基于Spring Boot的个人博客系统
你好👋,这是一个基于Spring Boot 的个人博客系统,技术框架选用(Spring, SpringMVC, SpringBoot, Mybatis, Thymeleaf)。
目前已经使用微信云托管成功上线,项目托管于GitHub,但是因为密码等安全问题,托管仓库为私有仓库,同时因为网速原因,我在Gitee上重新开源了一个隐去密码的版本,你可以自由查看本仓库源代码,另外,你可以通过下面的链接访问网站前台的演示,查看其效果,网站后台你可以自行编译源代码查看,这里因为安全原因未开放:
https://springboot-nob0-1701609-1310100045.ap-shanghai.run.tcloudbase.com/
Gitee链接:https://gitee.com/littleturing/spring-blog
如果想要运行本项目,只需要替换成自己数据库访问路径和密码即可!
下面是项目的具体介绍与分析 :)
1.项目展示
关于页面,从整体到局部,一点点调试更改,是个十分复杂的过程,需要很有耐心
2.后端设计(重点)
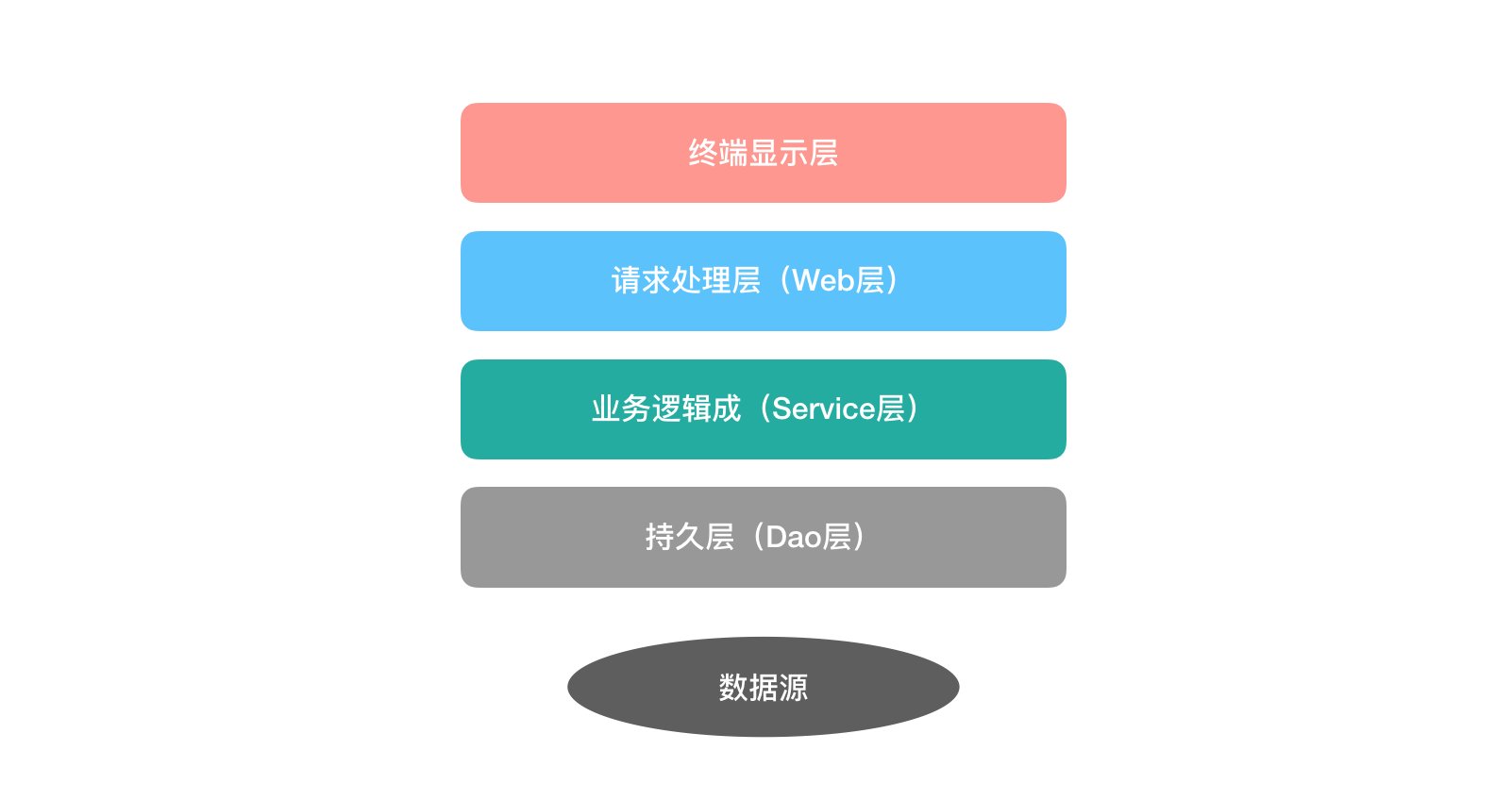
1.概要(三层架构)
2.错误处理(捕获异常)
当用户访问了不存在的资源或者服务器出现异常的时候,希望给用户友好的提示,而不是一大堆的错误信息
我们在这个项目中设计了三个错误页面:
templates文件夹
- 404(资源找不到)
- 500(服务器内部错误)
- error(其他错误)
然后,需要定义一个全局异常处理类ControllerExceptionHandler ,增加ControllerAdvice注解来增强Controller方法,从而实现所有异常的处理。
另外,我们还需要增加一个自定义异常类NotFoundException。举个例子,比如我们需要查找一篇博文,但是并没有在数据库中查询到,这种情况下一般就是返回500或者error,但是我们希望它返回404,这种情况下我们自定义的异常类就起到了作用。
3.日志错误(面向切面编程)
在项目开发的过程中,往往需要记录一些必要的日志,方便在系统出现问题的时候及时定位和解决。比如,对于一个典型的 B/S 架构的 Web 服务程序,我们最关注的其实是请求者的相关信息,也就是controller层方法的调用,这是整个系统与外界的联系。于是,我们在每次controller方法被调用的时候考虑记录以下内容:
- 请求url
- 访问者ip
- 调用方法 classMethod
- 参数 args
- 返回内容
显然,一个很简单常规的做法就是在每个controller方法里面都手动加上log方法🤣🤣,虽然不失为一种方法,但是显然这太麻烦了,不符合我们对简洁性的期望,另外,这样做的最严重的后果是代码与代码之间的耦合十分严重!即牵一发而动全身😑。
对于这种问题,我们采用面向切面编程(AOP)的方法解决,其实这是Spring的一个核心。
AOP技术利用一种称为“横切”的技术,剖解开封装对象的内部,将影响多个类的公共行为封装到一个可重用的模块中,并将其命名为Aspect切面。所谓的切面,简单来说就是与业务无关,却为业务模块所共同调用的逻辑,将其封装起来便于减少系统的重复代码,降低模块的耦合度,有利用未来的可操作性和可维护性。
利用AOP可以对业务逻辑各个部分进行隔离,从而使业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高开发效率。
AOP的使用场景主要包括日志记录、性能统计、安全控制、事务处理、异常处理等。
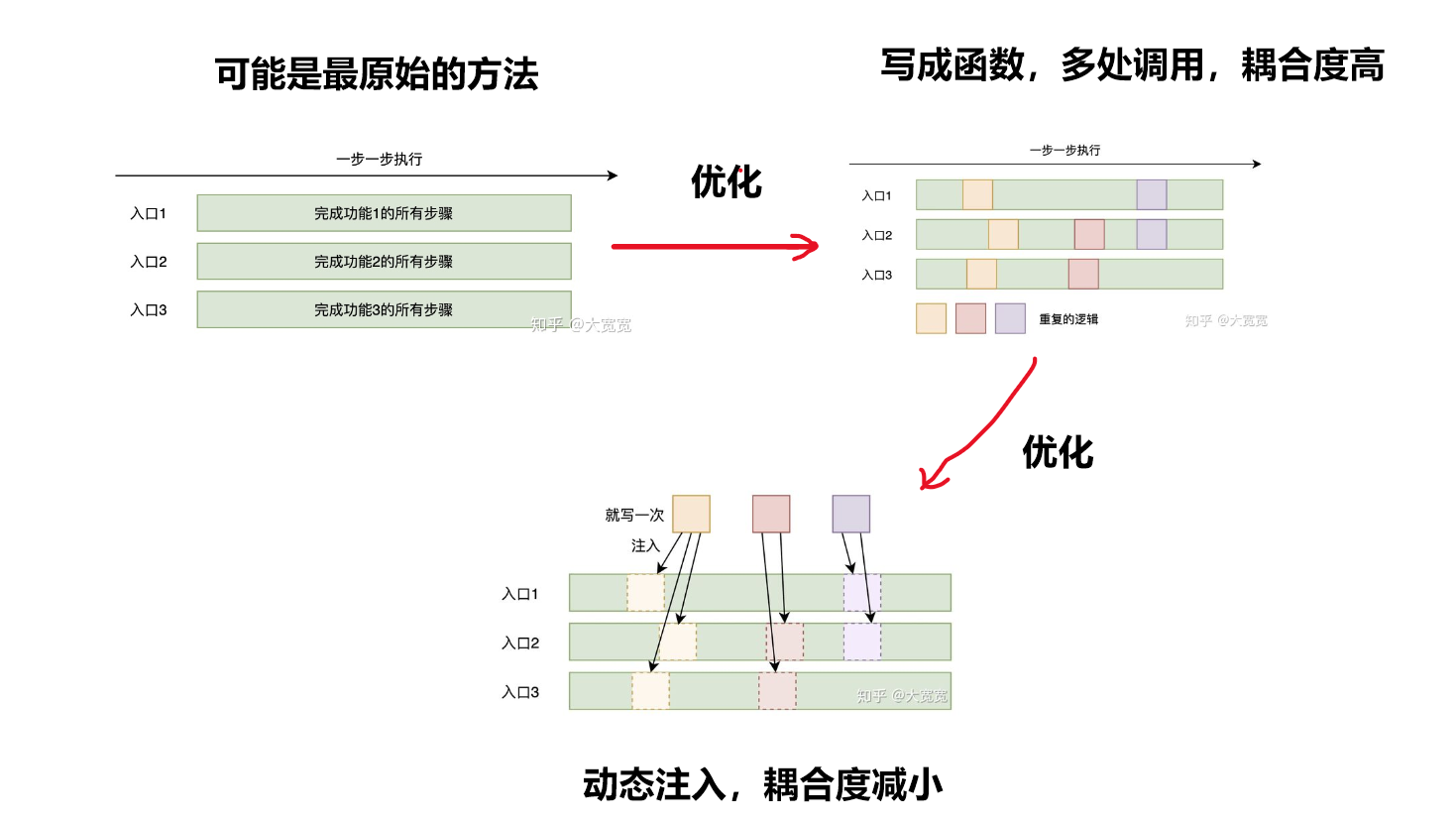
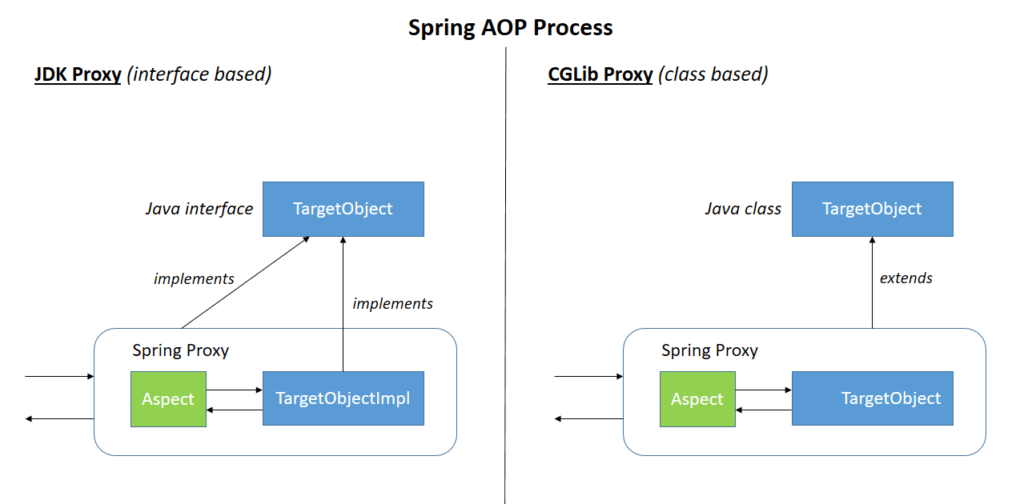
我们的做法是定义一个切面Aspect,然后在里面定义以下方法
LogAspect类
- doBefore
- log
- doAfter
- doAfterReturning
最后,配置一下切面就 ok 了
1 |
4.静态资源的引入与处理
前端项目是在WebStorm里面开发的,是静态页面,内容也是写死的,好在目录是对应的,所以直接把之前开发好的前端页面文件夹复制到IDEA项目目录里面再稍微改下就好了。主要任务是能够正常打开(指CSS和JS文件的路径没有乱)即可。
在接下来的开发过程中,就需要逐步地把静态内容替换成动态内容,这个过程是比较费时费力的,在此不做过多说明。
5.数据库实体与设计
根据业务需求,我们进行数据库的设计,这里采用的方式是实体驱动型,即先进行实体类的设计,再进行数据库表的设计。
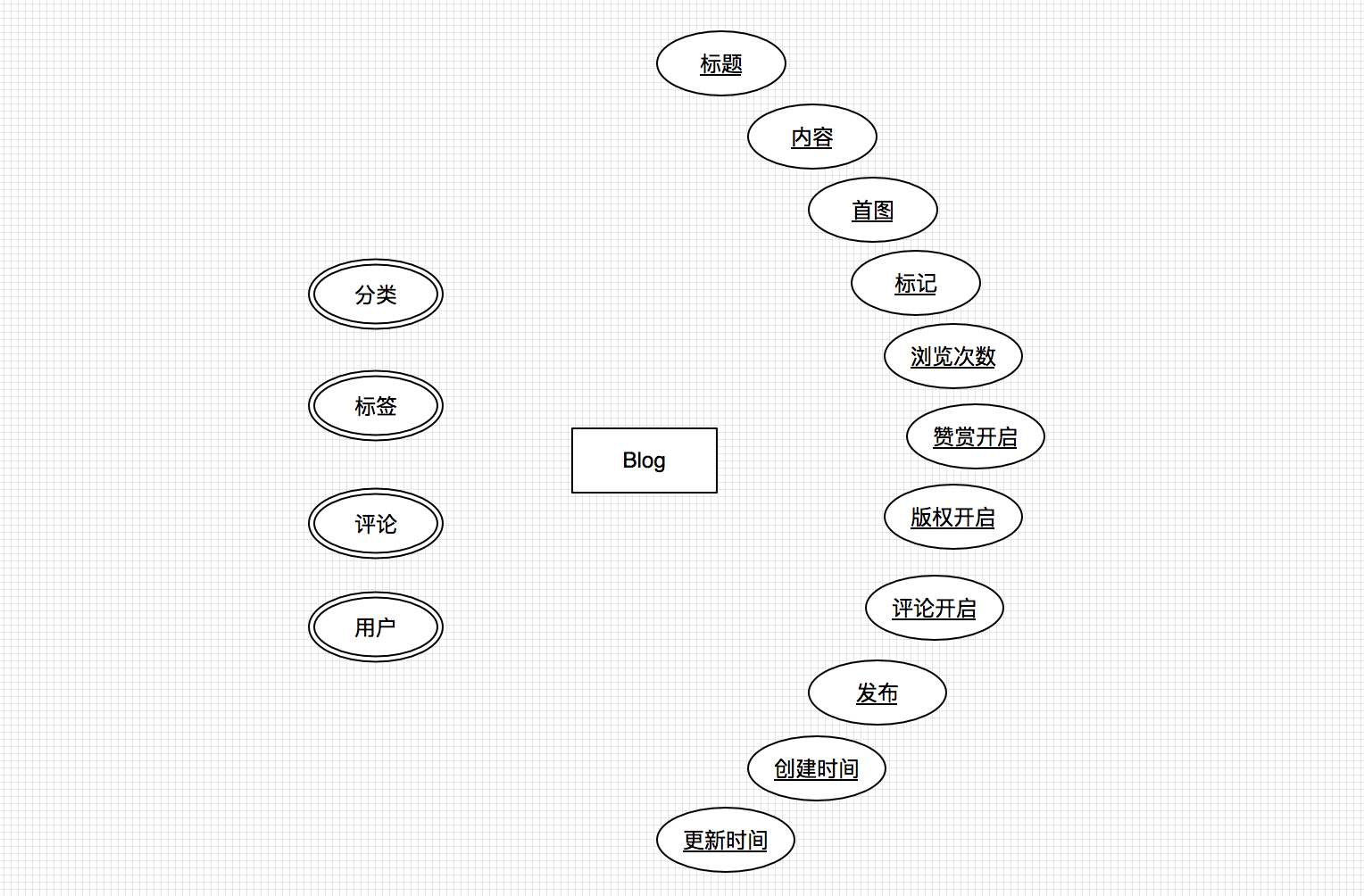
- 博客 Blog
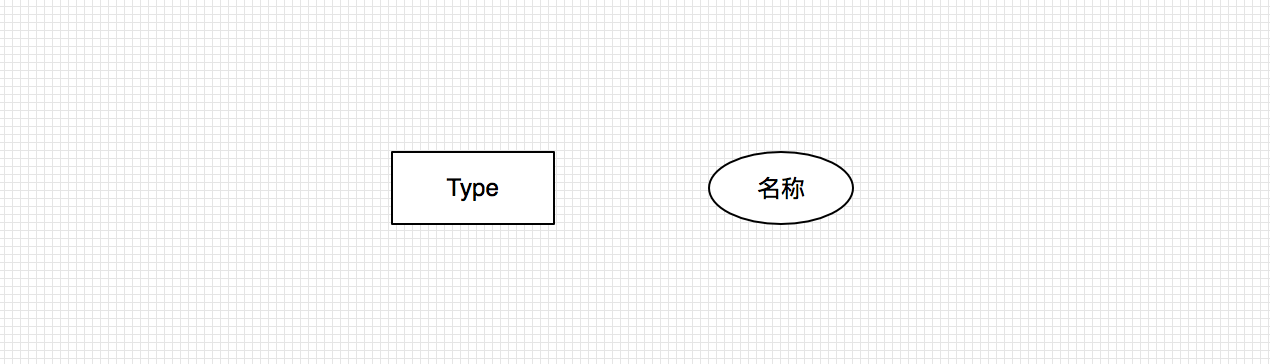
- 博客分类 Type
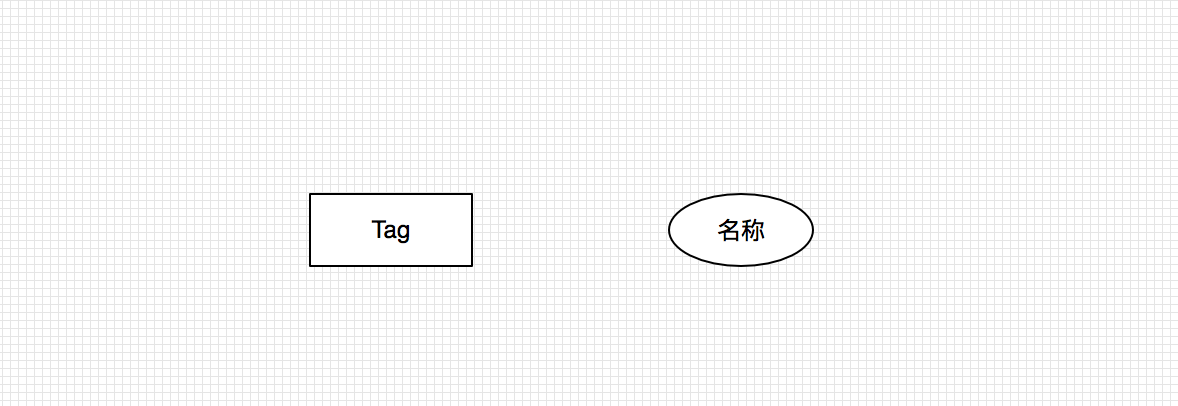
- 博客标签 Tag
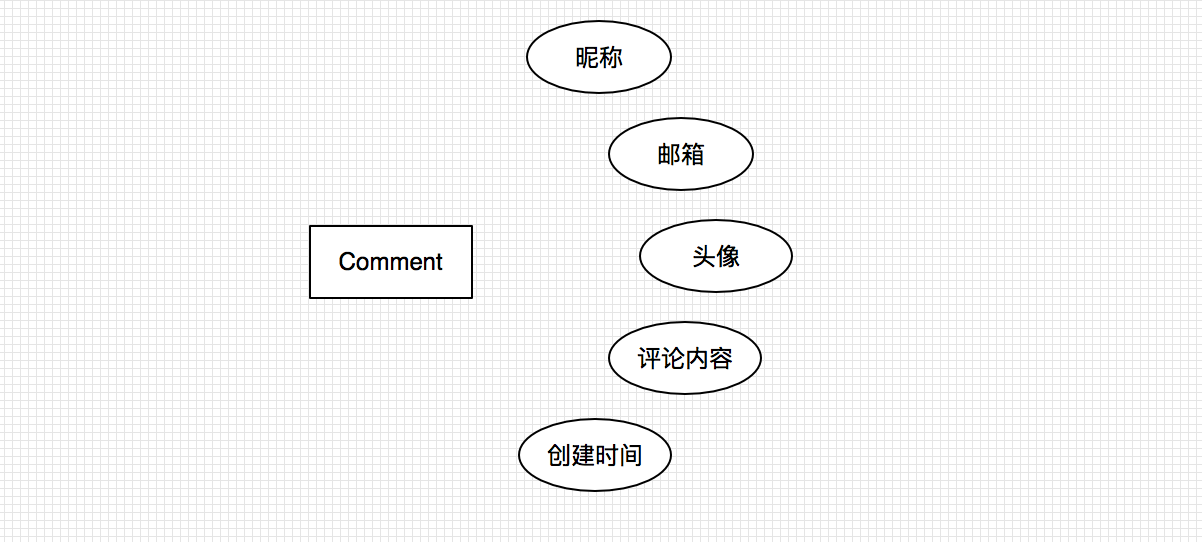
- 博客评论 Comment
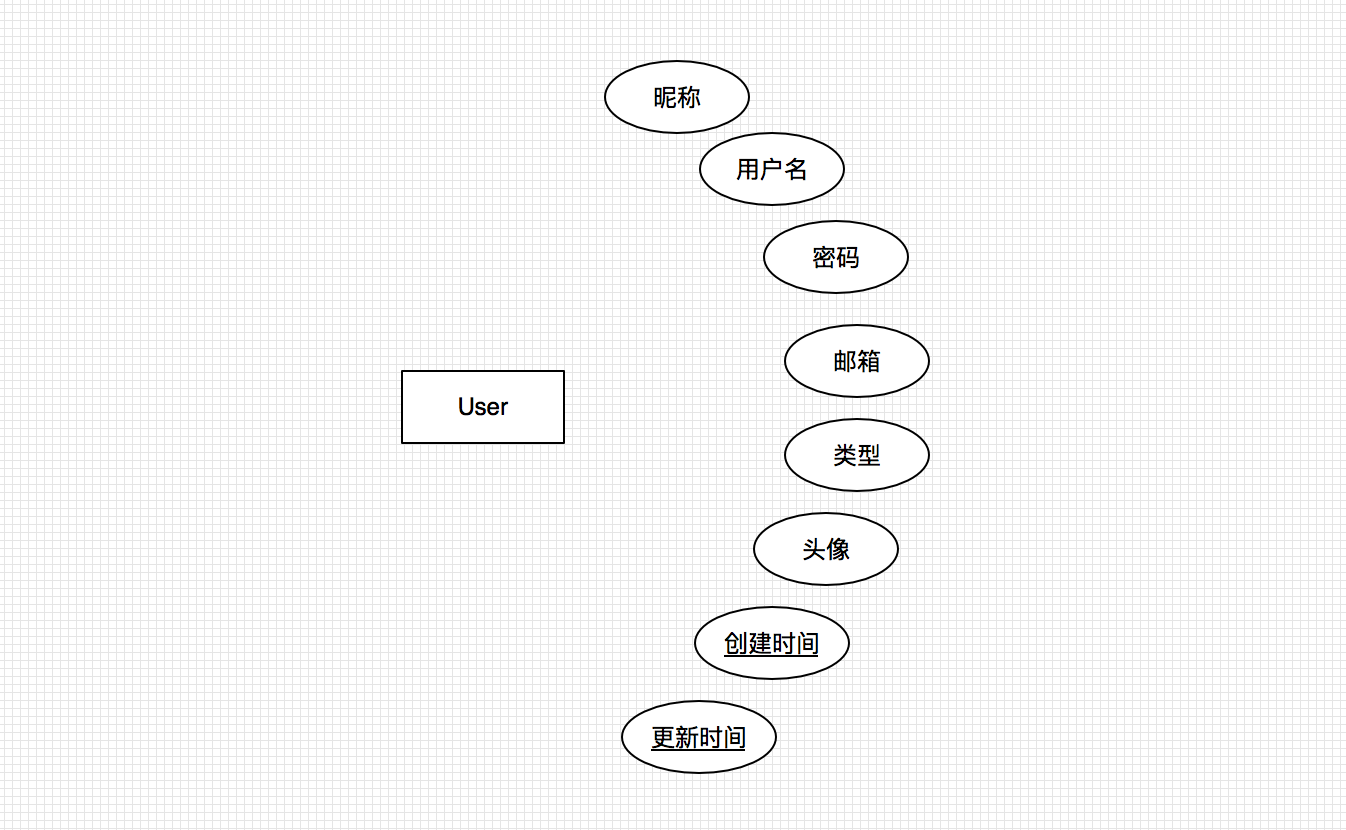
- 用户 User
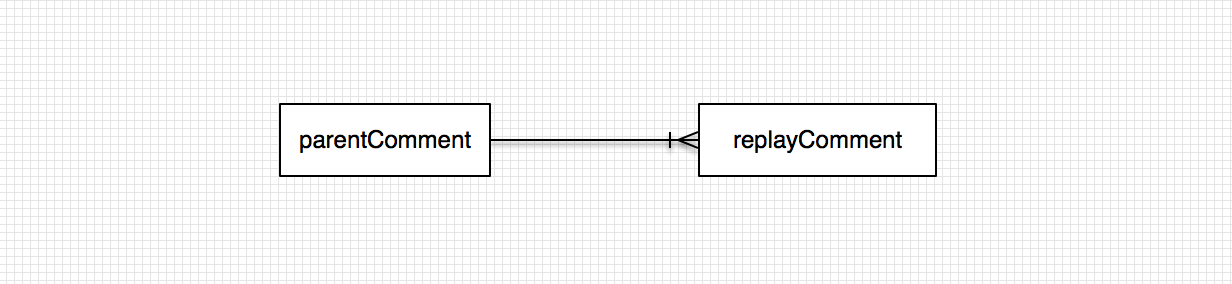
实体关系:

评论类自关联关系
Blog类
Type类
Tag类:
Comment类
User类
6.后台管理
对于后台管理,最重要的是三层架构的理解与使用。
首先来看一下文件夹的样子
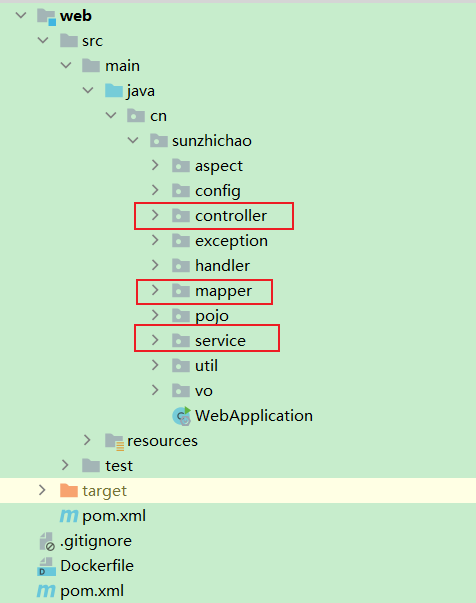
其中最重要的自然是
controllerservicemapper
controller负责接收 HTTP 请求,然后调用service里面的方法,着重处理业务逻辑,在service层会调用dao(mapper)层的方法,用于数据库的增删改查
1.后台登录
后台登录的逻辑其实很简单,无非是接收请求,然后查询数据库,验证用户名和密码是否正确,正确则把User放在 session 里,不正确则弹出提示信息。
重点在于拦截器的配置,拒绝在未登录情况下根据 url 访问相应页面
创建拦截器
1 | public class LoginInterceptor implements HandlerInterceptor { |
配置拦截器
1 |
|
2.分类管理
对分类进行增删改查
3.标签管理
对标签进行增删改查
4.博客管理
对博客进行增删改查,注意关联表的操作
7.前台展示
1.评论展示
二级评论展示,需要在后端将一篇文章对应的所有评论处理一遍,根据父评论的id,处理完之后再返回前端
2.归档展示:
- 查询所有年份
- 根据特定年份查询所有Blog
- 最后放在一个Map里面返回给前端
3.全局搜索
- 根据输入的内容作为一个String字符串传入,然后在数据库中模糊查询
4.按照分类或者标签显示
- 直接查询即可










