27张图,万字长文,紧紧追踪算法的每一步!深搜与广搜如何理解?它们又有哪些重要的应用呢?本文全部告诉你~
约定:本文所有涉及的图均为无向图,有向图会在之后的文章设计
1.图的存储方式
我们首先来回顾一下图的存储方式:邻接矩阵和邻接表。为了实现更好的性能,我们在实际应用中一般使用邻接表的方式来表示图。
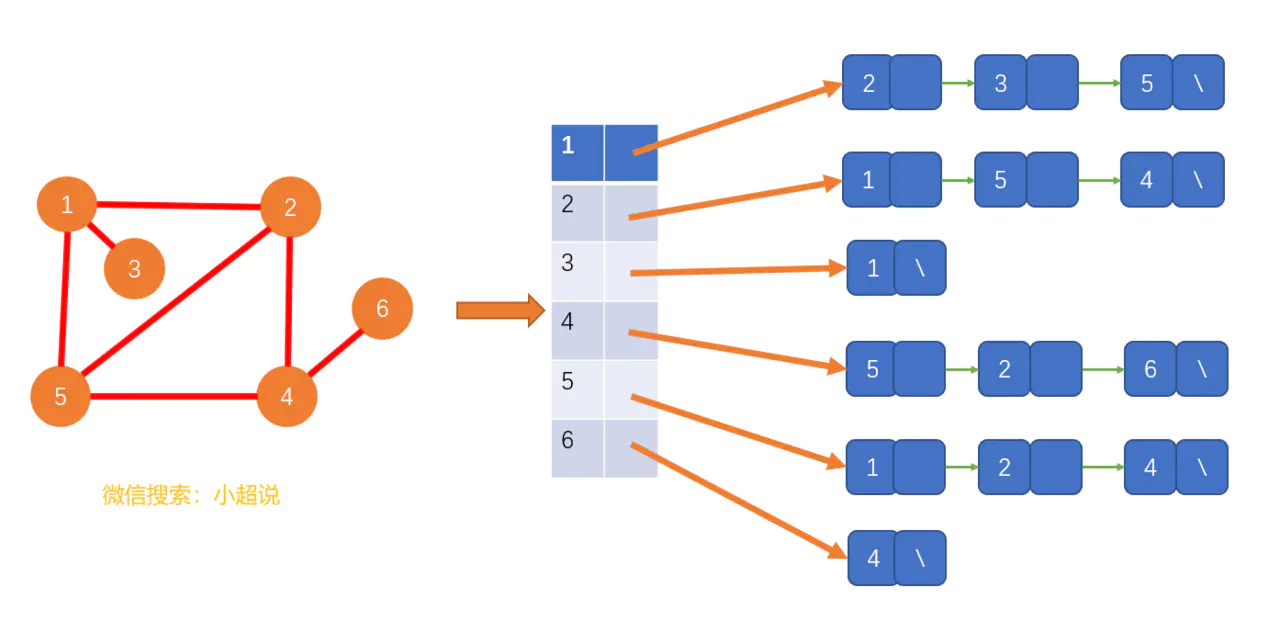
具体的实现代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| package Graph;
import java.util.LinkedList;
public class Graph{
private final int V;
private int E;
private LinkedList<Integer> adj[];
public Graph(int V){
this.V=V;this.E=0;
adj=new LinkedList[V];
for(int v=0;v<V;++v){
adj[v]=new LinkedList<>();
}
}
public int V(){ return V;}
public int E(){ return E;}
public void addEdge(int v,int w){
adj[v].add(w);
adj[w].add(v);
E++;
}
public Iterable<Integer> adj(int v){
return adj[v];
}
}
|
接下来,我们会首先介绍深度优先搜索与广度优先搜索的原理和具体实现;然后根据这两个基本的模型,我们会介绍六种典型的应用,这些应用只是在深搜和广搜的代码的基础上进行了一些加工,却可以解决不同的问题!
注意:我们的思路:如何遍历一张图?==>深搜与广搜==>能够解决的问题。
2.深度优先搜索
深度优先搜索是利用递归方法实现的。我们只需要在访问其中一个顶点时:
- 将它标记为已经访问
- 递归地访问它的所有没有被标记过的邻居顶点
我们来仔细地看一下这个过程:
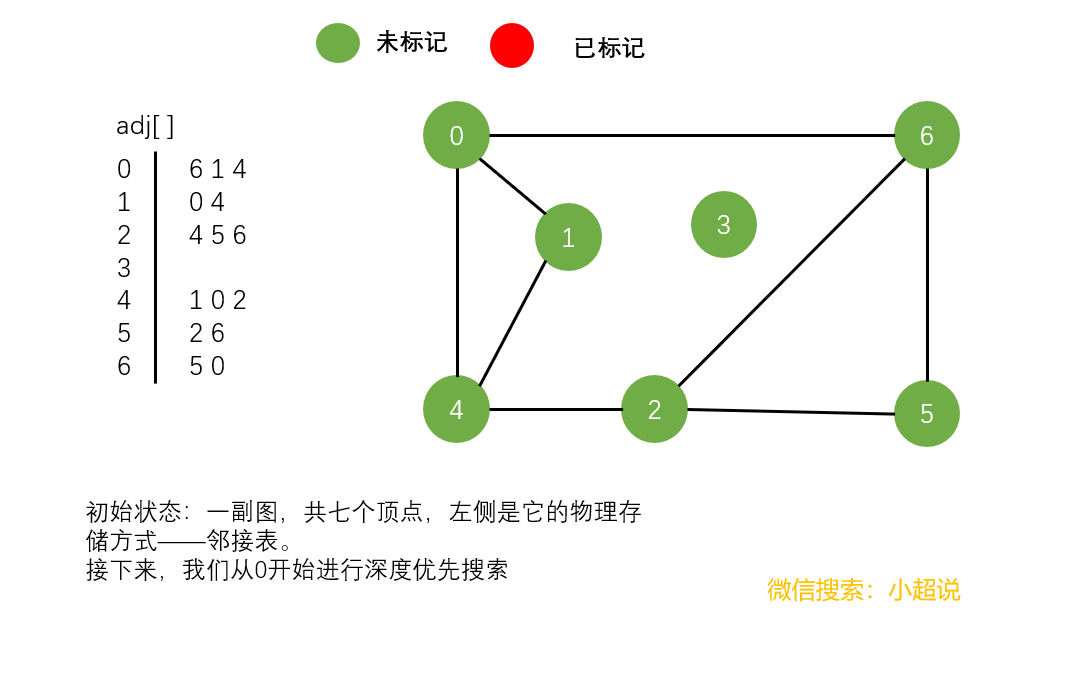

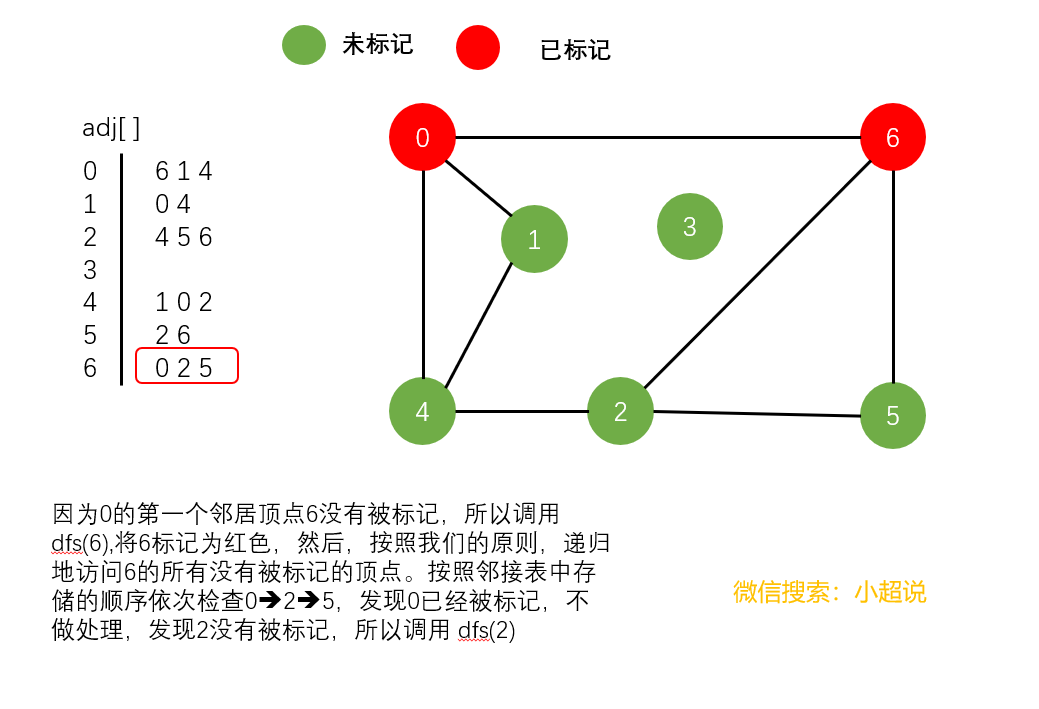
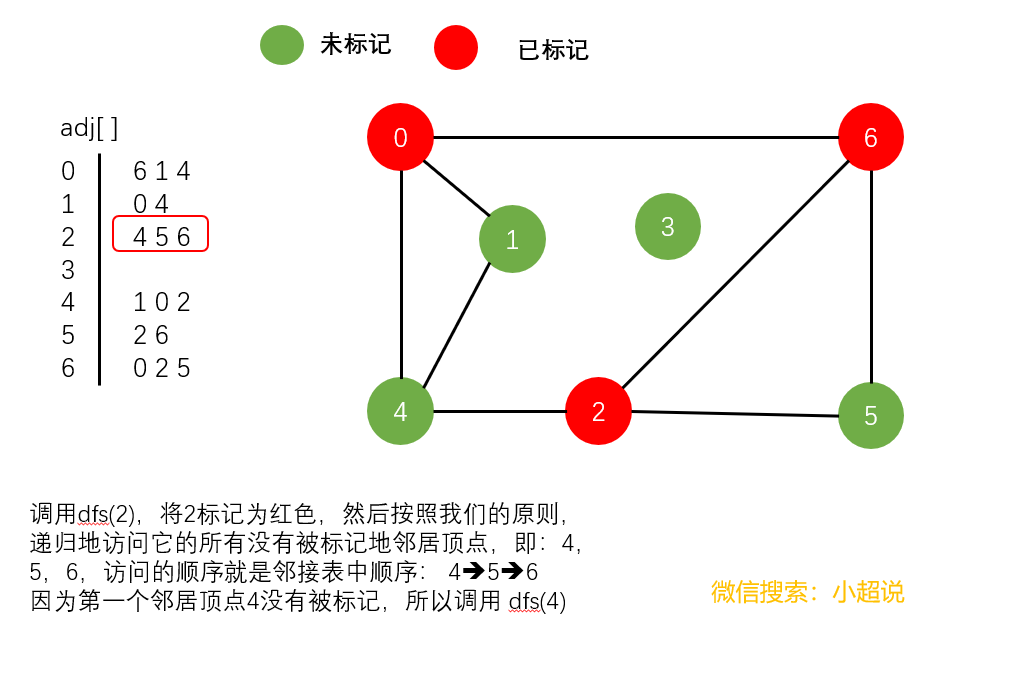
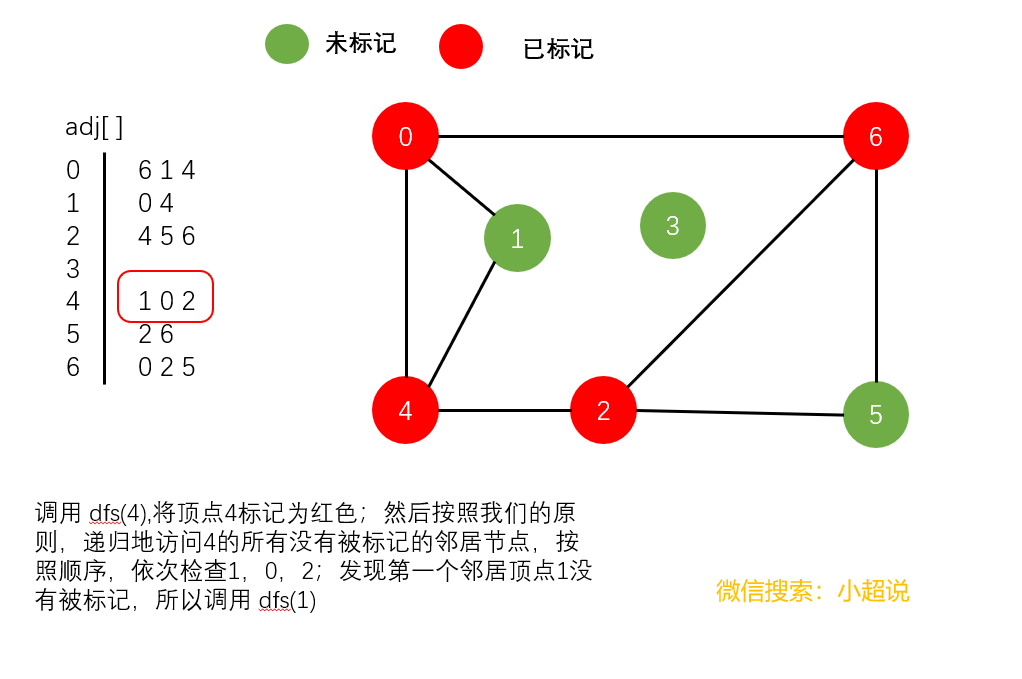
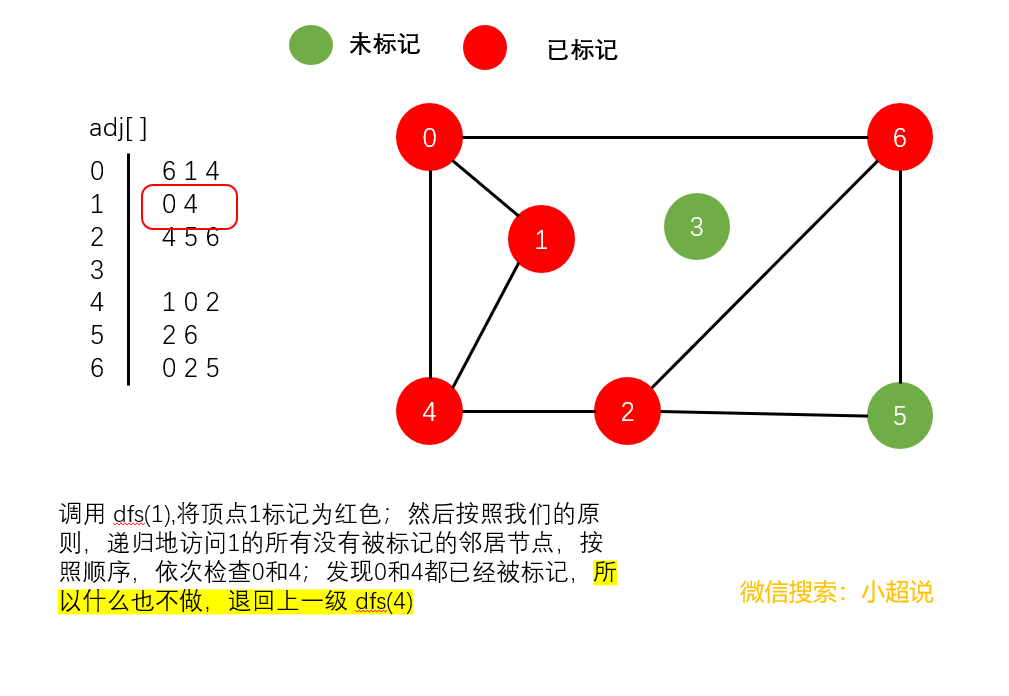
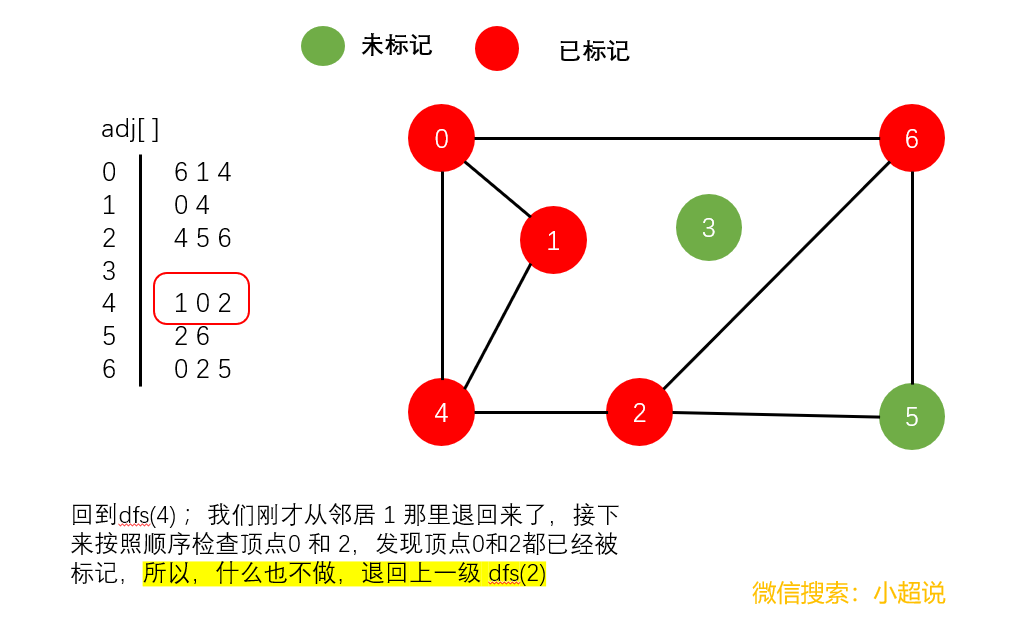
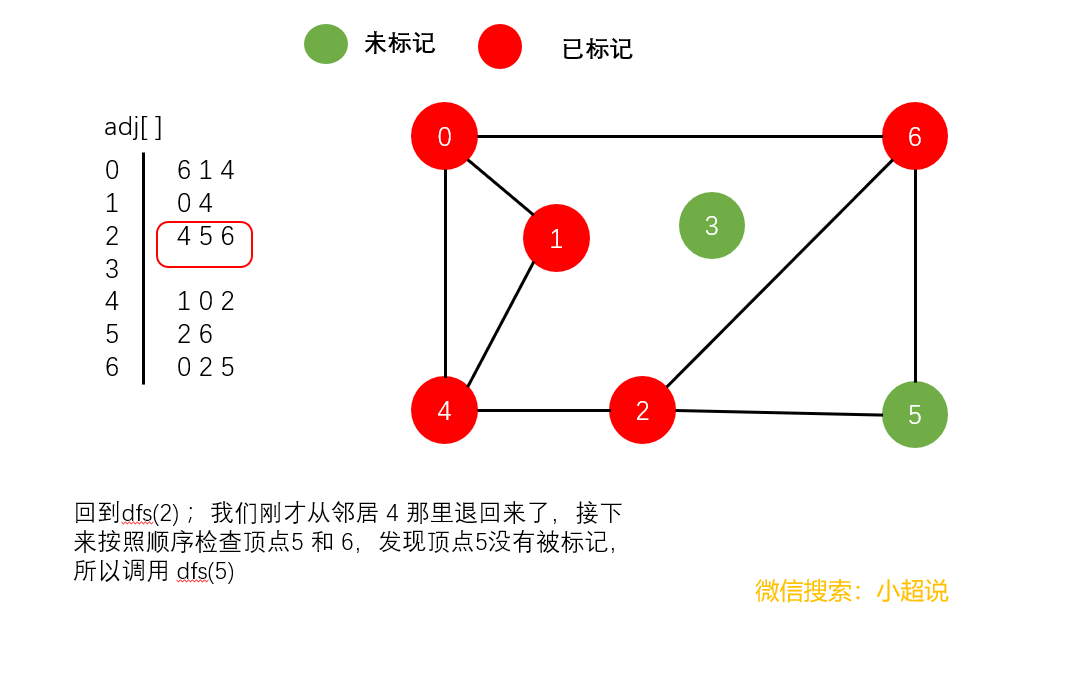
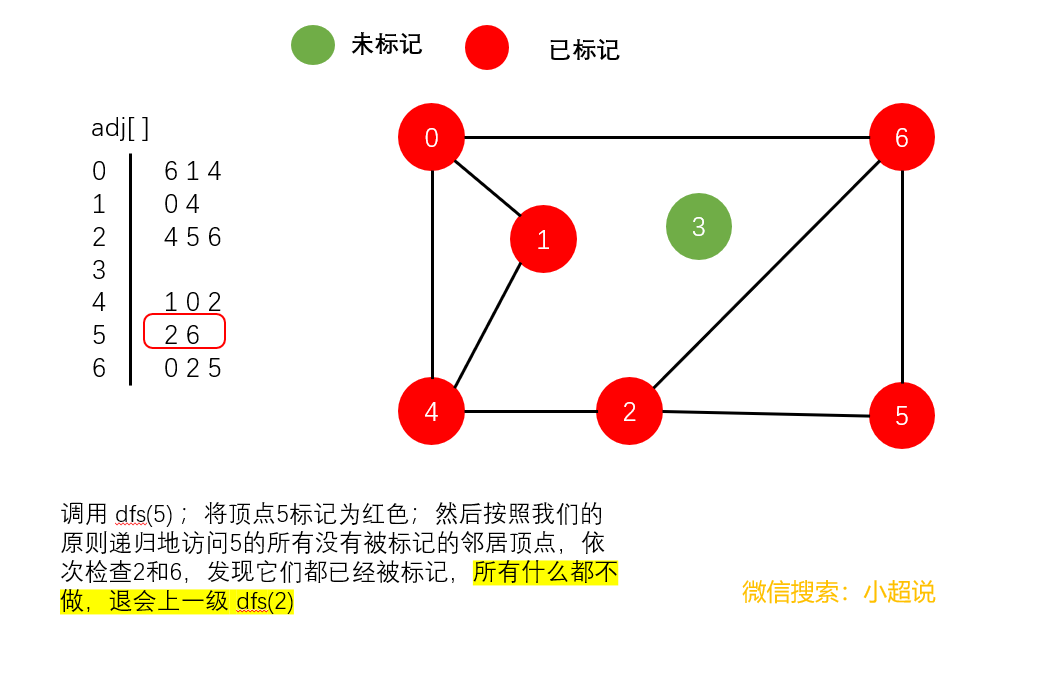
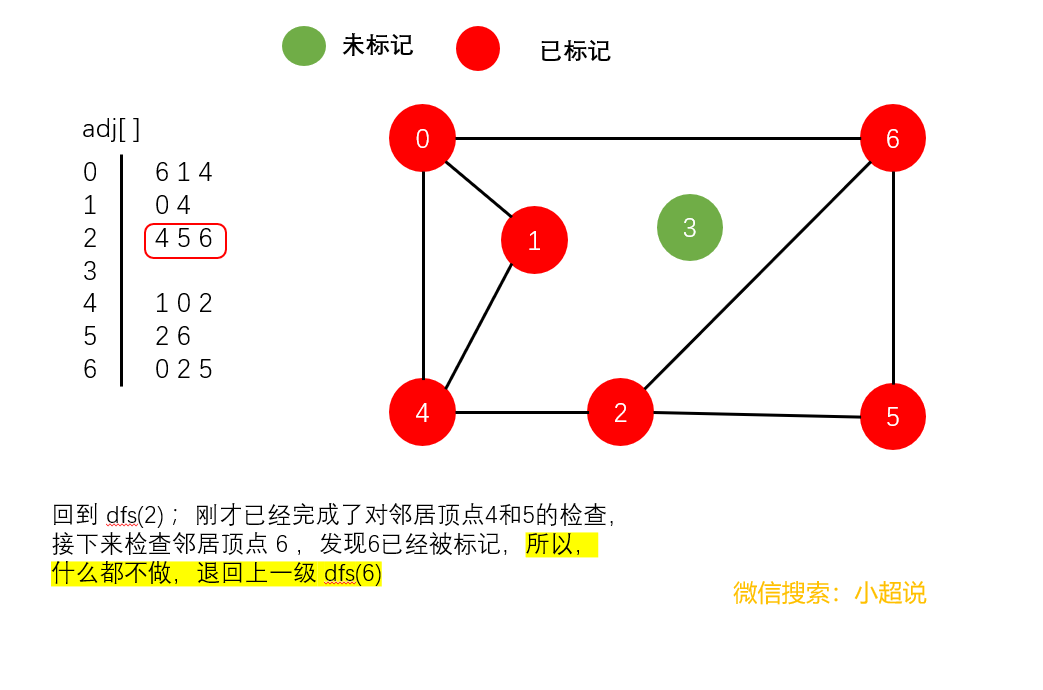
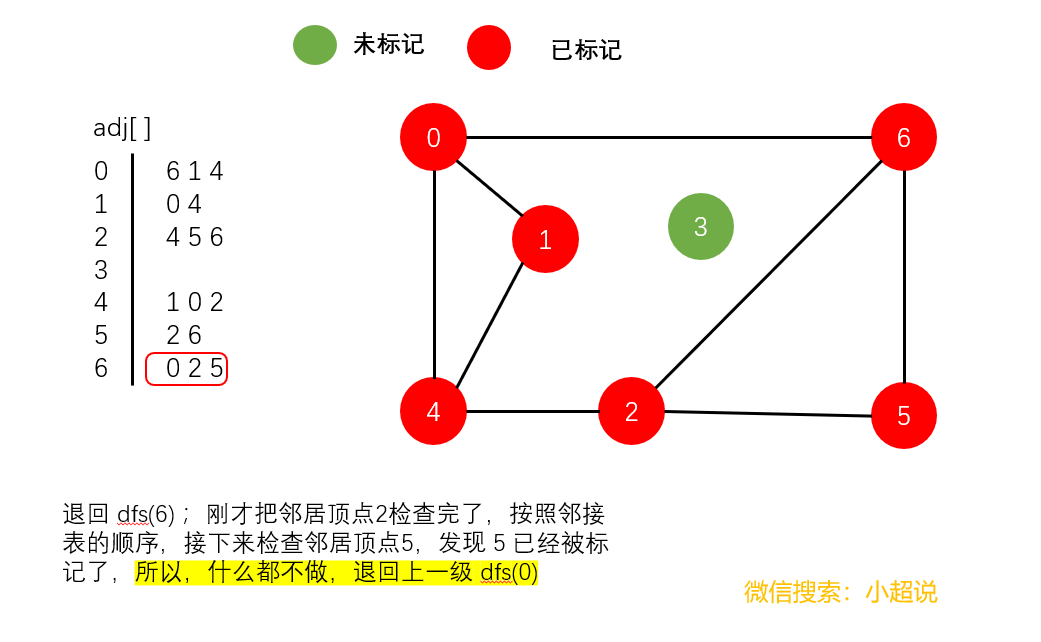
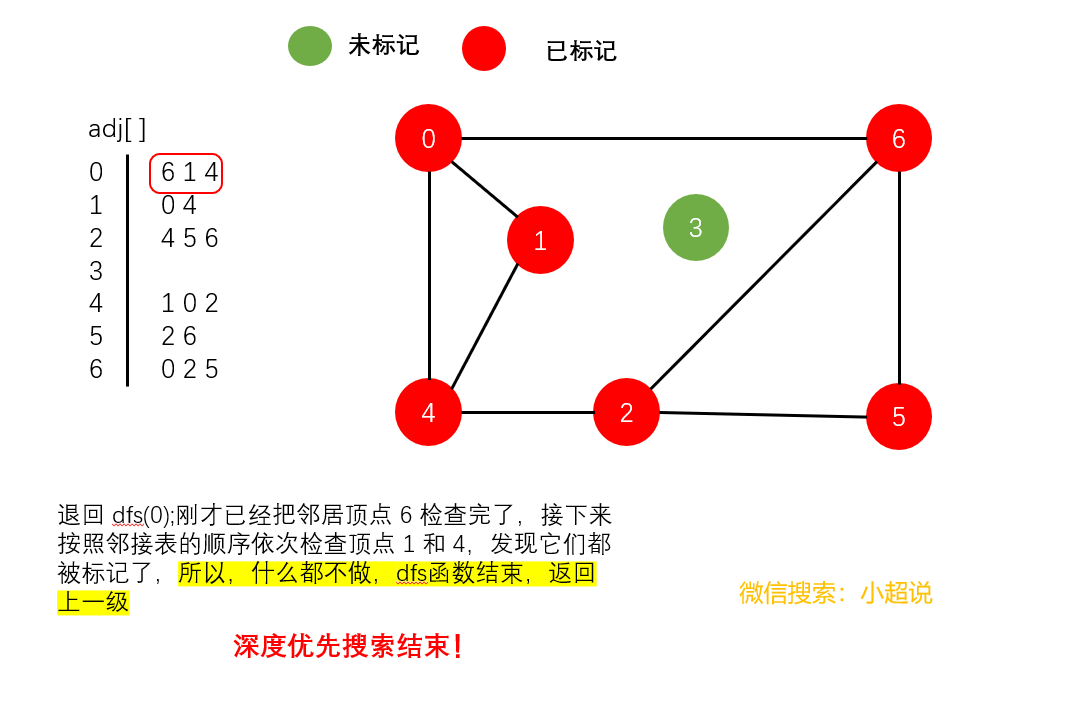
深度优先搜素大致可以这样描述:不撞南墙不回头,它沿着一条路一直走下去,直到走不动了然后返回上一个岔路口选择另一条路继续前进,一直如此,直到走完所有能够到达的地方!它的名字中深度两个字其实就说明了一切,每一次遍历都是走到最深!
注意一个细节:在我们上面的最后一个图中,顶点3仍然未被标记(绿色)。我们可以得到以下结论:
使用深度优先搜索遍历一个图,我们可以遍历的范围是所有和起点连通的部分,通过这一个结论,下文我们可以实现一个判断整个图连通性的方法。
深度优先搜索的代码实现,我是用Java实现的,其中,我定义了一个类,这样做的目的是更加清晰(毕竟,一会后面还有很多算法)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| package Graph;
public class DepthFirthSearch {
private boolean[] marked;
public DepthFirthSearch(Graph G,int s){
marked = new boolean[G.V()];
dfs(G,s);
}
private void dfs(Graph G,int v){
marked[v]=true;
for(int w:G.adj(v))
if(!marked[w]) dfs(G, w);
}
public boolean marked(int w){
return marked[w];
}
}
|
3.深搜应用(一):查找图中的路径
我们通过深度优先搜索可以轻松地遍历一个图,如果我们在此基础上增加一些代码就可以很方便地查找图中的路径!
比如,题目给定顶点A和顶点B,让你求得从A能不能到达B?如果能,给出一个可行的路径!
为了解决这个问题,我们添加了一个实例变量edgeTo[]整型数组来记录路径。比如:我们从顶点A直接到达顶点B,那么就令edgeTo[B]=A,也就是“edge to B is A”,其中A是距离B最近的顶点且从A可以到达B。我举个简单的例子:
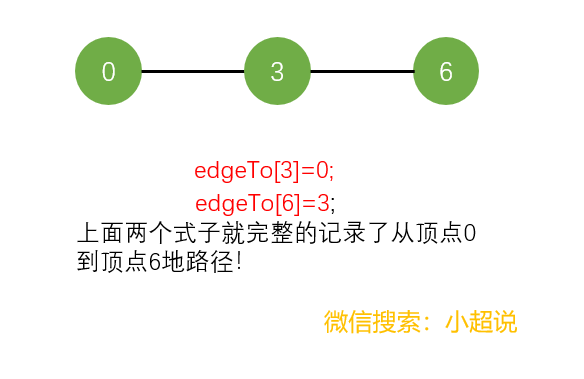
具体的代码如下,其中为了实现这个功能,我定义了一个完整的类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| package Graph;
import java.util.Stack;
public class DepthFirstPaths {
private boolean [] marked;
private int[] edgeTo;
private final int s;
public DepthFirstPaths(Graph G,int s){
marked = new boolean[G.V()];
edgeTo = new int[G.V()];
this.s=s;
dfs(G,s);
}
private void dfs(Graph G,int v){
marked[v]=true;
for(int w:G.adj(v)){
if(!marked[w]){
edgeTo[w]=v;
dfs(G,w);
}
}
}
public boolean hasPathTo(int v){
return marked[v];
}
public void pathTo(int v){
if(!hasPathTo(v)) System.out.println("不存在路径");;
Stack<Integer> path=new Stack<Integer>();
for(int x=v;x!=s;x=edgeTo[x]){
path.push(x);
}
path.push(s);
while(path.empty()==false)
System.out.print(path.pop()+" ");
System.out.println();
}
}
|
最后一个打印函数pathTo地思想就是通过一个for循环,将路径压到一个栈里,通过栈地先进后出地性质实现反序输出。理解了上面的dfs地过程就好,这里可以单独拿出来去理解。
4.深搜应用(二):寻找连通分量
还记得我们上文讲到的dfs的一条性质吗?一个dfs搜索能够遍历与起点相连通的所有顶点。我们可以这样思考:申请一个整型数组id[0]用来将顶点分类——“联通的顶点的id相同,不连通的顶点的id不同”。首先,我对顶点adj[0]进行dfs,把所有能够遍历到的顶点的id设置为0,然后把这些顶点都标记;接下来对所有没有被标记的顶点进行dfs,执行同样的操作,比如将id设为1,这样依次类推,直到把所有的顶点标记。最后我们我们得到的id[]就可以完整的反映这个图的连通情况。
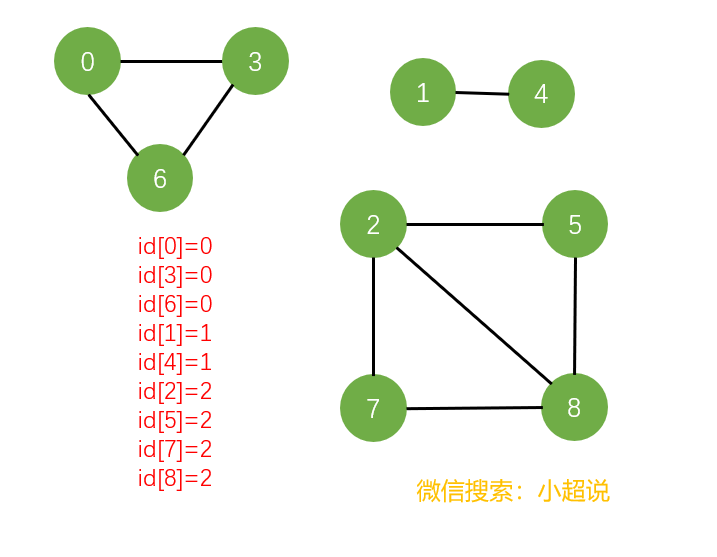
如果我们需要判断两个顶点之间是否连通,只需要比较它们的id即可;同时,我们还可以根据有多少个不同的id来获得一个图中连通分量的个数,一举两得!
具体的代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| package Graph;
public class CC {
private boolean[] marked;
private int [] id;
private int count;
public CC(Graph G){
marked = new boolean[G.V()];
id=new int[G.V()];
for(int s=0;s<G.V();s++){
if(!marked[s]){
dfs(G,s);
count++;
}
}
}
private void dfs(Graph G,int v){
marked[v]=true;
id[v]=count;
for(int w:G.adj(v)){
if(!marked[w])
dfs(G,w);
}
}
public boolean connected(int v,int w){
return id[v]==id[w];
}
public int id(int v){
return id[v];
}
public int count(){
return count;
}
}
|
5.深搜应用(三):判断是否有环
6.深搜应用(四):判断是否为二分图
二分图定义是:能够用两种颜色将图的所有顶点着色,使得任意一条边的两个端点的颜色都不相同。
对于这个问题,我们依然只需要在dfs中增加很少的代码就可以实现。
具体思路:我们在进行dfs搜索的时候,凡是碰到没有被标记的顶点时就将它依据二分图的定义标记(使相邻顶点的颜色不同),凡是碰到已经标记过的顶点,就检查相邻顶点是否不同色。在这个过程中,如果发现存在相邻顶点同色,则不是二分图;如果直到遍历完也没有发现上述同色情况,则是二分图,且上述根据dfs遍历所染的颜色就是二分图的一种。
具体的代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| package Graph;
public class TwoColor{
private boolean[] marked;
private boolean[] color;
private boolean isTwoColorable = true;
public TwoColor(Graph G){
marked=new boolean[G.V()];
color=new boolean[G.V()];
for(int s=0;s<G.V();s++){
if(!marked[s]){
dfs(G,s);
}
}
}
private void dfs(Graph G,int v){
marked[v]=true;
for(int w:G.adj(v)){
if(!marked[w]){
color[w]=!color[v];
dfs(G,w);
}
else if(color[w]==color[v]) isTwoColorable=false;
}
}
public boolean isBipartite(){
return isTwoColorable;
}
}
|
5.广度优先搜索
在很多情境下,我们不是希望单纯地找到一条连通的路径,而是希望找到最短的那条,这个时候深搜就不再发挥作用了,我们接下来介绍另一种图的遍历方式:广度优先搜索(bfs)。我们先介绍它的实现,然后再介绍如何寻找最短路径。
广度优先搜索使用一个队列来保存所有已经被标记过但其邻接表还未被检查过的顶点。它先将起点加入队列,然后重复以下步骤直到队列为空。
- 取队列中的第一个顶点
v出队
- 将与
v相邻的所有未被标记过的顶点先标记后加入队列
注意:在广度优先搜索中,我们并没有使用递归,在深搜中我们隐式地使用栈,而在广搜中我们显式地使用队列
一起来看一下具体的过程吧~

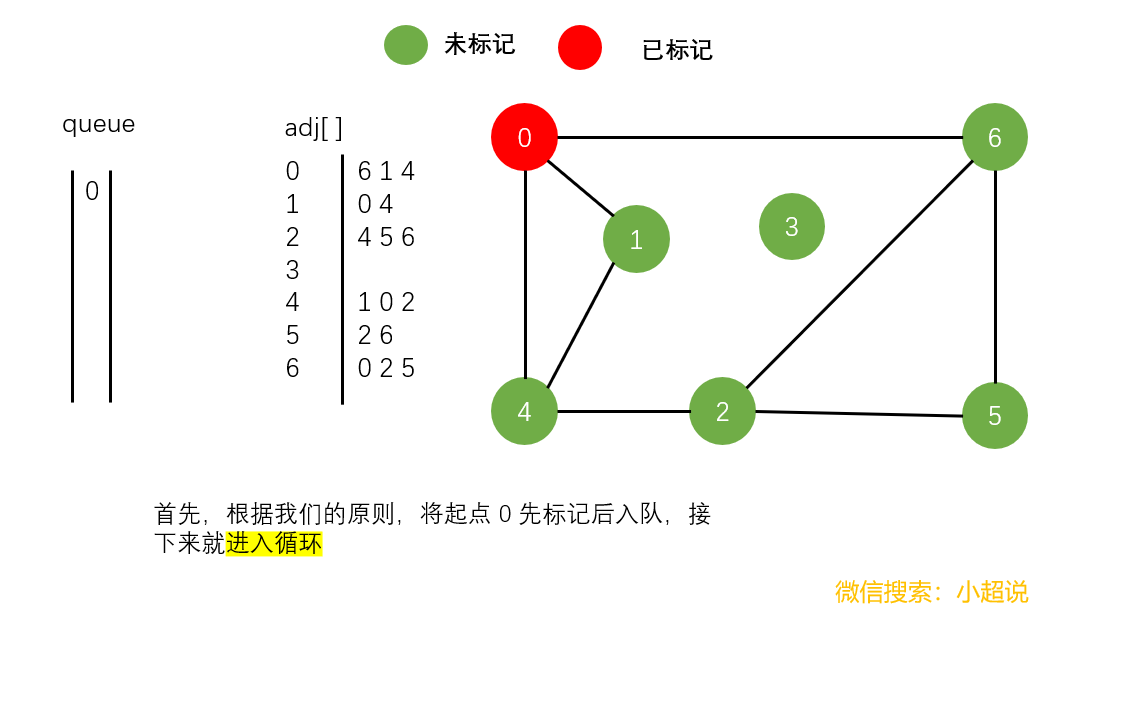
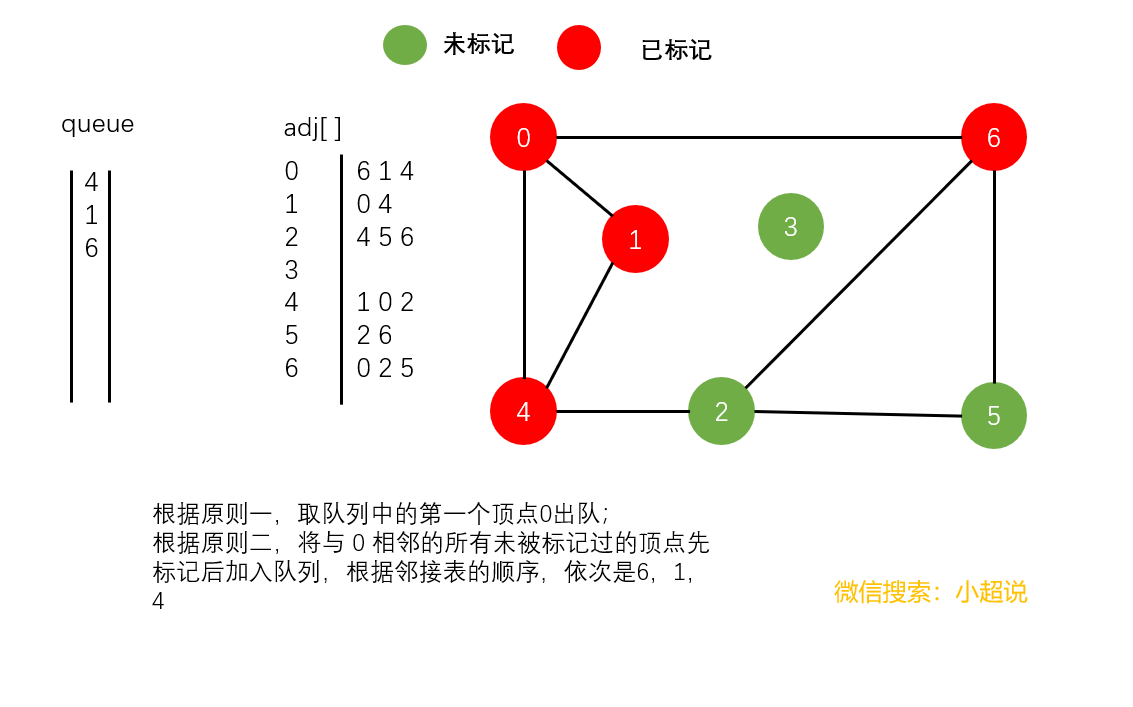
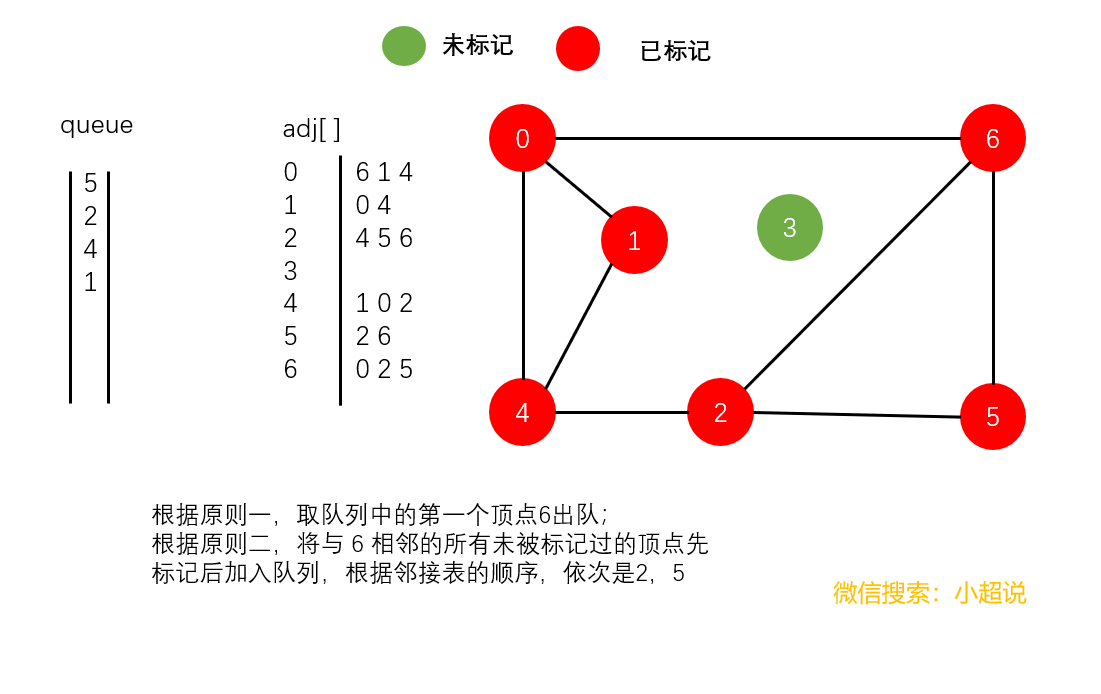
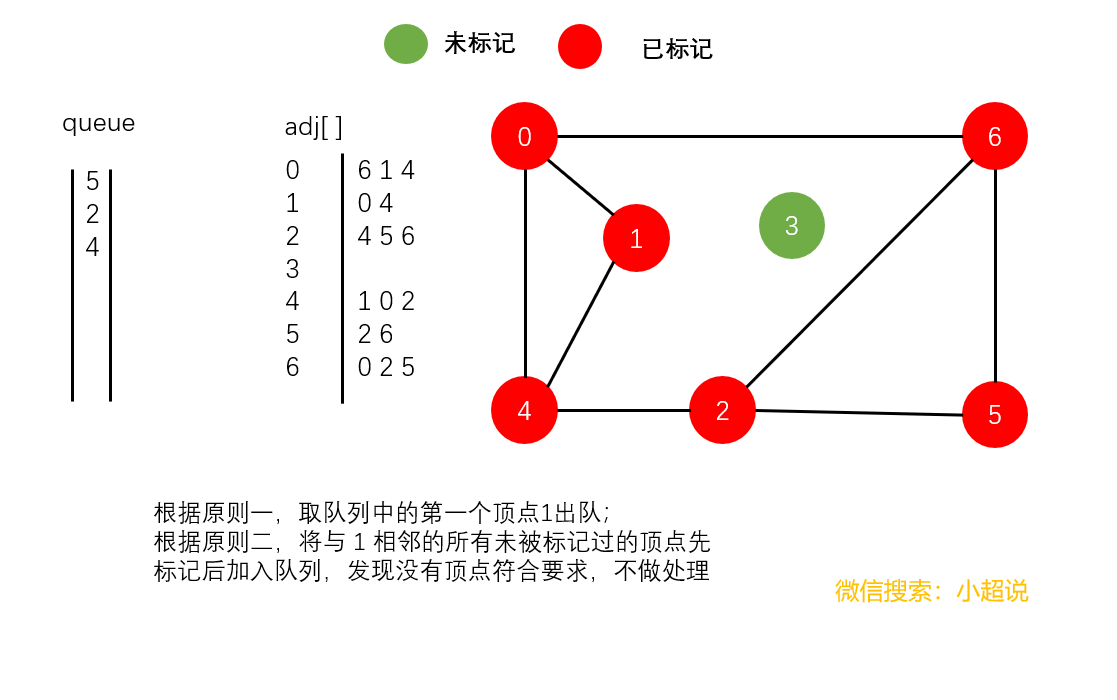
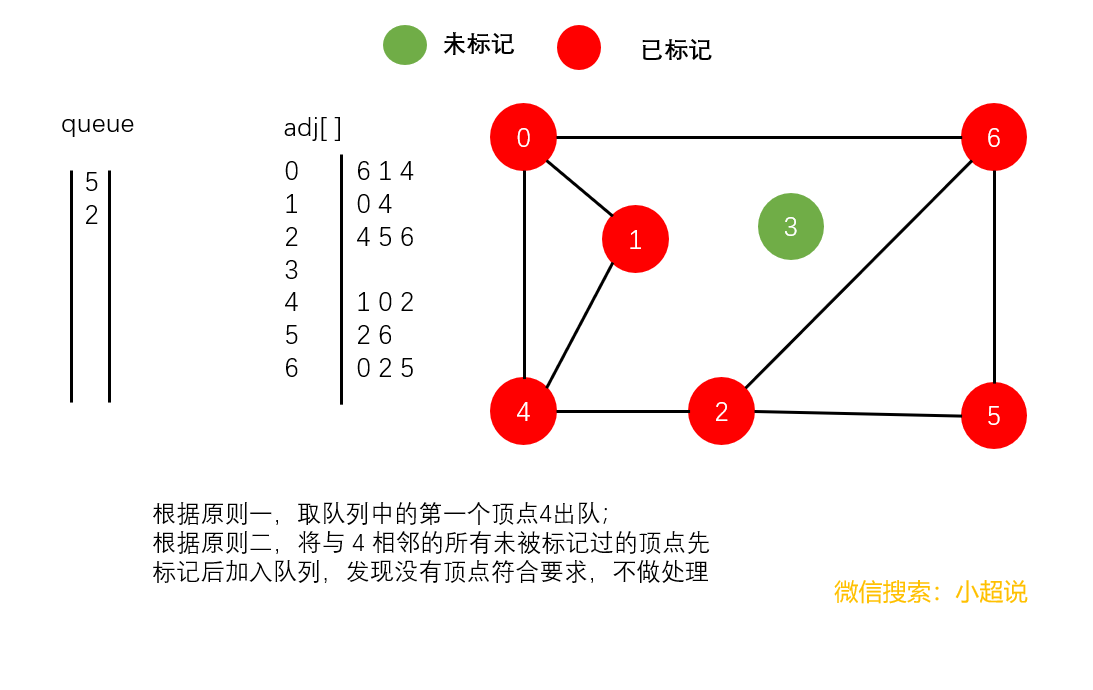
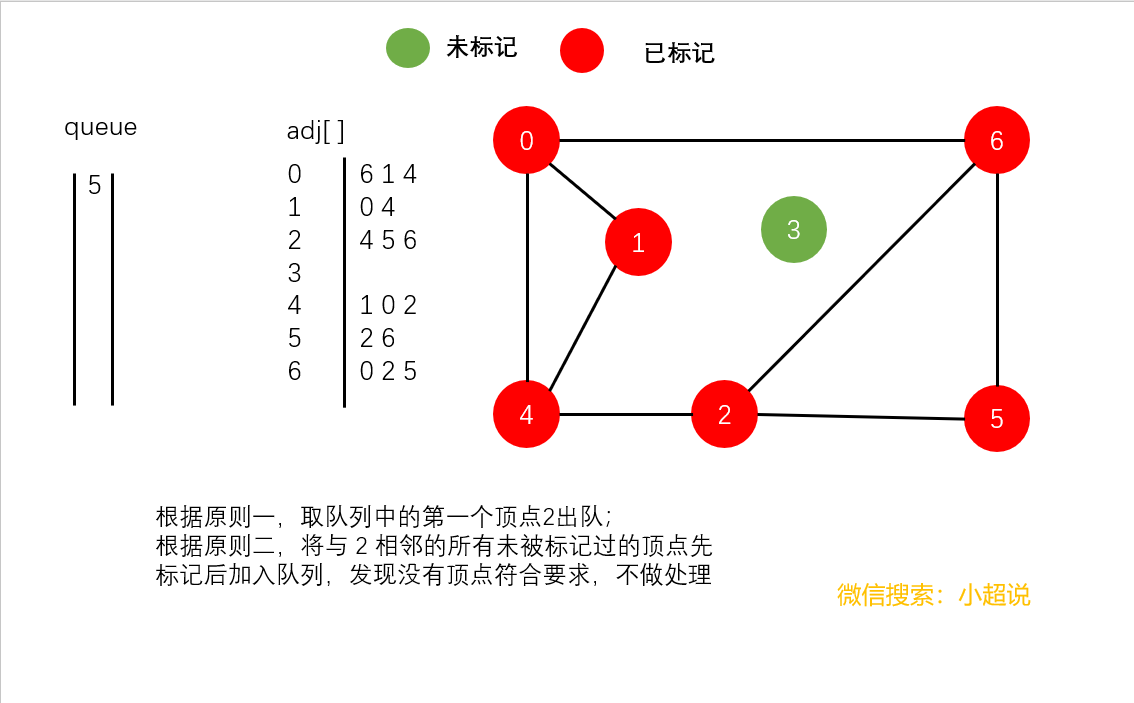
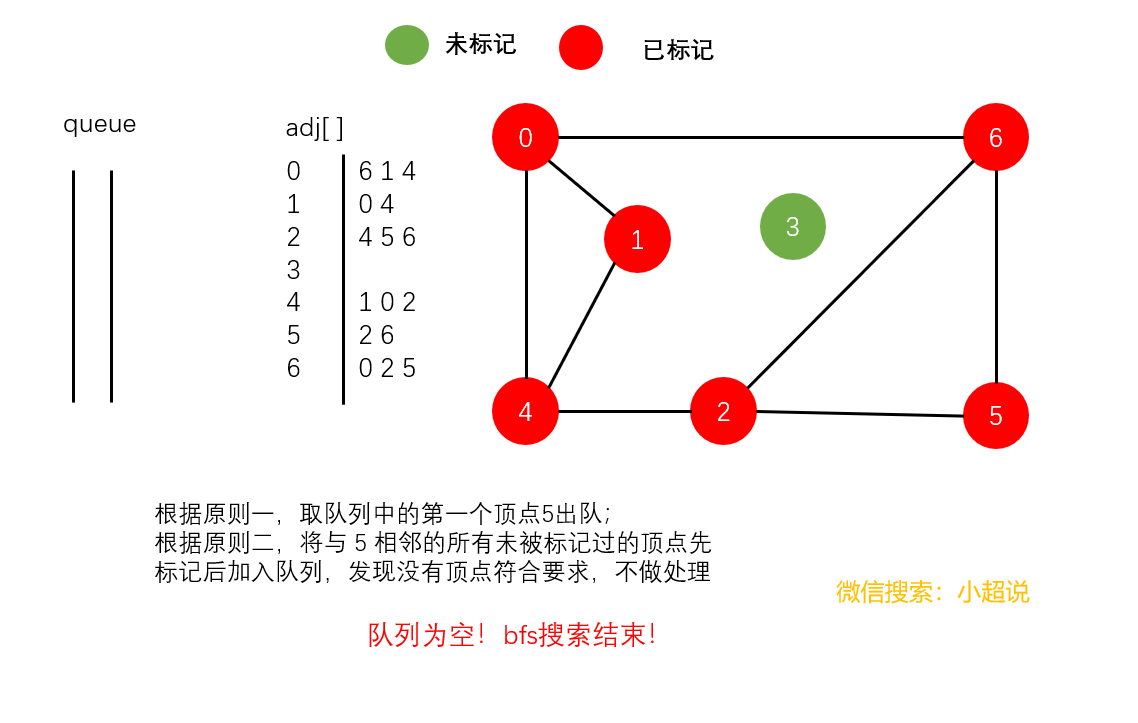
直观地讲,它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。
我相信你在仔细追踪了上图后对广度优先搜索有了一个完整的认识,那么接下来我就附上具体的代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| package Graph;
import java.util.LinkedList;
import java.util.Queue;
public class BreadthFirstSearch {
private boolean[] marked;
private final int s;
public BreadthFirstSearch(Graph G,int s){
marked = new boolean[G.V()];
this.s=s;
bfs(G,s);
}
private void bfs(Graph G,int v){
Queue<Integer> queue = new LinkedList<>();
marked[v]=true;
queue.add(v);
while(!queue.isEmpty()){
int t=queue.poll();
for(int w:G.adj(t)){
if(!marked(w)){
marked[w]=true;
queue.add(w);
}
}
}
}
public boolean marked(int w){
return marked[w];
}
}
|
6.广搜应用(一):查找最短路径
其实只要在广度优先搜索的过程中添加一个整型数组edgeTo[]用来存储走过的路径就可以轻松实现查找最短路径,因为其原理和广搜中的edgeTo[]完全一致,所以这里我就不多说了。
以下是具体的代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| package Graph;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class BreadthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
private final int s;
public BreadthFirstPaths(Graph G,int s){
marked = new boolean[G.V()];
edgeTo = new int[G.V()];
this.s=s;
bfs(G,s);
}
private void bfs(Graph G,int v){
Queue<Integer> queue = new LinkedList<>();
marked[v]=true;
queue.add(v);
while(!queue.isEmpty()){
int t=queue.poll();
for(int w:G.adj(t)){
if(!marked(w)){
edgeTo[w]=t;
marked[w]=true;
queue.add(w);
}
}
}
}
public boolean marked(int w){
return marked[w];
}
public boolean hasPathTo(int v){
return marked[v];
}
public void pathTo(int v){
if(!hasPathTo(v)) System.out.println("不存在路径");;
Stack<Integer> path=new Stack<Integer>();
for(int x=v;x!=s;x=edgeTo[x]){
path.push(x);
}
path.push(s);
while(path.empty()==false)
System.out.print(path.pop()+" ");
System.out.println();
}
}
|
7.广搜应用(二):求任意两顶点间最小距离
设想这样一个问题:给定图中任意两点(u,v),求解它们之间间隔的最小边数。
我们的想法是这样的:以其中一个顶点(比如u)为起点,执行bfs,同时申请一个整型数组distance[]用来记录bfs遍历到的每一个顶点到起点u的最小距离。
关键:假设在bfs期间,顶点x从队列中弹出,并且此时我们会将所有相邻的未访问顶点i{i1,i2……}推回到队列中,同时我们应该更新distance [i] = distance [x] + 1;。它们之间的距离差为1。我们只需要在每一次执行上述进出队列的时候执行这个递推关系式,就能保证distance[]中记录的距离值是正确的!!
请务必仔细思考这个过程,我们很高兴只要保证这一点,就可以达到我们计算最短距离的目的。
以下是我们的代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| package Graph;
import java.util.LinkedList;
import java.util.Queue;
public class getDistance {
private boolean[] marked;
private int [] distance;
private final int s;
public getDistance(Graph G,int s){
marked = new boolean[G.V()];
distance= new int[G.V()];
this.s=s;
bfs(G,s);
}
private void bfs(Graph G,int v){
Queue<Integer> queue = new LinkedList<>();
marked[v]=true;
queue.add(v);
while(!queue.isEmpty()){
int t=queue.poll();
for(int w:G.adj(t)){
if(!marked(w)){
marked[w]=true;
queue.add(w);
distance[w]=distance[t]+1;
}
}
}
}
public boolean marked(int w){
return marked[w];
public void PrintVertexOfDistance(Graph G,int x){
for(int i=0;i<G.V();i++){
if(distance[i]==x){
System.out.print(i+" ");
}
}
System.out.println();
}
}
|
通过上面的方法,我们可以很容易的实现求一个人的三度好友之类的问题,我专门写了一个打印的函数(在上面代码片段最后),它接收一个整型变量int v,可以打印出所有到起点距离为v的顶点。
全文完










