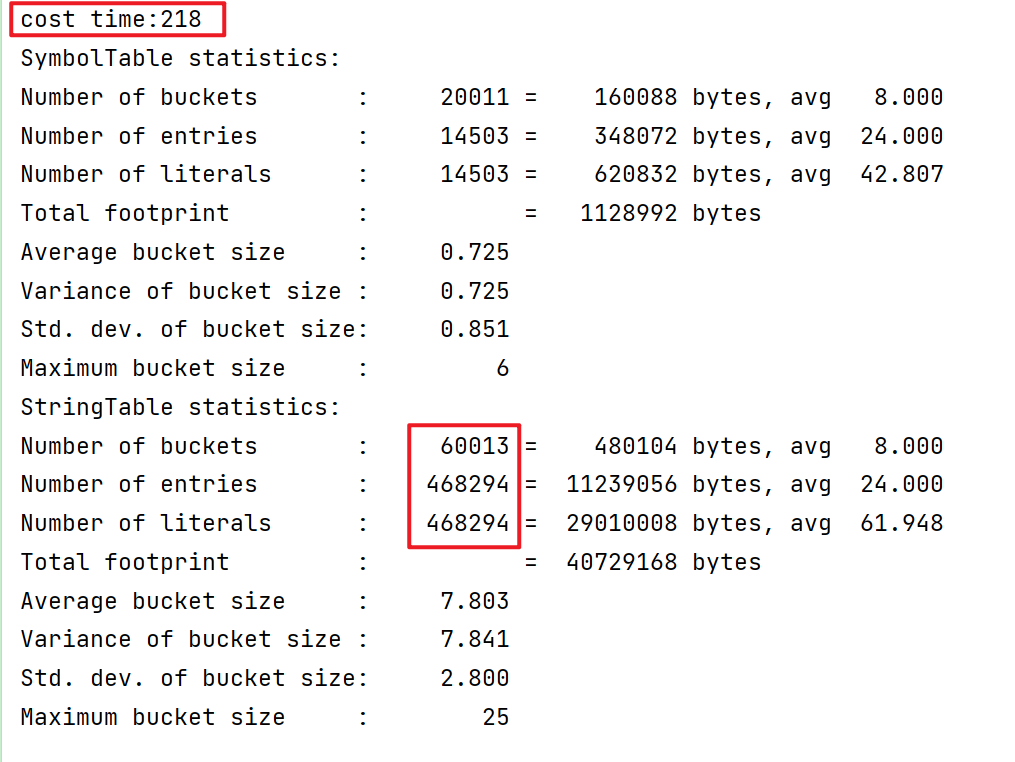
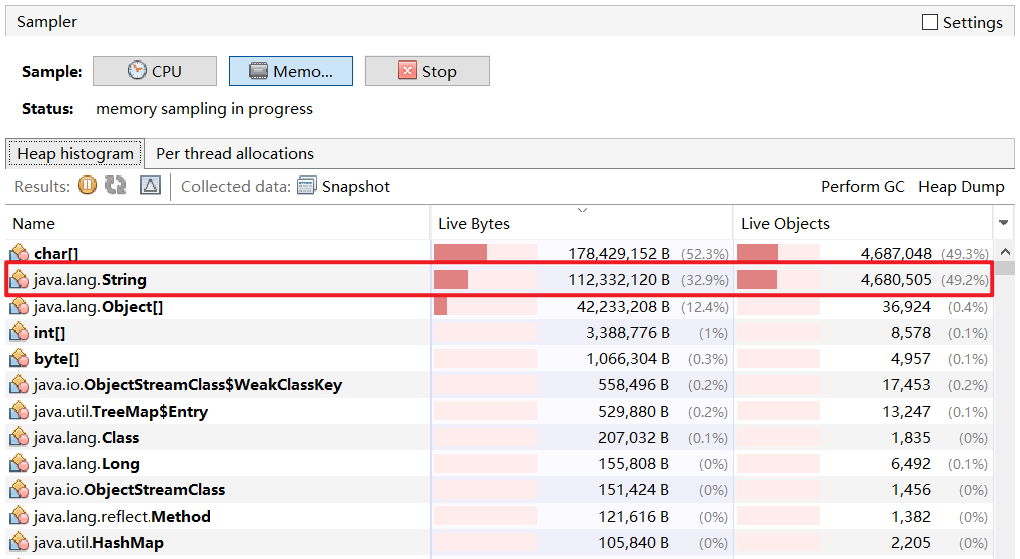
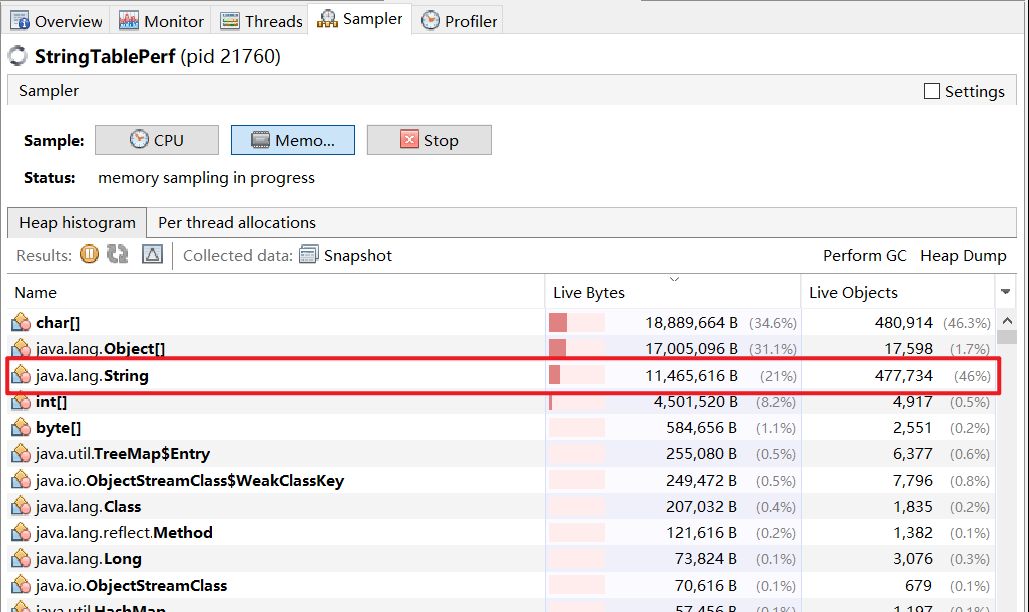
(1)调整桶的个数调整桶的个数 。下面的代码展示了不同大小的StringTableSize,耗费的时间差距,前者比后者慢18倍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import java.io.*;import java.nio.charset.StandardCharsets;import java.nio.file.Files;import java.nio.file.Paths;public class StringTablePerf { public static void main (String[] args) throws IOException { try (BufferedReader reader = new BufferedReader (new InputStreamReader ( Files.newInputStream(Paths.get("src/words.txt" + "" )), StandardCharsets.UTF_8))) { String line; long start = System.nanoTime(); while (true ) { line = reader.readLine(); if (line == null ) { break ; } line.intern(); } long costTime = (System.nanoTime() - start) / 1000000 ; System.out.println("cost time:" + costTime); } } }
intern方法后,内存占用显著下降。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import java.io.*;import java.nio.charset.StandardCharsets;import java.nio.file.Files;import java.nio.file.Paths;import java.util.ArrayList;import java.util.List;public class StringTablePerf { public static void main (String[] args) throws IOException { List<String> s = new ArrayList <>(); System.in.read(); for (int i = 0 ; i < 10 ; i++) { try (BufferedReader reader = new BufferedReader (new InputStreamReader ( Files.newInputStream(Paths.get("src/words.txt" + "" )), StandardCharsets.UTF_8))) { String line; long start = System.nanoTime(); while (true ) { line = reader.readLine(); if (line == null ) { break ; } s.add(line.intern()); } long costTime = (System.nanoTime() - start) / 1000000 ; System.out.println("cost time:" + costTime); } } System.in.read(); } }
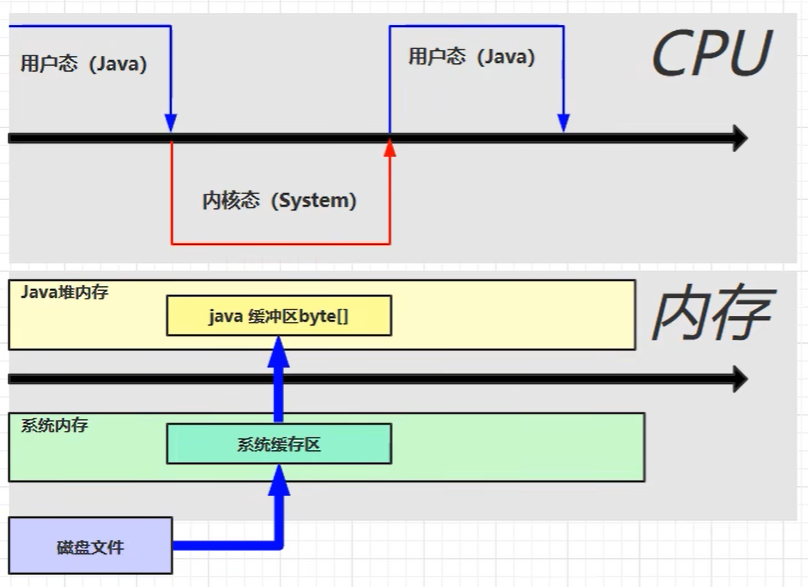
直接内存 定义 Direct Memory
常见于NIO操作时,用于数据缓冲区
分配回收成本较高,但读写性能高
不受JVM内存回收管理
结构
分配与回收直接内存
使用Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法
使用ByteBuffer操作内存:ByteBuffer的实现类内部,使用了Cleaner(虚引用)来监测ByteBuffer对象,一旦ByteBuffer被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存。
(1)使用ByteBuffer操作内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import java.nio.ByteBuffer;import java.util.ArrayList;import java.util.List;public class DirectMemoryDemo { static int _100Mb = 1024 * 1024 * 100 ; public static void main (String[] args) { List<ByteBuffer> list = new ArrayList <>(); int i = 0 ; try { while (true ) { ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb); list.add(byteBuffer); i++; } } finally { System.out.println(i); } } }
Unsafe对象的方法操作直接内存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import sun.misc.Unsafe;import java.lang.reflect.Field;public class DirectMemoryOOM { private static final int _1GB = 1024 * 1024 * 1024 ; public static void main (String[] args) throws Exception { Field unsafeField = Unsafe.class.getDeclaredFields()[0 ]; unsafeField.setAccessible(true ); Unsafe unsafe = (Unsafe) unsafeField.get(null ); long base = unsafe.allocateMemory(_1GB); unsafe.setMemory(base, _1GB, (byte ) 0 ); System.in.read(); unsafe.freeMemory(base); System.in.read(); } }
注意!!!ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);allocateDirect调用DirectByteBuffer方法。DirectByteBuffer的源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 DirectByteBuffer(int cap) { super (-1 , 0 , cap, cap); boolean pa = VM.isDirectMemoryPageAligned(); int ps = Bits.pageSize(); long size = Math.max(1L , (long )cap + (pa ? ps : 0 )); Bits.reserveMemory(size, cap); long base = 0 ; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte ) 0 ); if (pa && (base % ps != 0 )) { address = base + ps - (base & (ps - 1 )); } else { address = base; } cleaner = Cleaner.create(this , new Deallocator (base, size, cap)); att = null ; }
其实,最终还是调用了unsafe的方法:base = unsafe.allocateMemory(size);**cleaner**对象,创建的时候传入了一个对象new Deallocator,我们继续深入来看Deallocator的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private static class Deallocator implements Runnable { private static Unsafe unsafe = Unsafe.getUnsafe(); private long address; private long size; private int capacity; private Deallocator (long address, long size, int capacity) { assert (address != 0 ); this .address = address; this .size = size; this .capacity = capacity; } public void run () { if (address == 0 ) { return ; } unsafe.freeMemory(address); address = 0 ; Bits.unreserveMemory(size, capacity); } }
终于,我们在里面发现了unsafe.freeMemory方法。最终,其实还是通过unsafe方法进行内存回收。Deallocator类实现了Runnable接口,是一个回调方法,在创建cleaner的时候通过下面代码被关联:cleaner = Cleaner.create(this, new Deallocator(base, size, cap));this指的是**DirectByteBuffer**,所以当**DirectByteBuffer**对象被回收的时候,就会回调Deallocator对象中的run方法,从而执行垃圾回收方法 unsafe.freeMemory。
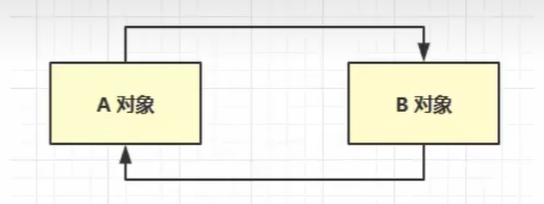
垃圾回收 如何判断对象可以回收 引用计数法 在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为 0 的对象都是不可能再被使用的。但是引用计数法面对循环引用的情况无法正确工作 。
可达性分析算法
Java虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象。
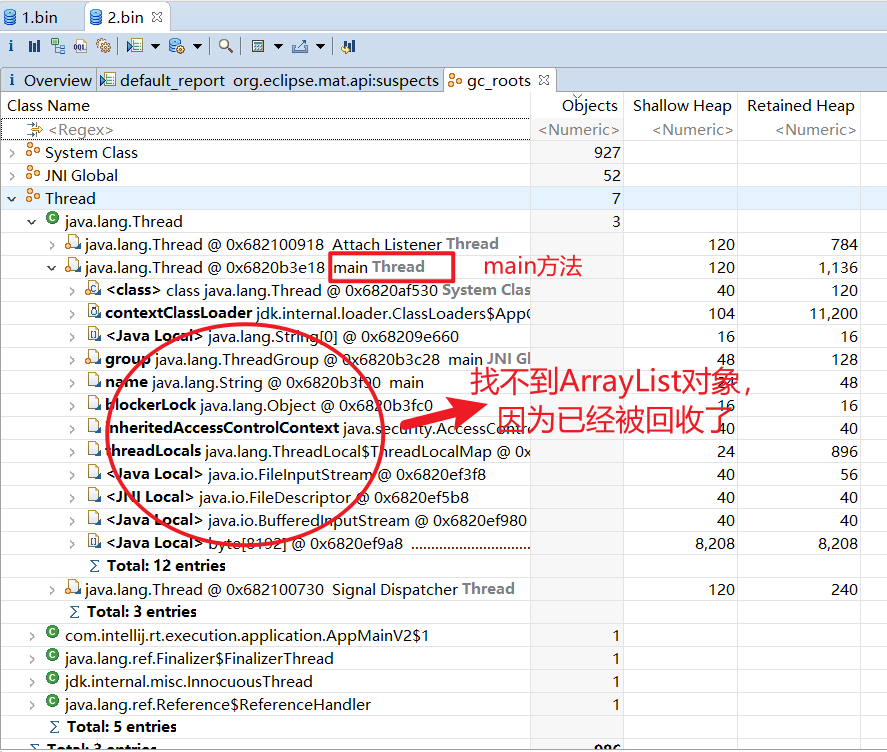
扫描堆中的对象,看是否能够沿着GC Root对象为起点的引用链找到该对象,找不到,表示可以回收。
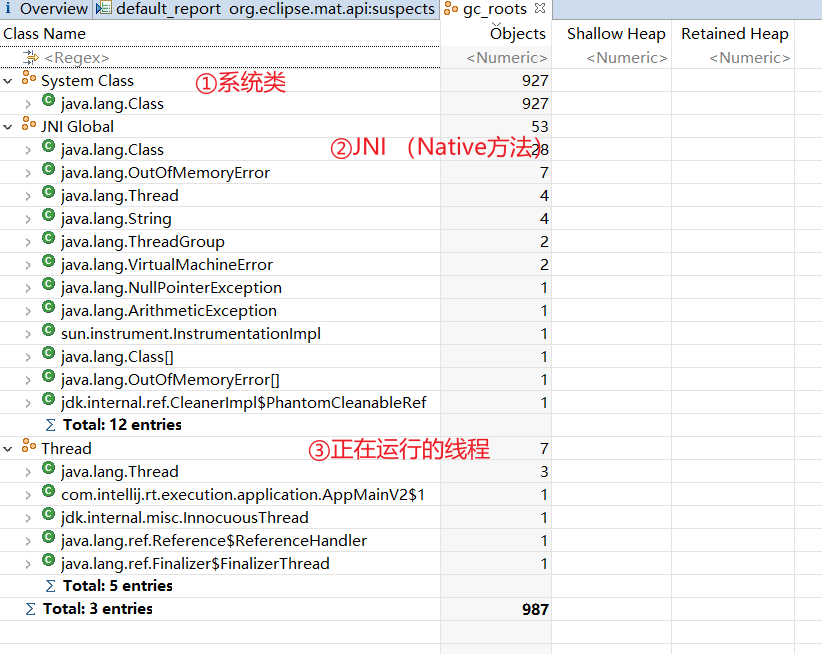
哪些对象可以作为GC Root?
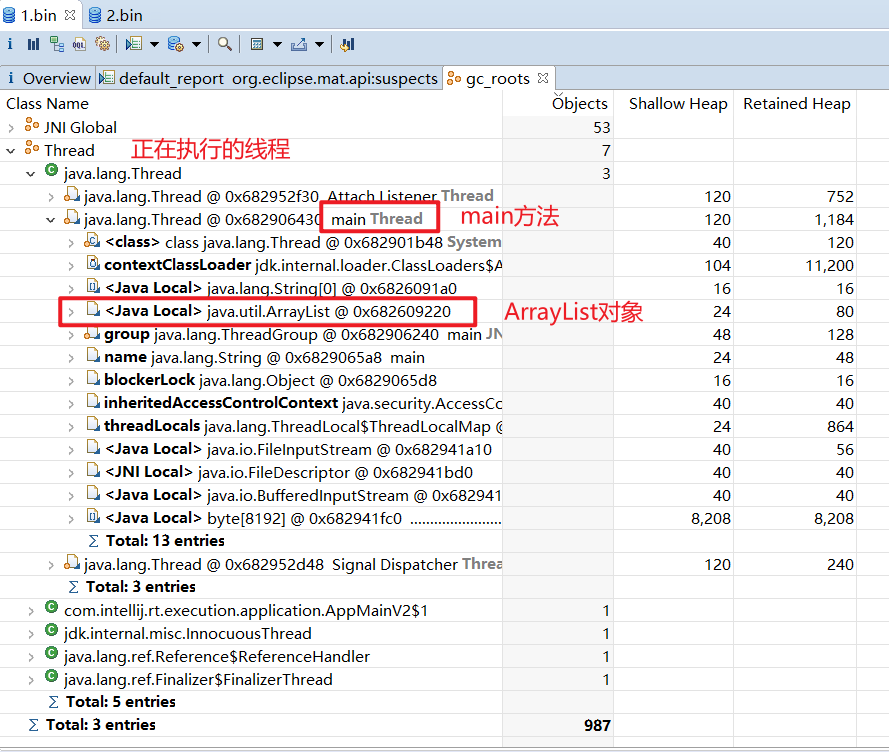
在虚拟机栈(栈帧中的本地变量表)中引用的对象,比如当前正在运行的方法所使用到的参数、局部变量、临时变量。
在方法区中类静态属性引用的对象,比如Java类的引用类型静态变量
在方法区中常量引用的对象,比如字符串常量池里的引用。
在本地方法栈中(即Native方法)引用的对象。
Java虚拟机内部的引用,比如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointerException,OutOfMemoryError)等,还有系统类加载器。
所有被同步锁(synchronized关键字)持有的对象。
反映Java虚拟机内部情况的JMXBean,JVMTI中注册的回调、本地代码缓存等。
代码演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package gc;import java.io.IOException;import java.util.ArrayList;import java.util.List;public class GCRootDemo { public static void main (String[] args) throws IOException { List<Object> list = new ArrayList <>(); list.add("a" ); list.add("b" ); System.out.println(1 ); System.in.read(); list = null ; System.out.println(2 ); System.in.read(); System.out.println("end..." ); } }
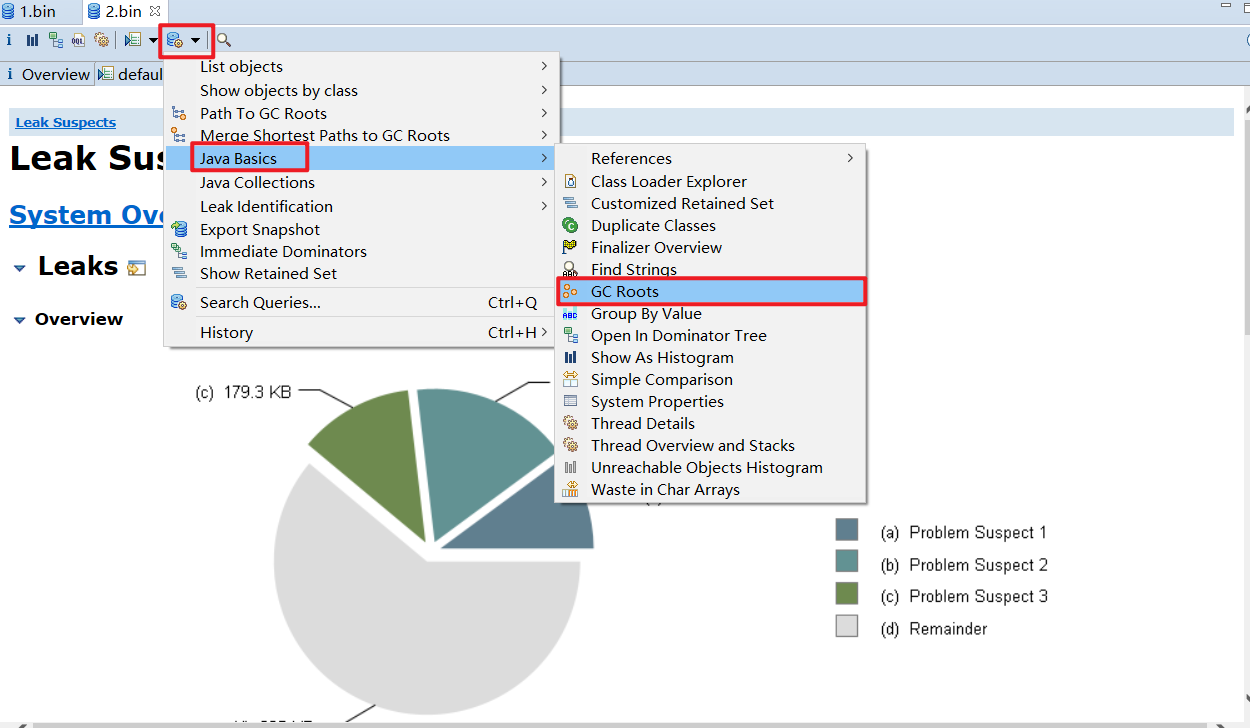
1 2 jps # 获取进程ID jmap -dump:format=b,live,file=1. bin 进程ID
然后,使用 EclipseMemory Analyzer 工具分析堆转储文件(虽然IDEA自带的Profiler也能分析,但是功能较少)。
五种引用 概念
强引用(Strongly Reference)
只有所有GC Roots对象都不通过【强引用】引用该对象,该对象才能被垃圾回收。
软引用(Soft Reference)
仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次发出垃圾回收,回收软引用对象。
可以配合引用队列来释放软引用自身。
弱引用(Weak Reference)
仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足,都会回收弱引用对象。
可以配合引用队列来释放弱引用自身。
虚引用(Phantom Reference)
必须配合引用队列使用,主要配合 ByteBuffer 使用,被引用对象回收时,会将虚引用入队,由Reference Handler线程调用虚引用相关方法释放直接内存。
终结器引用(Final Reference)
无需手动编码,需要配合引用队列使用。在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由Finalizer线程通过终结器引用找到被引用对象并调用它的finalize方法,第二次GC时才能回收被引用对象。
软引用示例 (1)正常情况下的强引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package gc;import java.io.IOException;import java.util.ArrayList;import java.util.List;public class SoftReferenceDemo { private static final int _4MB = 4 * 1024 * 1024 ; public static void main (String[] args) throws IOException { List<byte []> list = new ArrayList <>(); for (int i = 0 ; i < 5 ; i++) { list.add(new byte [_4MB]); } System.in.read(); } }
结果如下:
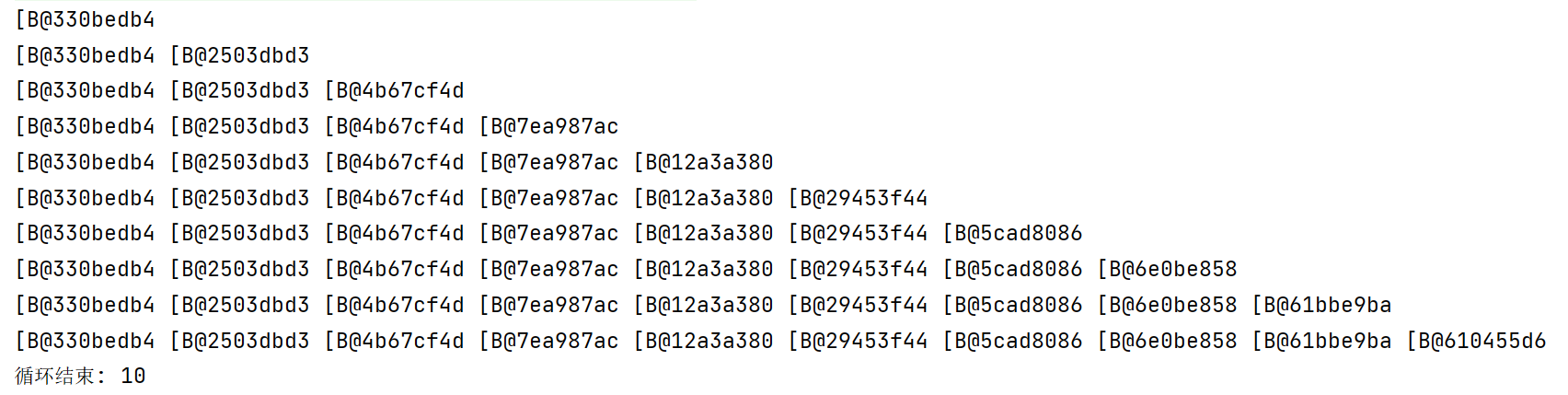
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package gc;import java.io.IOException;import java.lang.ref.SoftReference;import java.util.ArrayList;import java.util.List;public class SoftReferenceDemo { private static final int _4MB = 4 * 1024 * 1024 ; public static void main (String[] args) throws IOException { List<SoftReference<byte []>> list = new ArrayList <>(); for (int i = 0 ; i < 5 ; i++) { SoftReference<byte []> ref = new SoftReference <>(new byte [_4MB]); printArr(list); list.add(ref); System.out.println(list.size()); } System.out.println("循环结束: " + list.size()); printArr(list); } private static void printArr (List<SoftReference<byte []>> list) { for (SoftReference<byte []> ref : list) { System.out.print(ref.get() + ", " ); } System.out.println(); } }
结果如下:
清除无用的软引用 手动创建引用队列ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
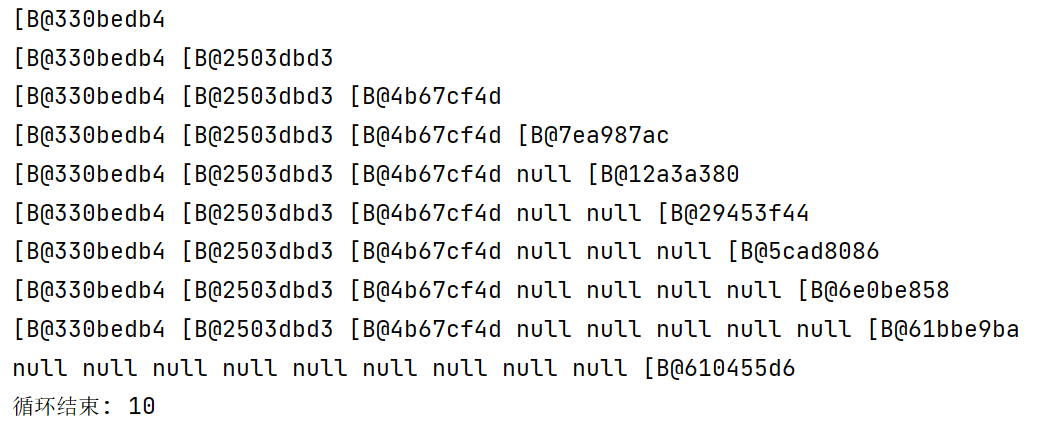
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package gc;import java.io.IOException;import java.lang.ref.Reference;import java.lang.ref.ReferenceQueue;import java.lang.ref.SoftReference;import java.util.ArrayList;import java.util.List;public class SoftReferenceDemo { private static final int _4MB = 4 * 1024 * 1024 ; public static void main (String[] args) throws IOException { List<SoftReference<byte []>> list = new ArrayList <>(); ReferenceQueue<byte []> queue = new ReferenceQueue <>(); for (int i = 0 ; i < 5 ; i++) { SoftReference<byte []> ref = new SoftReference <>(new byte [_4MB], queue); printArr(list); list.add(ref); System.out.println(list.size()); } Reference<? extends byte []> poll = queue.poll(); while (poll != null ) { list.remove(poll); poll = queue.poll(); } System.out.println("循环结束: " + list.size()); printArr(list); } private static void printArr (List<SoftReference<byte []>> list) { for (SoftReference<byte []> ref : list) { System.out.print(ref.get() + ", " ); } System.out.println(); } }
弱引用示例 下面是示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package gc;import java.lang.ref.WeakReference;import java.util.ArrayList;import java.util.List;public class WeakReferenceDemo { private static final int _4MB = 4 * 1024 * 1024 ; public static void main (String[] args) { List<WeakReference<byte []>> list = new ArrayList <>(); for (int i = 0 ; i < 10 ; i++) { WeakReference<byte []> ref = new WeakReference <>(new byte [_4MB]); list.add(ref); for (WeakReference<byte []> w : list) { System.out.print(w.get() + " " ); } System.out.println(); } System.out.println("循环结束: " + list.size()); } }
(1)首先,我们来看一下,在内存充足的情况下,运行结果:
垃圾回收算法 标记清除 Mark Sweep
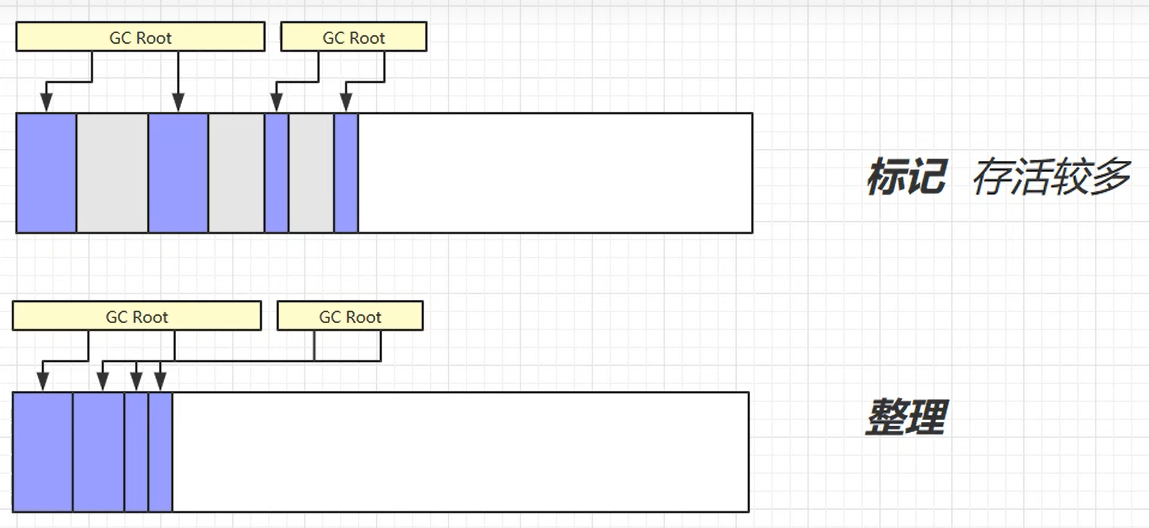
标记整理 Mark Compact
优点:没有内存碎片。
缺点:整理涉及到对象的移动,效率较低。
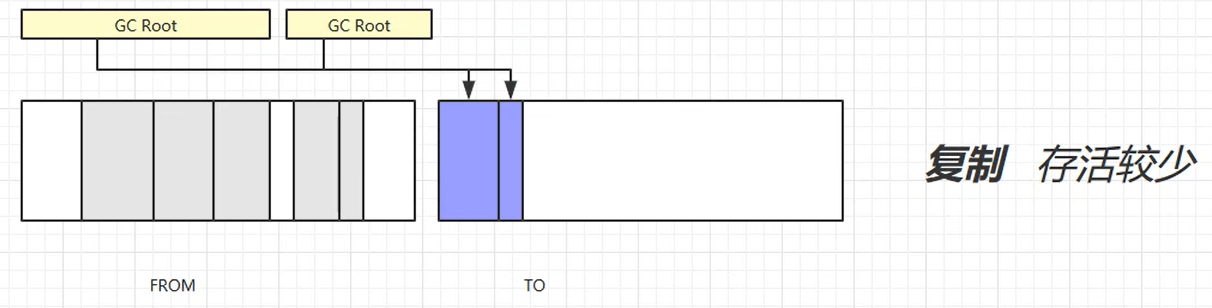
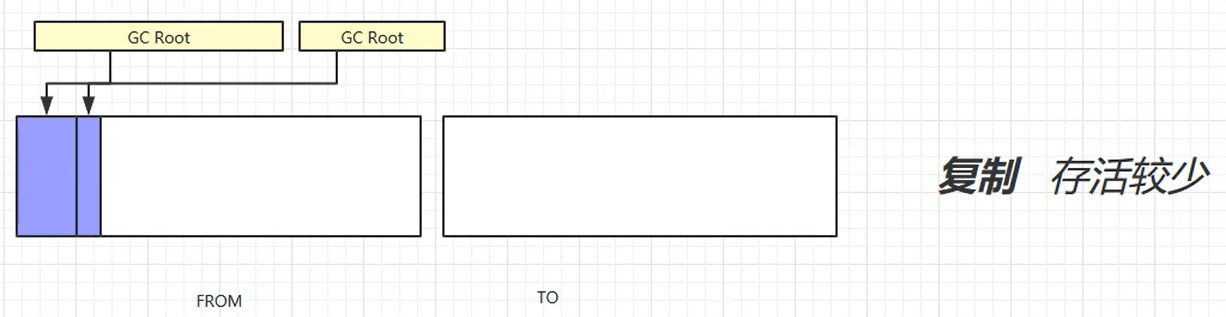
标记复制
优点:不会产生内存碎片
缺点:需要占用双倍内存空间
分代垃圾回收 概念
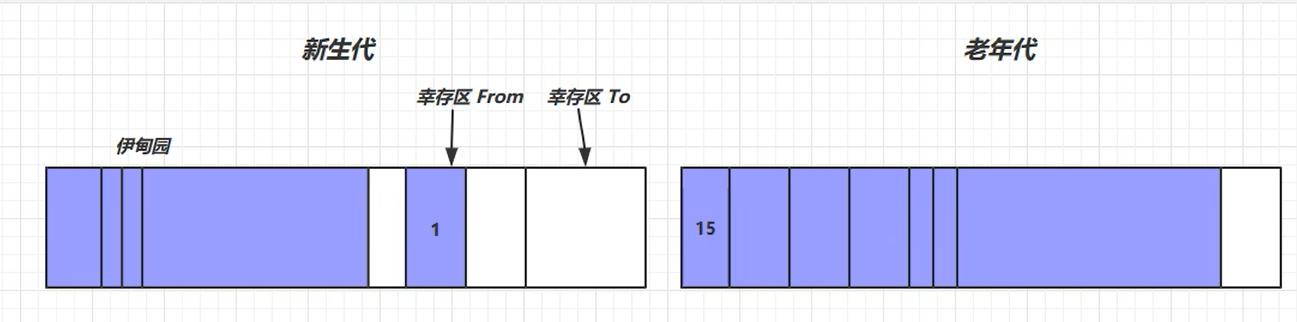
对象首先分配在伊甸园区域
新生代空间不足时,触发minor gc,伊甸园和 from 存活的对象使用复制算法复制到to中,存活的对象年龄加1,并且交换 from 和 to 。
minor gc 会引发一次 stop the world (STW) ,暂停其他用户的线程,等垃圾回收结束,用户线程才恢复运行。因为新生代大部分都是垃圾,需要复制存活的对象很少 ,所以暂停时间并不长。
当对象寿命超过阈值时,会晋升至老年代,最大寿命是15次(存储寿命的位置只有4个 bit)
当老年代空间不足,会先尝试触发一次minor gc,如果之后空间仍不足,那么触发full gc,STW时间更长。
如果full gc之后,老年代空间仍然不足,则触发OutOfMemoryError:Java heap space。
相关VM参数
含义
参数
堆初始大小
-Xms
堆最大大小
-Xmx或-XX:MaxHeapSize=size
新生代大小
-Xmn或(-XX:NewSize=size + -XX:MaxNewSize=size)
幸存区比例(动态)
-XX:InitialSurvivorRatio=ratio和-XX:UseAdaptiveSizePolicy
幸存区比例
-XX:SurvivorRatio=ratio
晋升阈值
-XX:MaxTenuringThreshold=threshold
晋升详情
-XX:+PrintTenuringDistribution
GC详情
-XX:+PrintGCDetails -verbose:gc
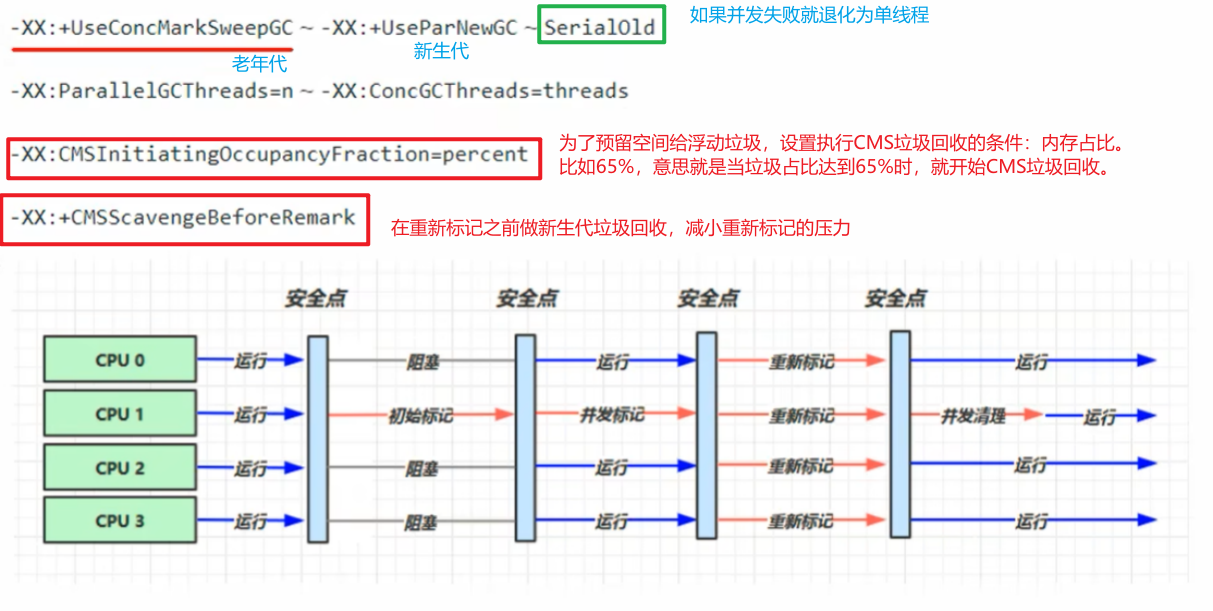
FullGC前MinorGC
-XX:ScavengeBeforeFullGC
GC分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package gc;public class GCDemo { private static final int _512KB = 512 * 1024 ; private static final int _1MB = 1024 * 1024 ; private static final int _6MB = 6 * 1024 * 1024 ; private static final int _7MB = 7 * 1024 * 1024 ; private static final int _8MB = 8 * 1024 * 1024 ; public static void main (String[] args) { } }
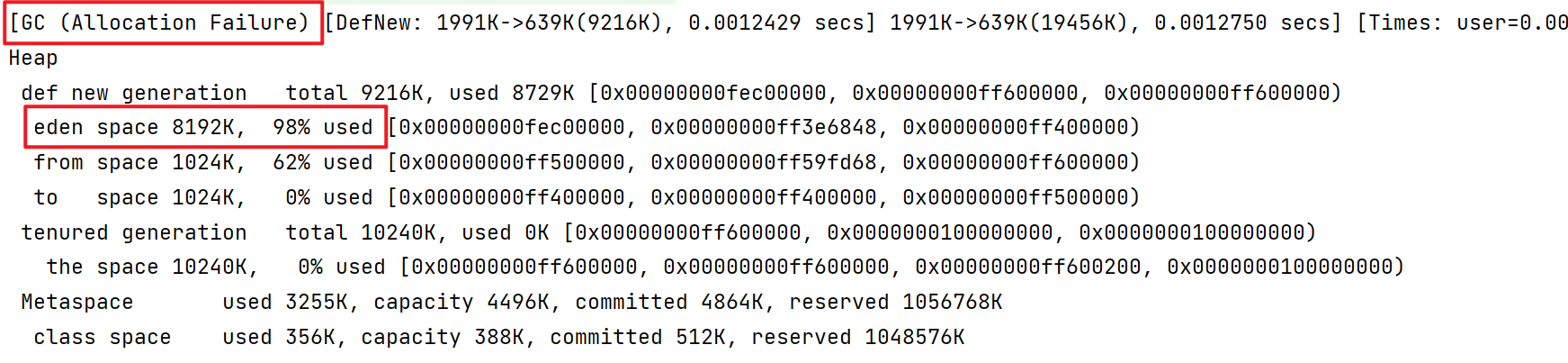
首先,在main方法中没有任何语句,运行上述示例代码,查看控制台输出的信息:
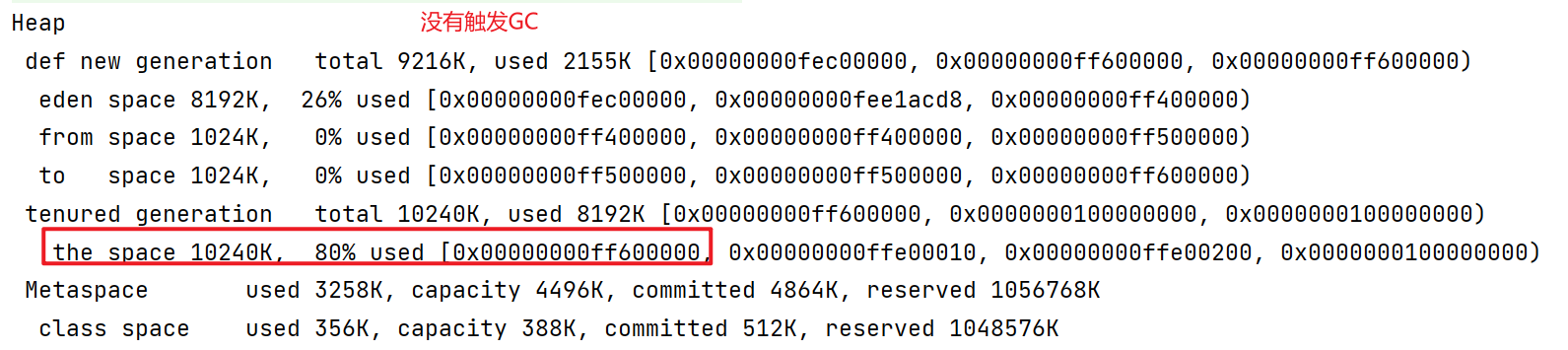
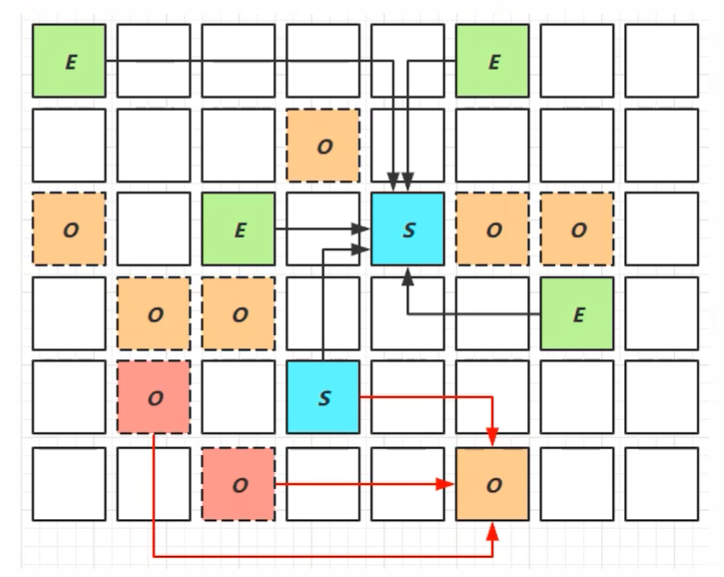
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package gc;import java.util.ArrayList;public class GCDemo { private static final int _512KB = 512 * 1024 ; private static final int _1MB = 1024 * 1024 ; private static final int _6MB = 6 * 1024 * 1024 ; private static final int _7MB = 7 * 1024 * 1024 ; private static final int _8MB = 8 * 1024 * 1024 ; public static void main (String[] args) { ArrayList<byte []> list = new ArrayList <>(); list.add(new byte [_7MB]); } }
由于一开始伊甸园就占用了24%的空间,剩下8192K*(1-24%)=6225.92K,不够7MB,所以触发一次GC。在GC过程中,将伊甸园区域内的一些对象复制到了to区域,然后和from区域互换。在这之后,可以看到,伊甸园区域占用92%,from区域占用62%。from内存区域的结束地址,是to内存区域的开始地址。而现在正好反过来了,所以也就证明了from和to互换了(当然只是互换了引用)。
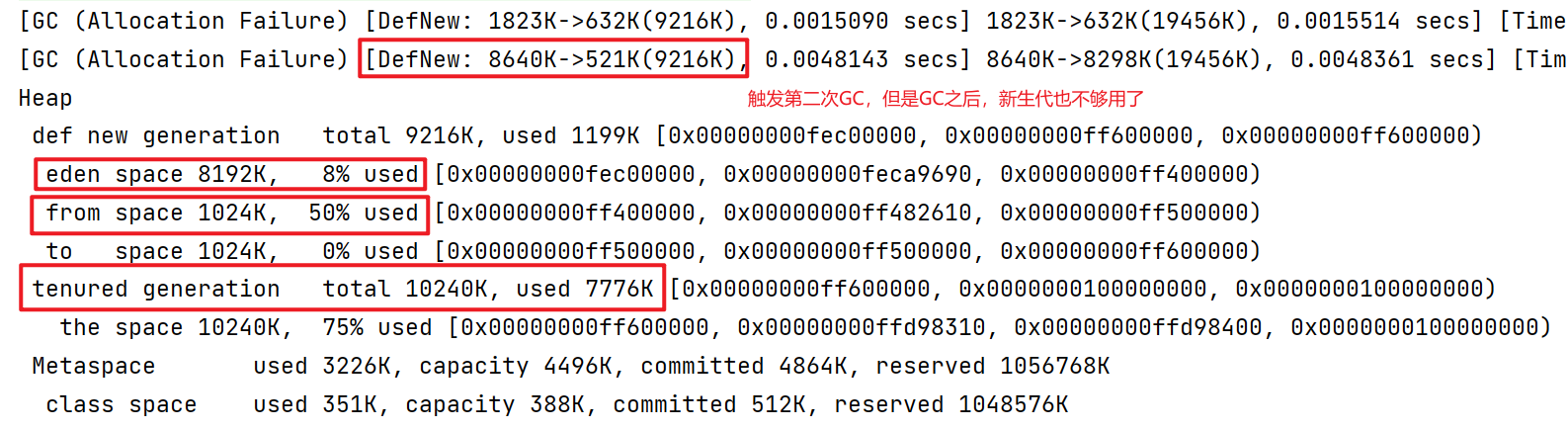
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package gc;import java.util.ArrayList;public class GCDemo { private static final int _512KB = 512 * 1024 ; private static final int _1MB = 1024 * 1024 ; private static final int _6MB = 6 * 1024 * 1024 ; private static final int _7MB = 7 * 1024 * 1024 ; private static final int _8MB = 8 * 1024 * 1024 ; public static void main (String[] args) { ArrayList<byte []> list = new ArrayList <>(); list.add(new byte [_7MB]); list.add(new byte [_512KB]); } }
如上所示,新增了一个512K的内存占用,结果如下,仍然只触发了一次GC,但是伊甸园的空间达到了**98%**,马上要满了。512K的内存占用,运行代码,得到如下结果:
大对象直接晋升老年代 如果一个大对象,新生代根本放不下去,就会直接晋升老年代,不会触发GC。下面的代码示例说明了这个问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package gc;import java.util.ArrayList;public class GCDemo { private static final int _512KB = 512 * 1024 ; private static final int _1MB = 1024 * 1024 ; private static final int _6MB = 6 * 1024 * 1024 ; private static final int _7MB = 7 * 1024 * 1024 ; private static final int _8MB = 8 * 1024 * 1024 ; public static void main (String[] args) { ArrayList<byte []> list = new ArrayList <>(); list.add(new byte [_8MB]); } }
运行结果如下:
内存溢出 如果新生代没有空间,老年代也没有空间了,就会触发OutOfMemoryError报错。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package gc;import java.util.ArrayList;public class GCDemo { private static final int _512KB = 512 * 1024 ; private static final int _1MB = 1024 * 1024 ; private static final int _6MB = 6 * 1024 * 1024 ; private static final int _7MB = 7 * 1024 * 1024 ; private static final int _8MB = 8 * 1024 * 1024 ; public static void main (String[] args) { ArrayList<byte []> list = new ArrayList <>(); list.add(new byte [_8MB]); list.add(new byte [_8MB]); } }
运行结果如下:
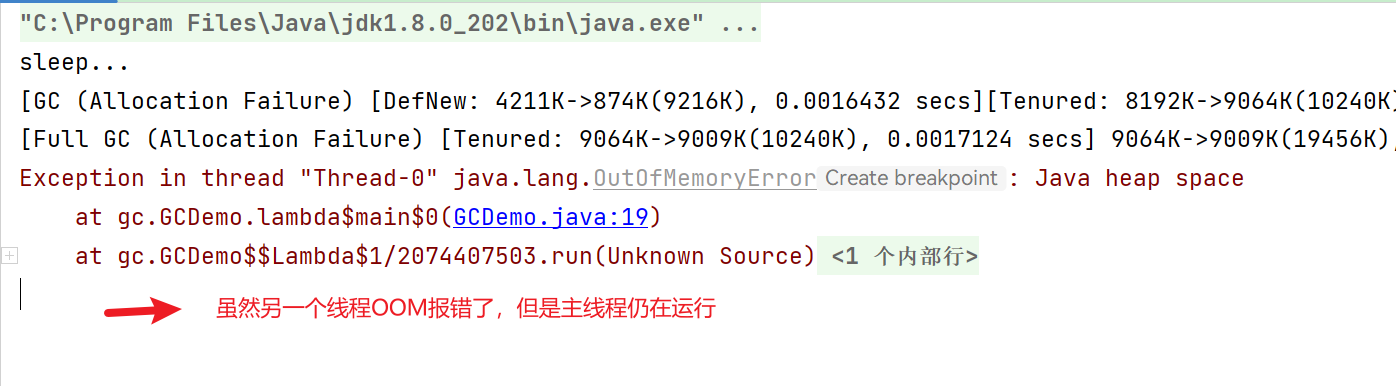
线程内存溢出 多线程内存溢出,不会影响主线程。示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package gc;import java.util.ArrayList;public class GCDemo { private static final int _512KB = 512 * 1024 ; private static final int _1MB = 1024 * 1024 ; private static final int _6MB = 6 * 1024 * 1024 ; private static final int _7MB = 7 * 1024 * 1024 ; private static final int _8MB = 8 * 1024 * 1024 ; public static void main (String[] args) throws InterruptedException { new Thread (() -> { ArrayList<byte []> list = new ArrayList <>(); list.add(new byte [_8MB]); list.add(new byte [_8MB]); }).start(); System.out.println("sleep..." ); Thread.sleep(10000000L ); } }
运行结果:
垃圾回收器
串行
吞吐量优先
多线程
堆内存较大,多核CPU
目标:让单位时间内,SEW的时间最短
响应时间优先
多线程
堆内存较大,多核CPU
目标:尽可能让单次STW的时间最短
比如一个小时内
吞吐量优先:0.2 + 0.2 = 0.4
响应时间优先:0.1 + 0.1 + 0.1 + 0.1 + 0.1 = 0.5
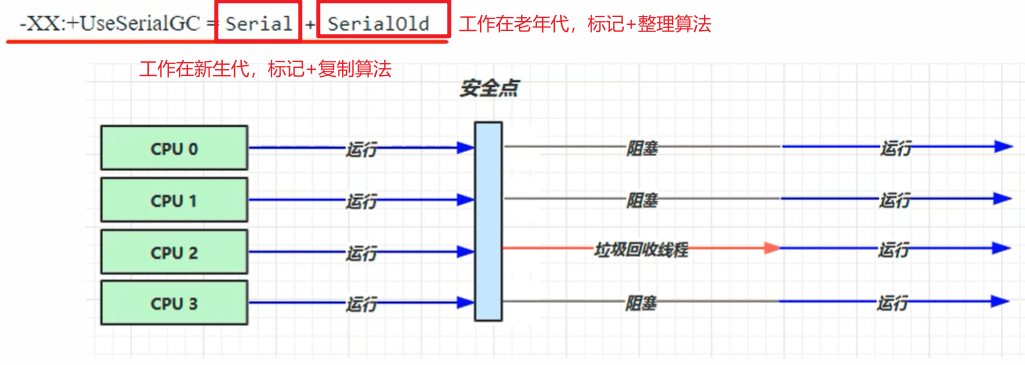
串行(Serial收集器)
吞吐量优先(Parallel Scavenge收集器)
响应时间优先(ParNew+CMS收集器)
G1收集器 定义:Garbage First
2004年论文发表
2009年 JDK6u14体验
2012年 JDK7u4官方支持
2017年 JDK9默认
适用场景:
同时注重吞吐量(Throughtput)和低延迟(Low latency),默认的暂停目标是200ms
超大堆内存,会将堆划分为多个大小相等的Region
整体上是标记+整理算法,两个区域之间是复制算法
相关JVM参数
-XX:+UseG1GC:在JDK8中需要手动开启,JDK9及以后默认开启-XX:G1HeapRegionSize=size-XX:MaxGCPauseMillis=time
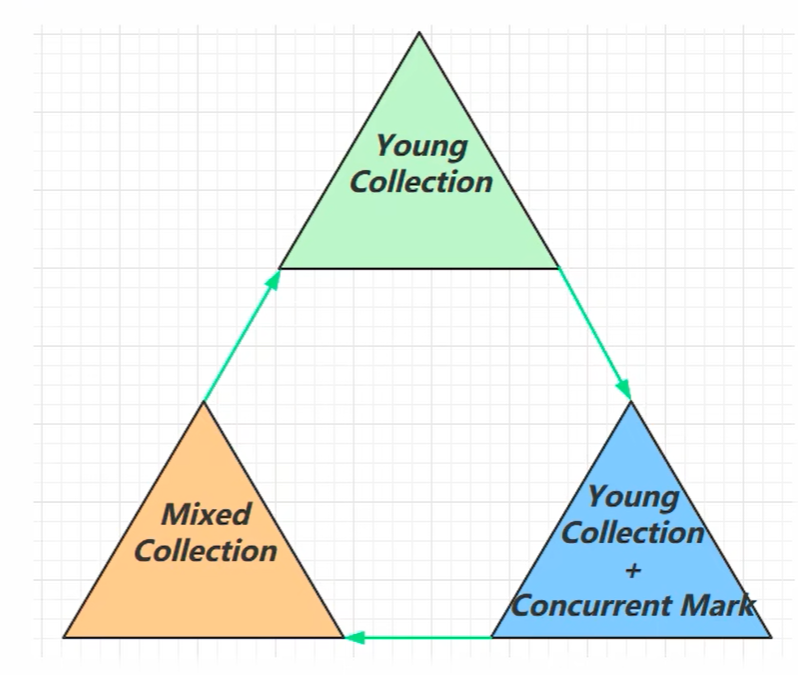
G1垃圾回收阶段 根据Oracle工程师的观点,可以分为三个阶段:
Young Collection
Young Collection + CM
在Young GC时会进行GC Root的初始标记。
老年代占用堆空间比例达到阈值时,进行并发标记(不会STW),阈值由下面的JVM参数决定。
-XX:InitiatingHeapOccupancyPercent=percent(默认45%)
Mixed Collection Garbage First:优先收集那些垃圾最多(价值最大)的区域。
Full GC概念
SerialGC
新生代内存不足发生的垃圾收集:minor gc
老年代内存不足发生的垃圾收集:full gc
ParallelGC
新生代内存不足发生的垃圾收集:minor gc
老年代内存不足发生的垃圾收集:full gc
CMS
新生代内存不足发生的垃圾收集:minor gc
老年代内存不足
如果工作在并发标记、混合收集阶段,回收速度高于垃圾产生速度,不叫full gc。
垃圾回收速度小于垃圾产生速度,并发收集失败,退化为串行收集,STW耗时较长,才叫full gc。
G1
新生代内存不足发生的垃圾收集:minor gc
老年代内存不足
如果工作在并发标记、混合收集阶段,回收速度高于垃圾产生速度,不叫full gc。
垃圾回收速度小于垃圾产生速度,并发收集失败,退化为串行收集,STW耗时较长,才叫full gc。
G1收集器中的一些点 (1)JDK 8u20字符串去重
目前 String 类有两个字段:
1 2 private final char [] value;private int hash;
value 字段是特定于实现的,在 String 类之外看不到。因为 String 类不会修改该数组的内容,也不会将其用于同步,所以我们可以安全且透明地将其在多个 String 对象之间共享。也就是说我们可以将一个 String 对象的 value 指向另一个 String 对象的 value。尽管该字段是 final 的,但因为去重操作是在虚拟机内部实现的,所以这不是问题。
String 对象平均占活数据的 25%
重复的 String 对象平均占活数据的 13.5%
String 的平均长度为 45 个字符
经过分析计算,通过去重、复用 char 数组,平均大概能减少** 10%** 的堆内存占用。
优点:节省大量内存。
缺点:略微多占用了CPU时间,新生代回收时间略微增加。
注意,与String.intern()不同:
String.intern()关注的时字符串对象。字符串去重关注的是String对象内部的char[]。
(2)JDK 8u40 并发标记类卸载 -XX:ClassUnloadingWithConcurrentMark默认开启。(3)JDK 8u60 回收巨型对象
一个对象大于region的一半时,称为巨型对象。
G1不会对巨型对象进行拷贝。
巨型对象回收时被优先考虑。
G1会跟踪老年代所有incoming引用,这样老年代incoming引用为0的巨型对象就可以在新生代垃圾回收时处理掉。
(4)JDK9 并发标记起始时间的调整
JDK9之掐架需要使用-XX:InitiatingHeapOccupancyPercent指定
JDK9Z可以动态调整:
-XX:InitiatingHeapOccupancyPercent用来设置初始值。之后会进行数据采样并动态调整。
会保证一个安全的空档空间。
垃圾回收调优 TODO…