一文彻底掌握二叉查找树
在数据结构中,二叉查找树无疑是极为重要的,但是初学者理解起来却有些吃力,网上的文章讲得也不太全面。本文希望结合多组动图、图片以及详细的代码实现,力争让大家完全掌握二叉查找树(BST)的各种概念和操作。
先看一下本文的目录吧!每个操作都配有动图和详细实现代码(Java)
首先,如果你对树和二叉树的定义不是很了解的话,建议先去看一下这个系列的第一篇文章一文入门二叉树,力求对树有一个基本的认识,再来学习!
背景和必要性
背景
现代计算机和网络使我们能够接触和访问海量的信息,所以高效的检索这些信息将是一个巨大的挑战。这包括信息的存储、处理和查找。这一问题促使我们去研究经典查找算法,即如何高效的存储和查找数据?
目标
实现一个符号表,我们将信息(键-值)储存在符号表里,根据相应的键去查找它所对应的值。你可以把它想象成一个字典,我们在字典中存储了大量的词语的释义,我们应该能够根据词语(索引)去查找这个词语对应的意思。
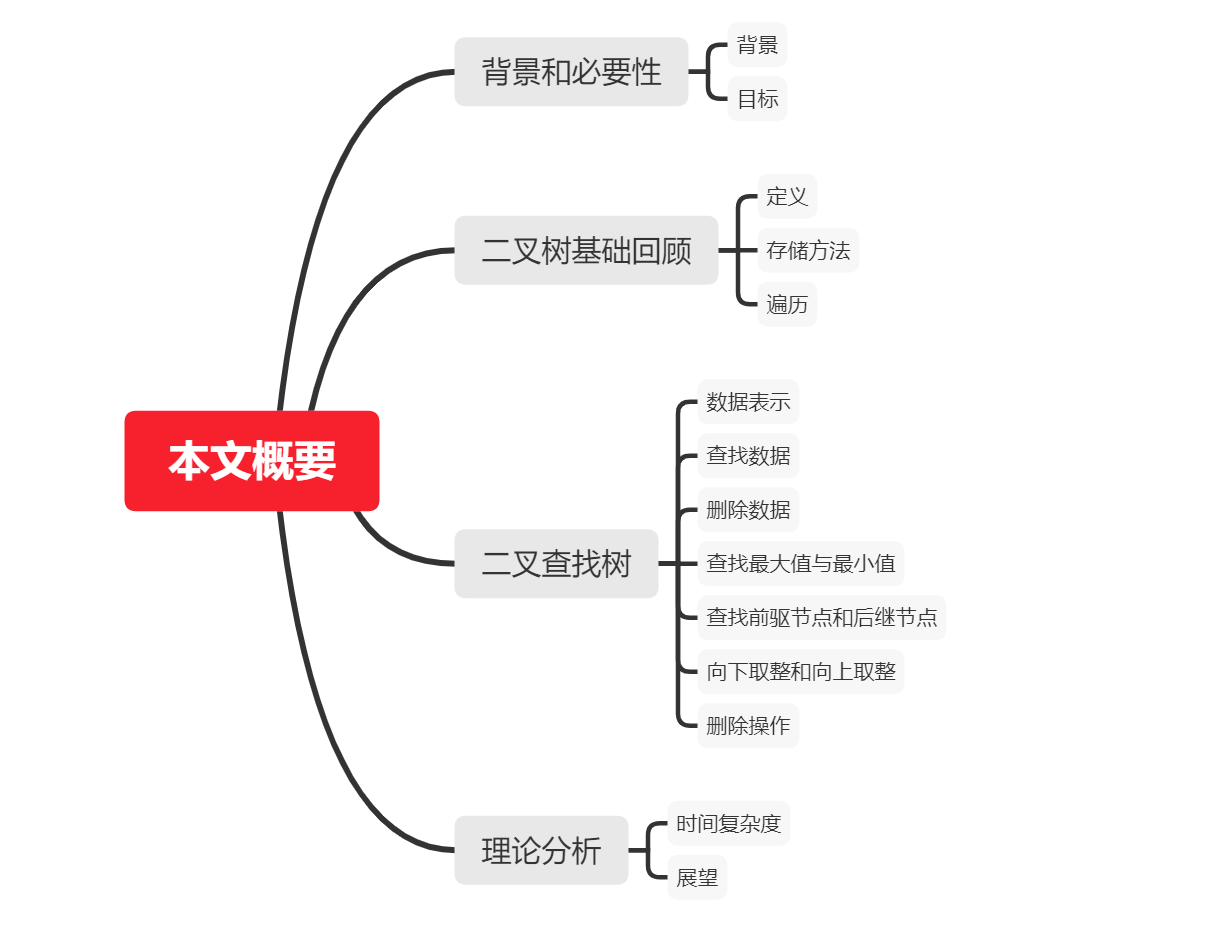
如下图所示,就是一个很简单的符号表,我们可以很轻松的通过键来查找值,但是,基于数组或者链表的这种数据结构并不高效,而且不能较好的维持一定的性质(比如我用数组存储了很多数据,你让我找到最大的那个,我该怎么办呢?先在内部排序再输出,但是,不高效!你是不是会想有没有一种数据结构天然就满足这种性质?)
总结一下,我们希望实现一个高效的符号表,它支持插入、查找、求最大键和最小键、求前驱节点(我们一会再说)和后驱节点等等,它的时间复杂度呢?我们尽量向O(logN)看齐。这就是我们今天的主角–二叉查找树!
二叉树知识回顾
首先,如果你对树和二叉树的定义不是很了解的话,建议先去看一下这个系列的第一篇文章一文入门二叉树,力求对树有一个基本的认识,再来学习
二叉树的定义
直接上几组图,你只需要记住每个节点至多有两个子节点即可。
这几张图几乎代表了所有类型的二叉树,你会发现,最后两个其实就是链表,没错,二叉树成功地退化成了链表,那性能上肯定会下降,但是关于这个问题如何避免却不在本文的范围内,这是下一期文章要解决的问题–[红黑树]。我们在这里只是熟悉一下二叉树的定义就好了。
二叉树的存储方法
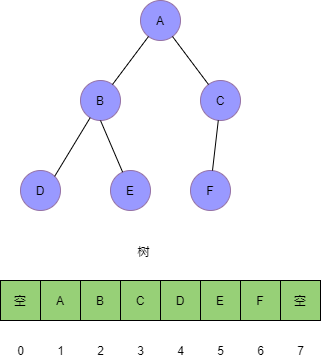
上一篇文章我们就已经介绍过,这里再重复一遍。二叉树的存储方法主要有两种:链式存储法和线性存储法,它们分别对应着链表和数组。完全二叉树最好用数组存放,因为数组下标和父子节点之间存在着完美的对应关系,而且也能够尽最大可能的节省内存,如图一所示。
我们把根节点储存在下标为i=1的位置,那么左子节点储存在2*i=2的位置,右子节点储存在下标为2*i+1=2的位置。依此类推,完成树的存储。借助下标运算,我们可以很轻松的从父节点跳转到左子节点和右子节点或者从任意一个子节点找到它的父节点。如果X的位置为i,则它的两个子节点的下标分别为2i和2i+1,它的父节点的位置为i/2(这里结果向下取整)。
相比用数组存储数据,链式存储法则相应的更加灵活,我们使用自定义类型Node来表示每一个节点。
1 | class Node{ |
每个节点都是一个Node对象,它包含我们所需要存储的数据,指向左子节点的引用,直向右子节点的引用,就像链表一样将整个树串起来。如果该节点没有左子节点,则Node.left==null或者Node.right==null,如图二所示。能理解就行,别在意它的美观度了:)
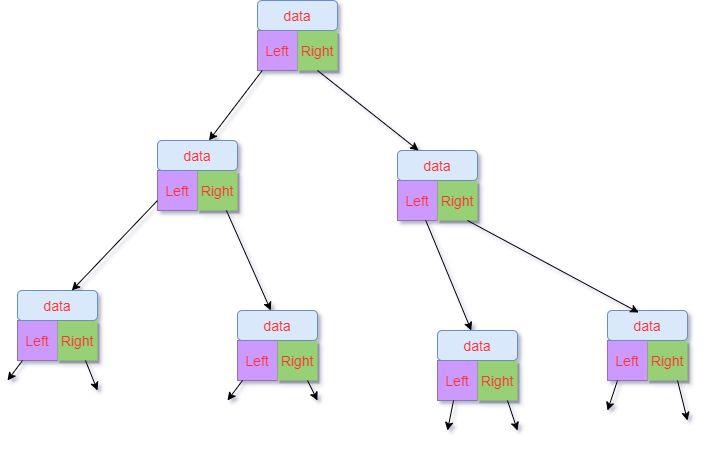
二叉树的遍历
二叉树的遍历有三种方法:前序遍历,中序遍历和后序遍历。在这里我只讲和本文我们实现二叉查找树相关的中序遍历,如果你希望了解更多,请看上一篇文章吧,那里我给出了详细的代码和图示。
所谓中序遍历,就是指:对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。具体的代码是用递归实现的,比较容易理解。
1 | public void inOrder(Node root){ |
你可以结合下面这张图理解一下
以上,我们回顾了二叉树的基本知识,请确保你已经完全掌握。接下来我们将介绍今天的主角 二叉查找树(Binary Search Tree),它是一种符号表,成功地将链表插入的灵活性和有序数组查找的高效性结合起来。听起来是不是很完美?
二叉查找树
一起来看一下它的定义吧,其实只是在二叉树的定义上做了一个小小的限制:
一棵二叉查找树是一棵二叉树,其中每个节点的键都大于它的左子树上的任意节点的键,并且小于右子树上任意节点的键。
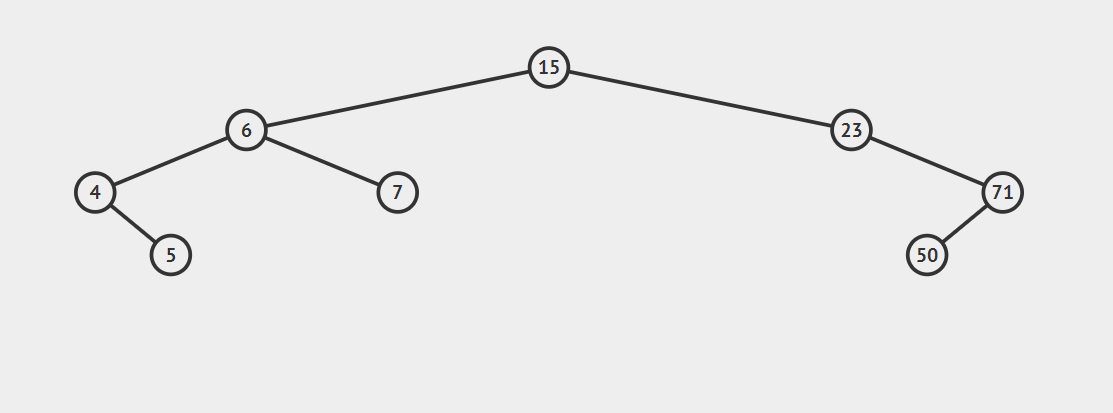
只要按照这个规则,我们构造出来的树就是二叉查找树。现在,请仔细看一下上文所有带数字的树,它们都是二叉查找树。
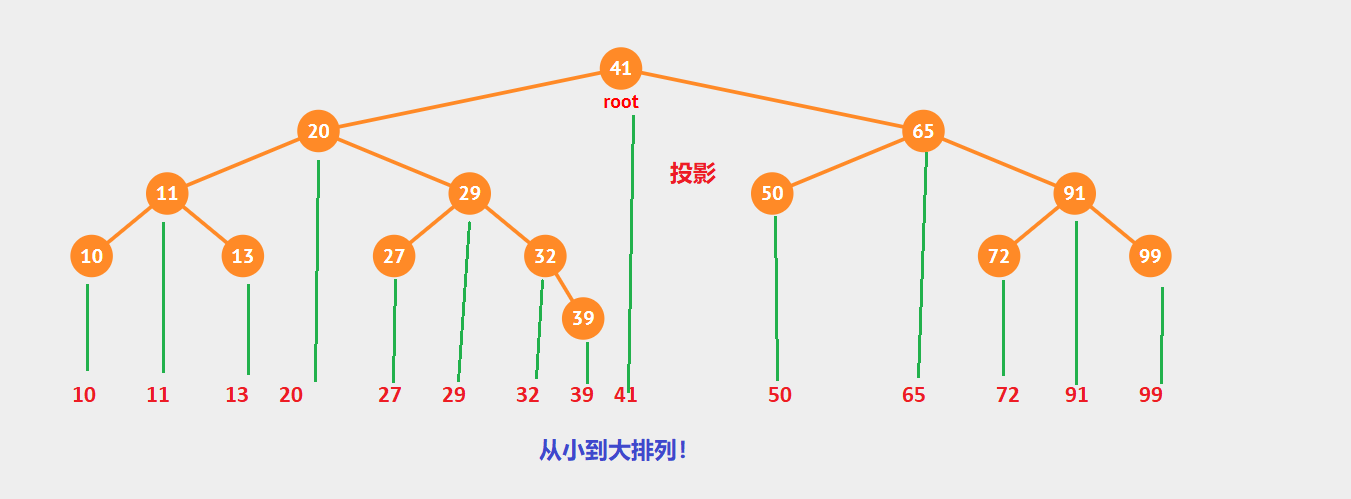
你可能会发现如果我们对二叉查找树进行中序遍历的话,得到的序列是有序的,这是二叉查找树天生的灵活性。具体也可以看一下下面这幅图:
准备完热身运动,接下来我们就正式进入二叉查找树的讲解:)。
- 数据表示
- 查找数据
- 插入数据
- 查找最大值与最小值
- 查找前驱节点和后继节点
- 查找向下取整和向上取整
- 删除操作
数据表示
完全等同于二叉树的链式存储法,我们定义一个节点类Node来表示二叉查找树上的一个节点,每个节点含有一个键,一个值,一个左链接,一个有链接。其中键和值是为了储存和查找,一般来说,给定键,我们能够快速的找到它所对应的值。
1 | private class Node{ |
查找数据
查找操作接受一个键值(key),返回该键值对应的值(value),如果找不到就返回 null。
大致思路是:如果树是空的,则查找未命中,返回null;如果被查找的键和根节点的键相等,查找命中,返回根节点对应的值;如果被查找的键较小,则在左子树中继续查找;如果被查找的键较大,则在右子树中继续查找。我们用递归来实现这个操作,具体的代码如下:
1 | public String find(int key){ |
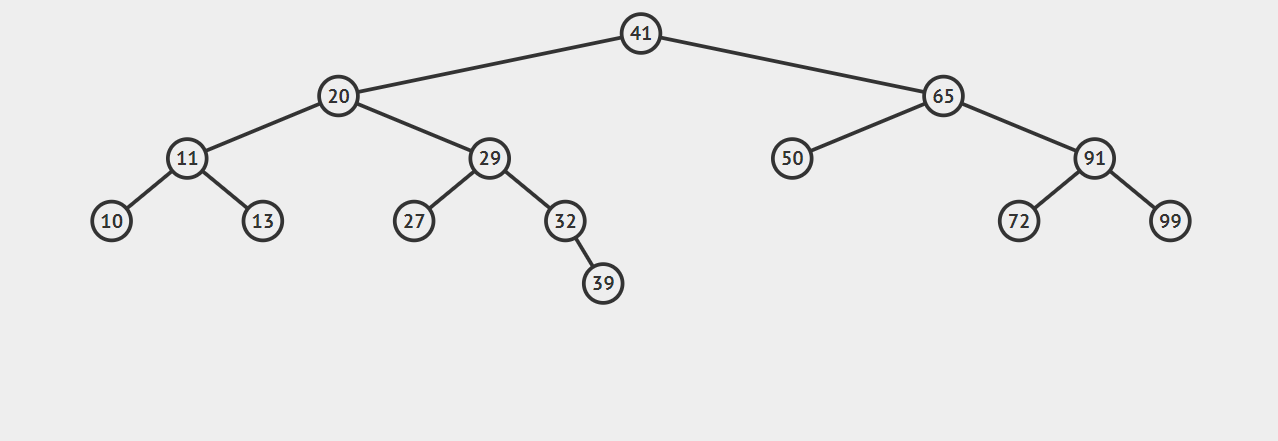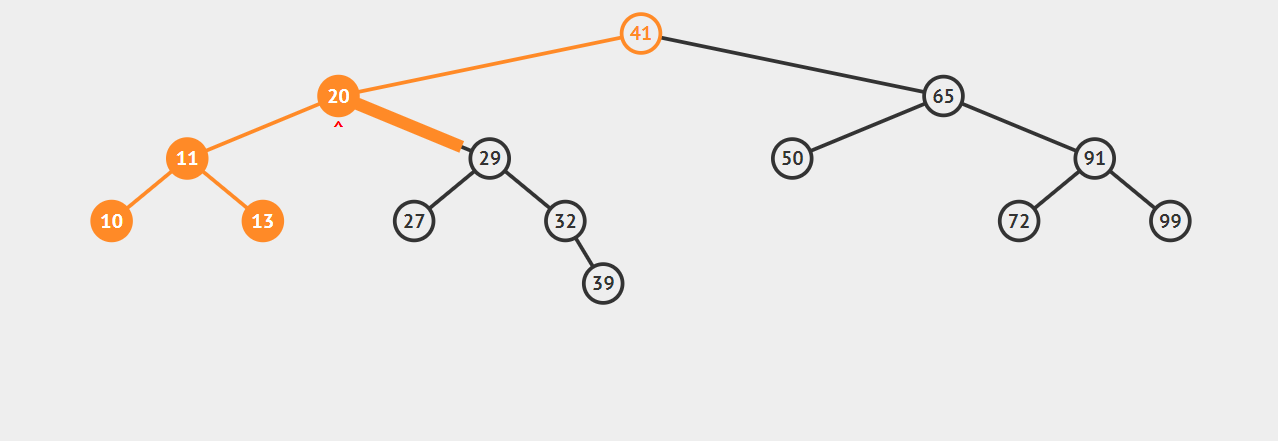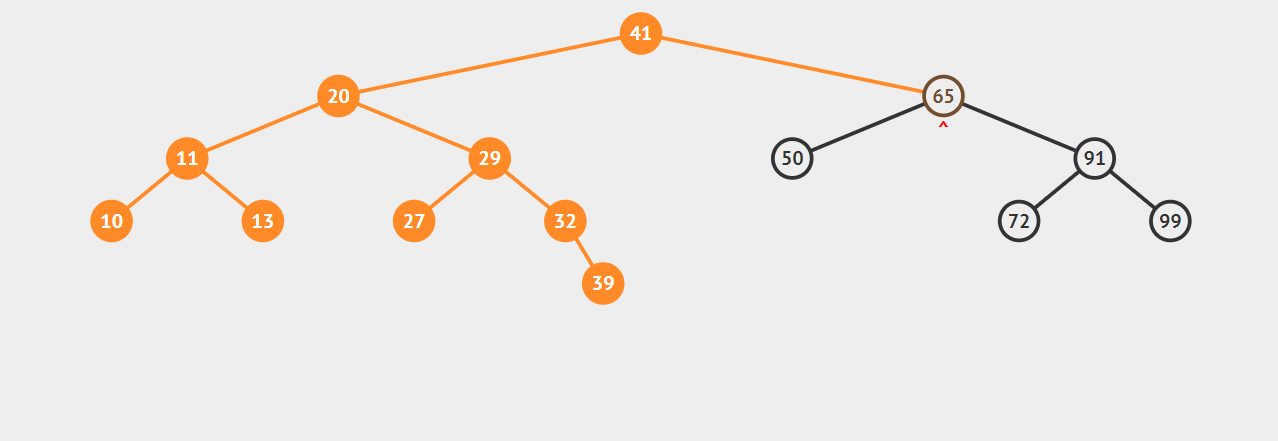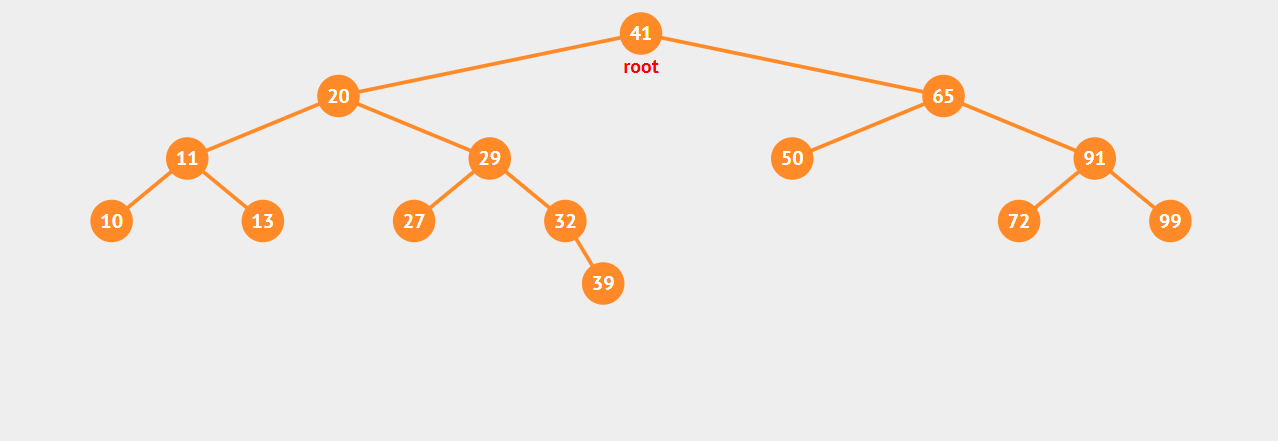
递归代码的实现是很简洁的,比较容易理解,我们来看你一下动图:
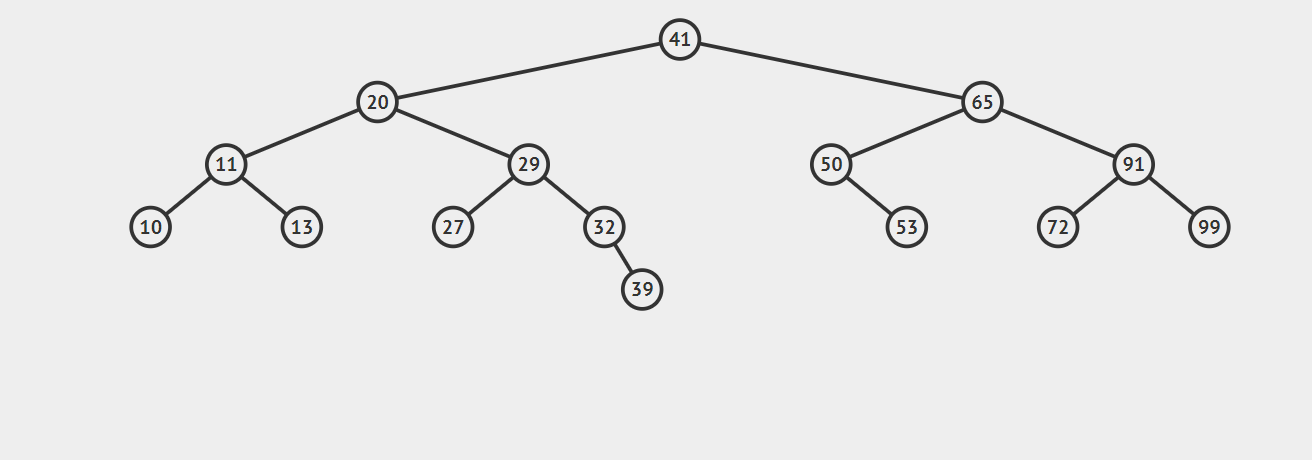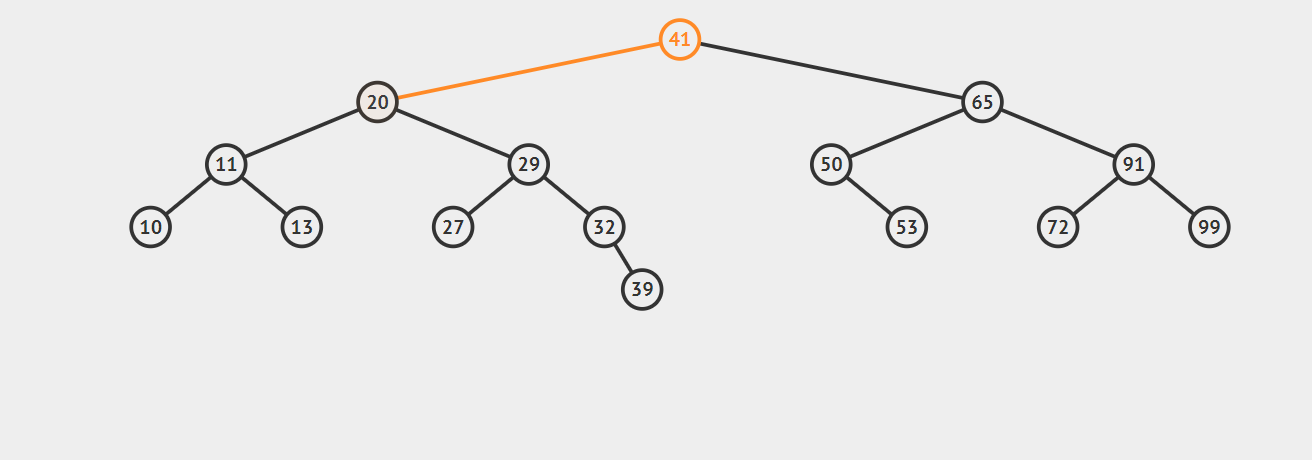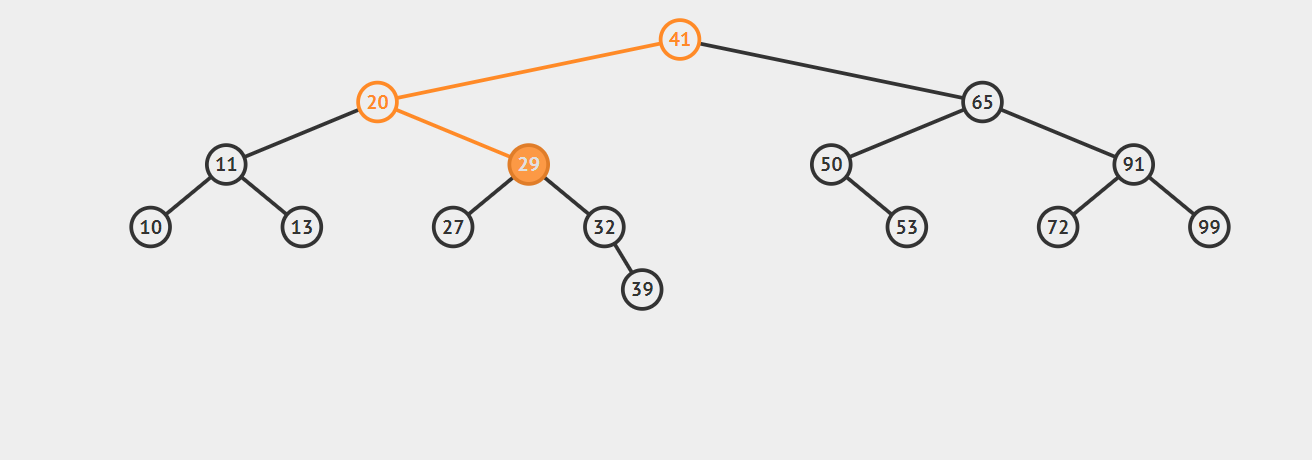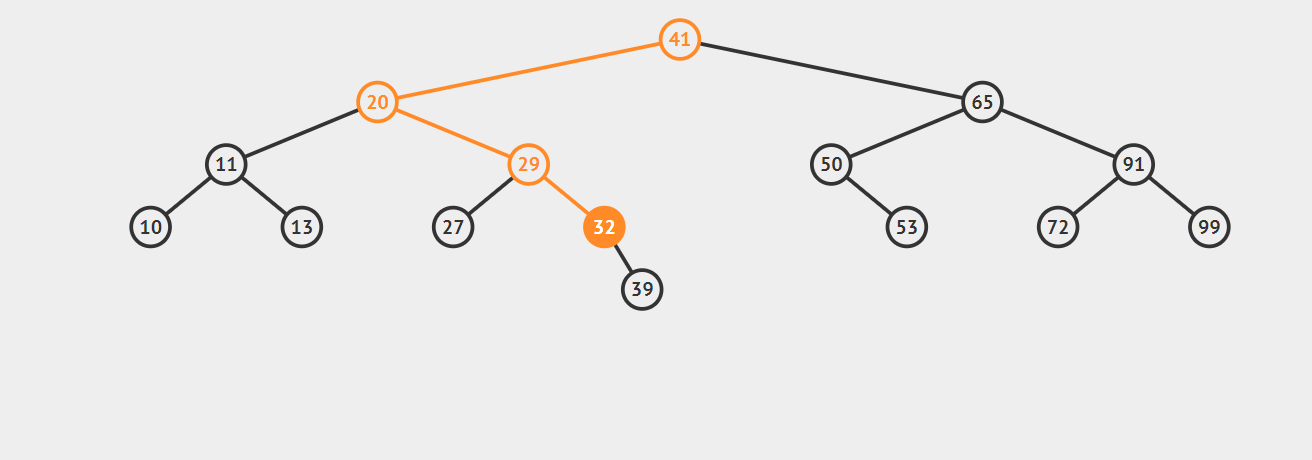
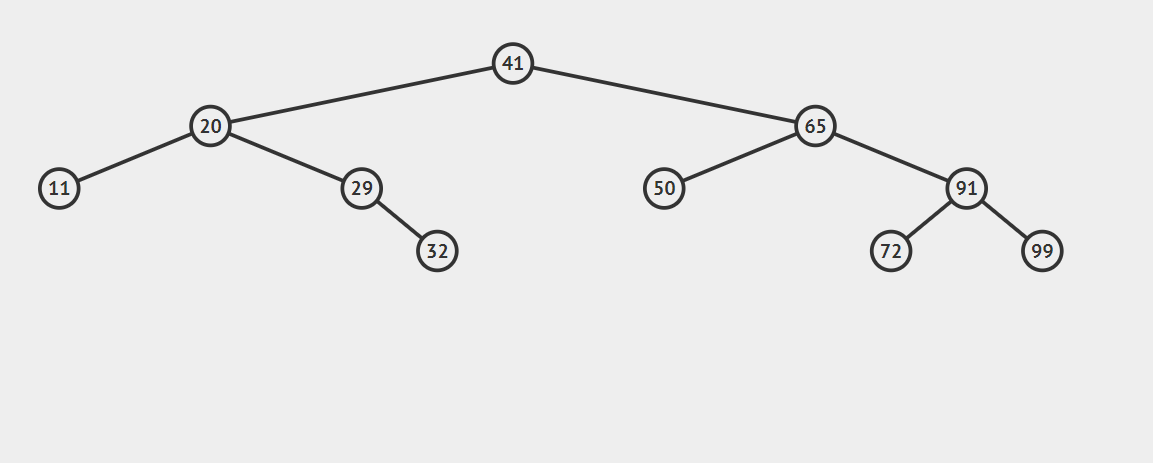
比如我们想查找32,首先,32小于41,所以对41的左子树进行查找,32大于20,再对20的右子树进行查找,紧接着对29的右子树查找,正好命中32,如果查找不到的话就返回null。
插入数据
我们首先判断根节点是不是空节点,如果是空节点,就直接创建一个新的Node对象作为根节点即可;
如果根节点非空,就通过while循环以及p.key和key的大小比较不断向下寻找。循环结束时肯定会找到 一个空位置,这时我们就创建一个新的Node对象并把它接在这里。当然还有一种情况,如果p.key==key,就更新这个键键对应的值,结束。
来一起看下面这个例子,向树中插入31,可以结合着实现方法一(非递归)理解一下:
实现方法一(非递归实现):
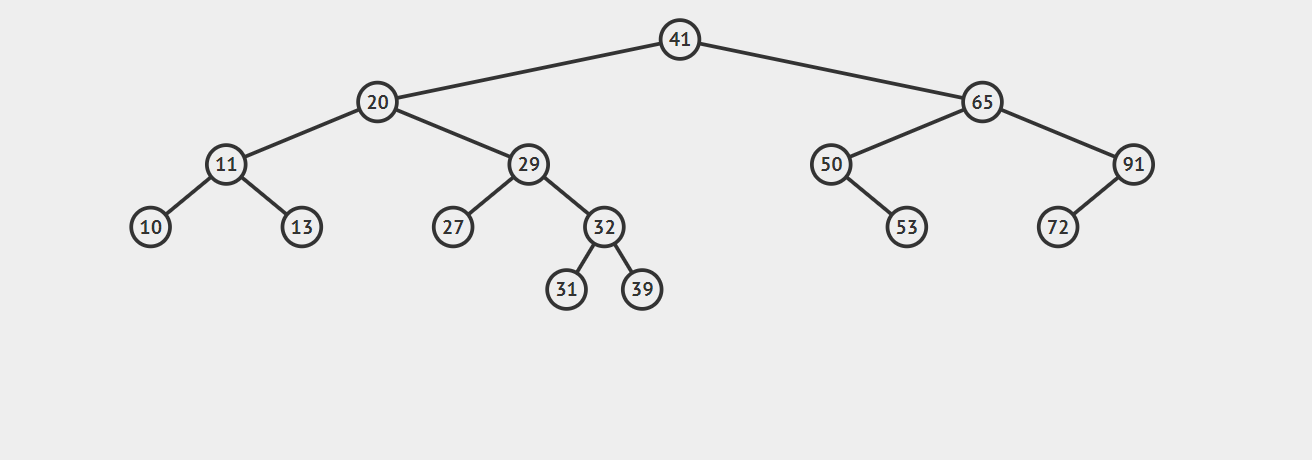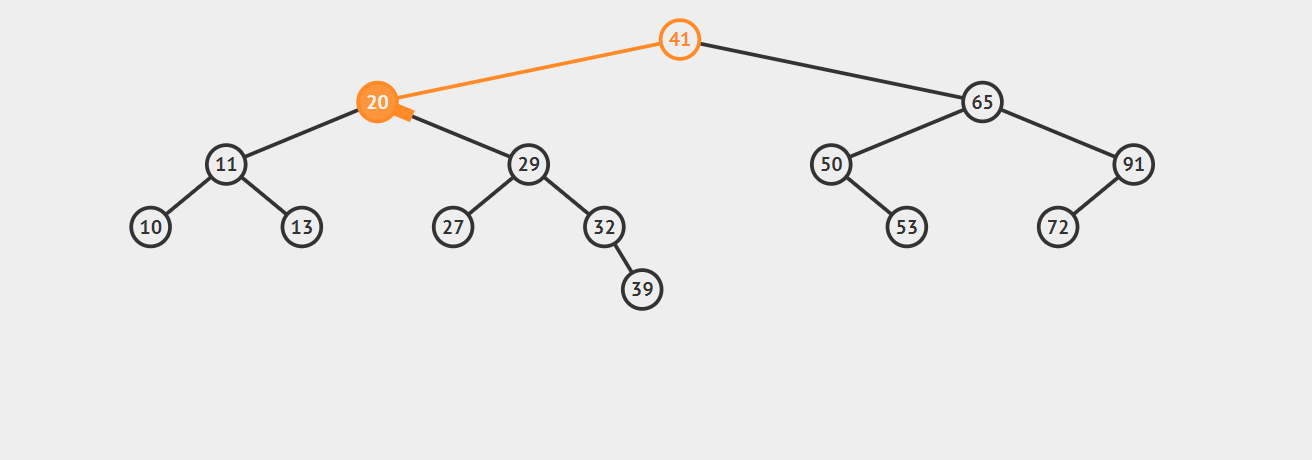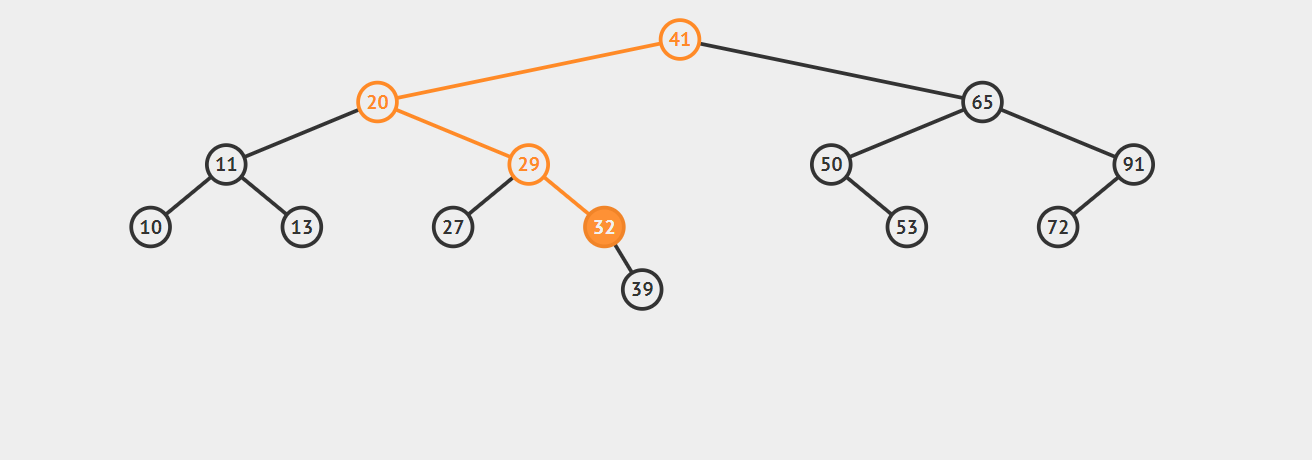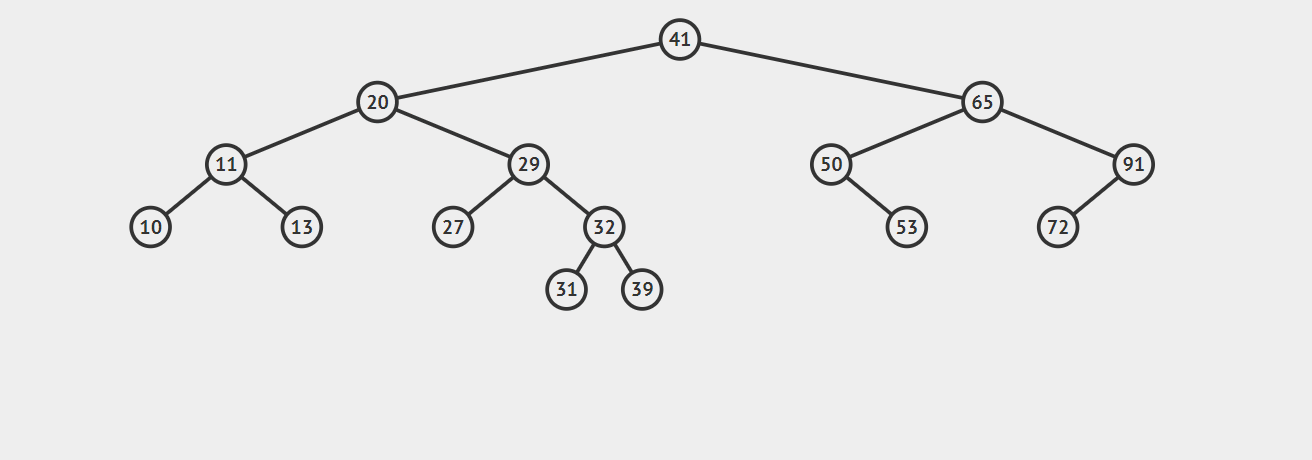
1 | public void insert(int key,String value) { |
实现方法二(递归实现):
1
2
3
4
5
6
7
8
9
10
11
12public void insert(int key,String value){
root=insert(root,key,value);
}
private Node insert(Node x,int key,String value){
//如果key存在于以x为根节点的子树中则更新它的值;
//如果不在就创建新节点插入到合适的位置;
if(x==null) return new Node(key,value);
if(key<x.key) x.left=insert(x.left,key,value);
else if(key>x.key) x.right=insert(x.right,key,value);
else x.value=value;
return x;
}
这个递归的代码尽管很简洁,但却不是那么容易理解。
我先说一下写递归算法需要注意的问题:
- 1.一个问题的解可以分解为几个子问题的解何为子问题
- 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
- 3.存在递归终止条件
PS:关键在于写出递推公式,找到终止条件
在这里,递推公式就是根据条件判断。然后将根节点对应的树转化为规模小一点的左子树或右子树,终止条件就是遇到空链接
如果实在绕脑子,你只需要理解第一种非递归的方法就行了:)。
查找最大值和最小值
这个操作应该是最简单的了。根据二叉查找树的定义,最小值就是最左边的元素,直接从根节点一直向左查找即可。它也有两种实现方式,具体的代码如下:
实现一(递归实现)
1 | public int min(){ |
实现二(非递归实现)
1 | public int min() |
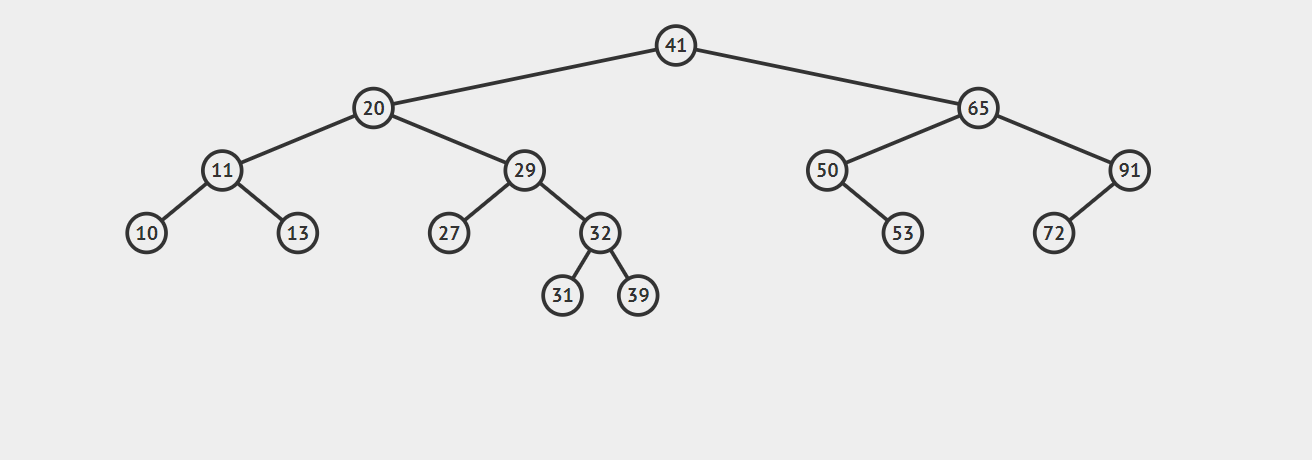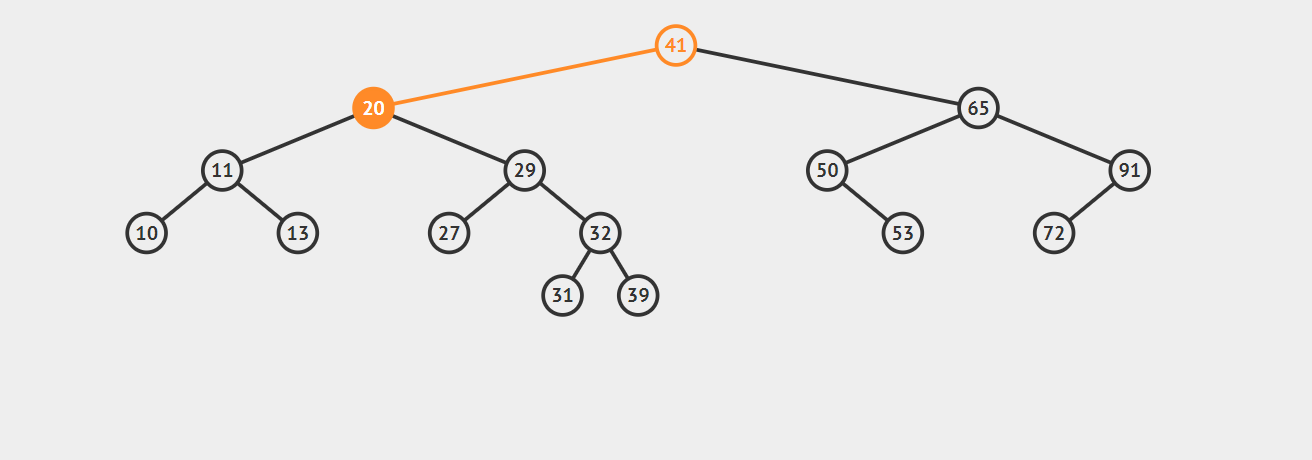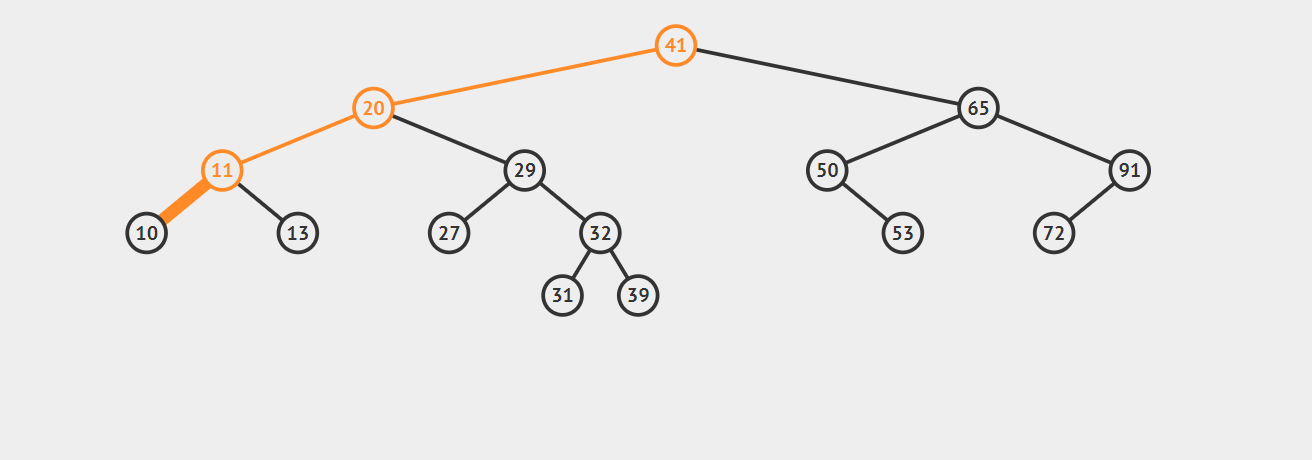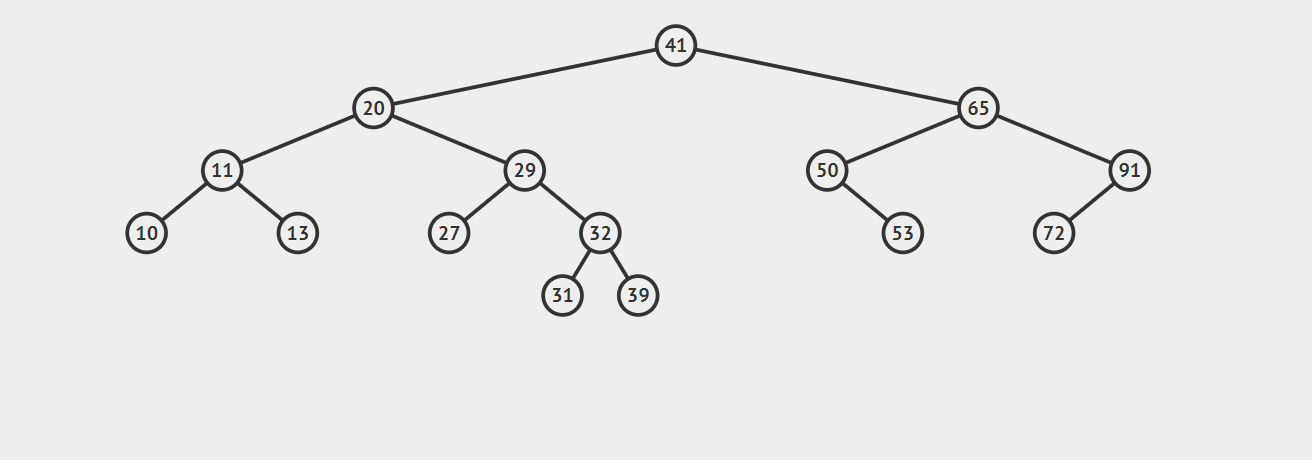
以下是动图演示:
查找最大元素的道理类似,只需把left换成right即可,在这里就不再多说了,就当给你留的一个作业了:)。
查找前驱节点和后继节点
前驱节点指的是小于该键的最大键,后继节点指的是大于该键的最小键。你可以结合中序遍历理解,通过中序遍历,在得到的序列中位于该点左侧的就是前驱节点,右侧的就是后驱节点。
举个例子,如图所示:
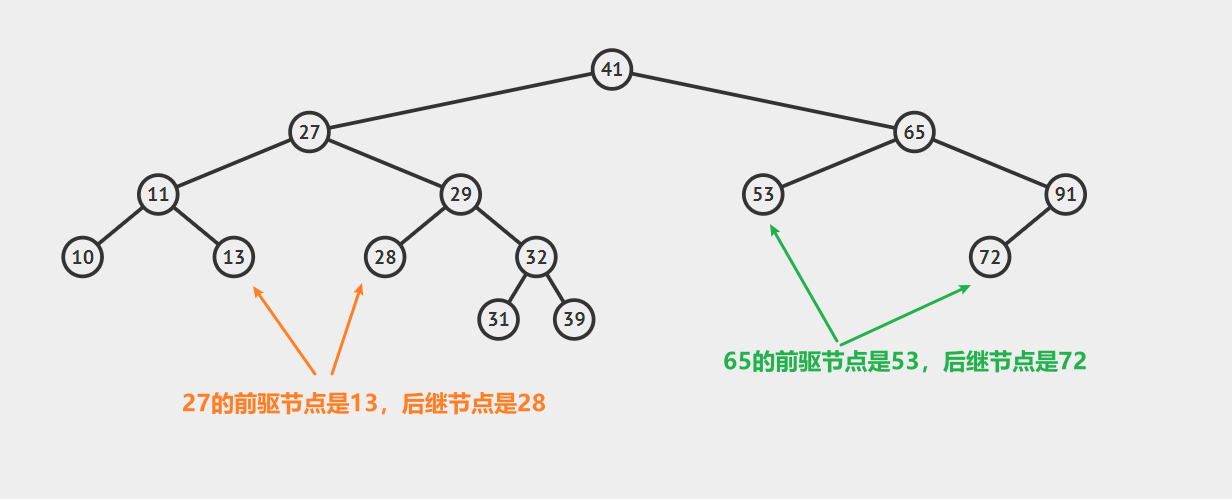
我们首先介绍以下前驱节点的性质:
1.若一个节点有左子树,那么该节点的前驱节点是其左子树中最大的节点(也就是左子树中最右边的那个节点),示例如下:

2.若一个节点没有左子树,那么判断该节点和其父节点的关系
- 2.1 若该节点是其父节点的右子节点,那么该节点的前驱结点即为其父节点。 示例如下:
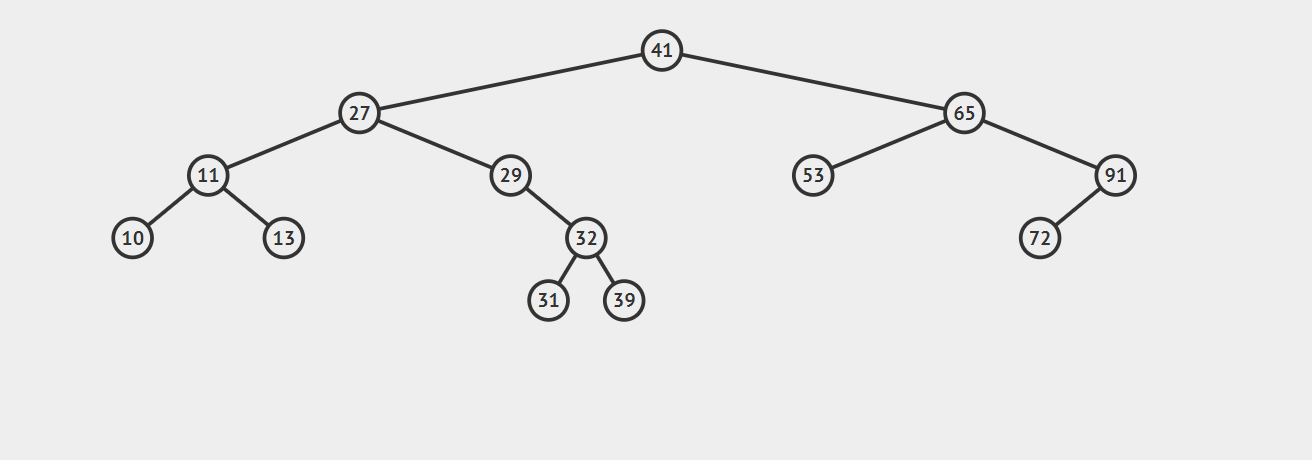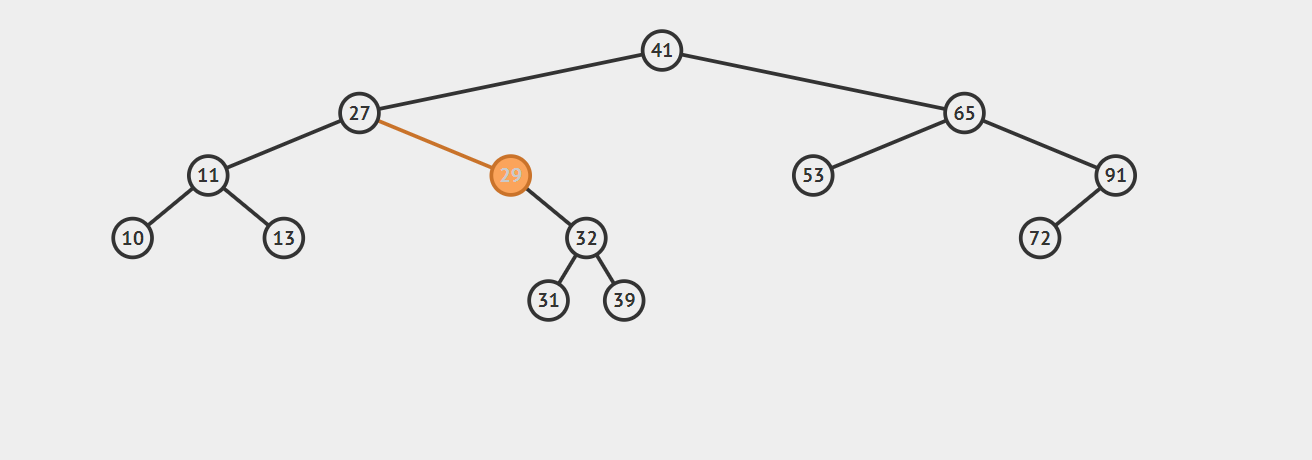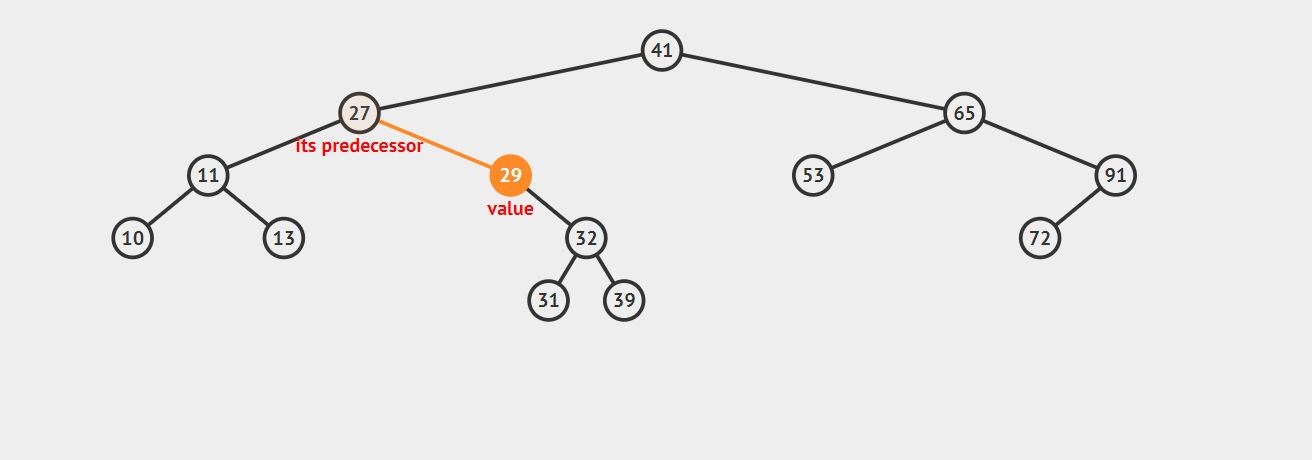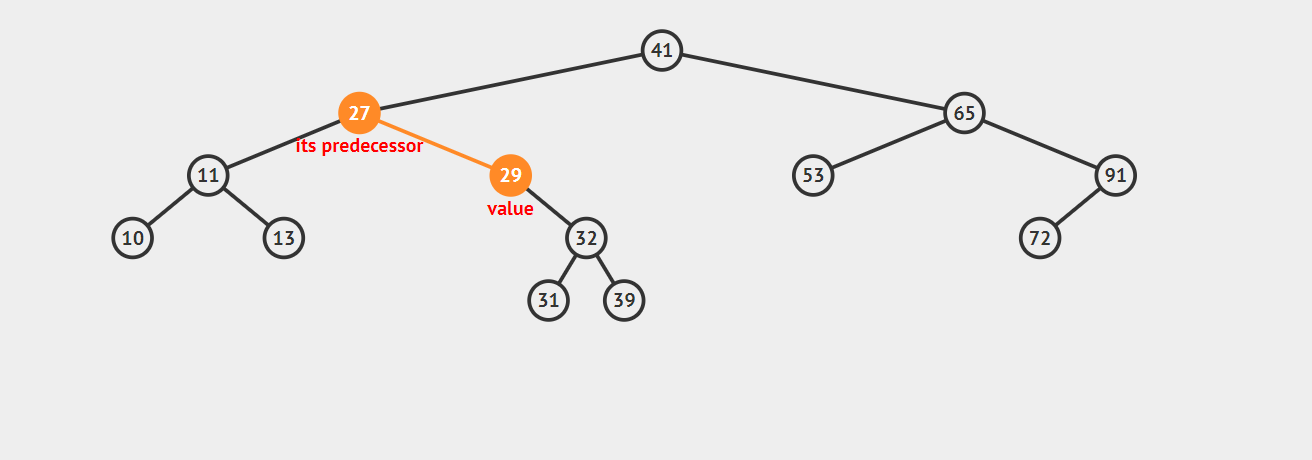
- 2.2 若该节点是其父节点的左子节点,那么需要沿着其父亲节点一直向树的顶端寻找,直到找到一个节点P,P节点是其父节点Q的右子节点,那么Q就是该节点的后继节点,示例如下:
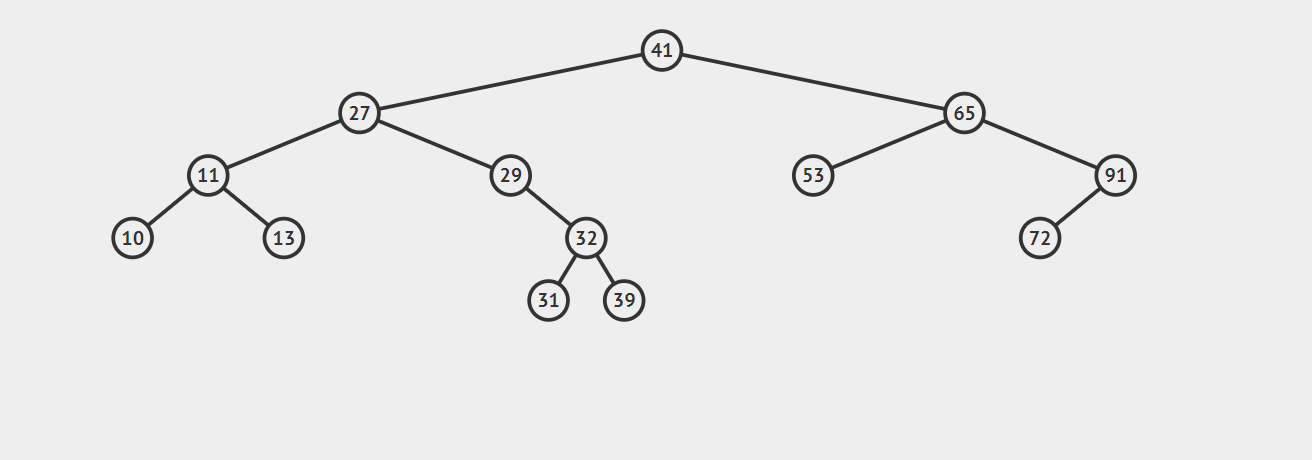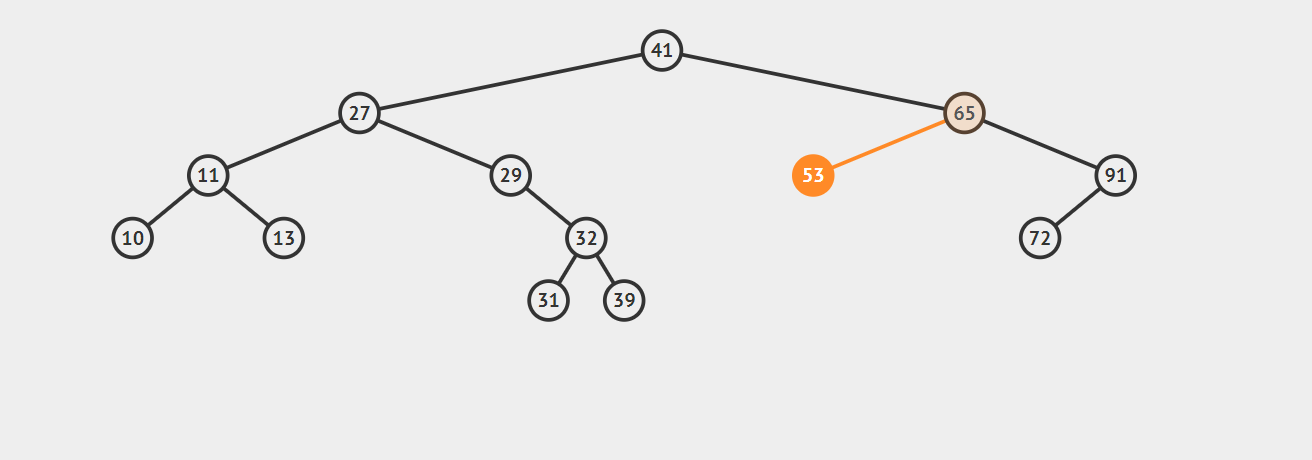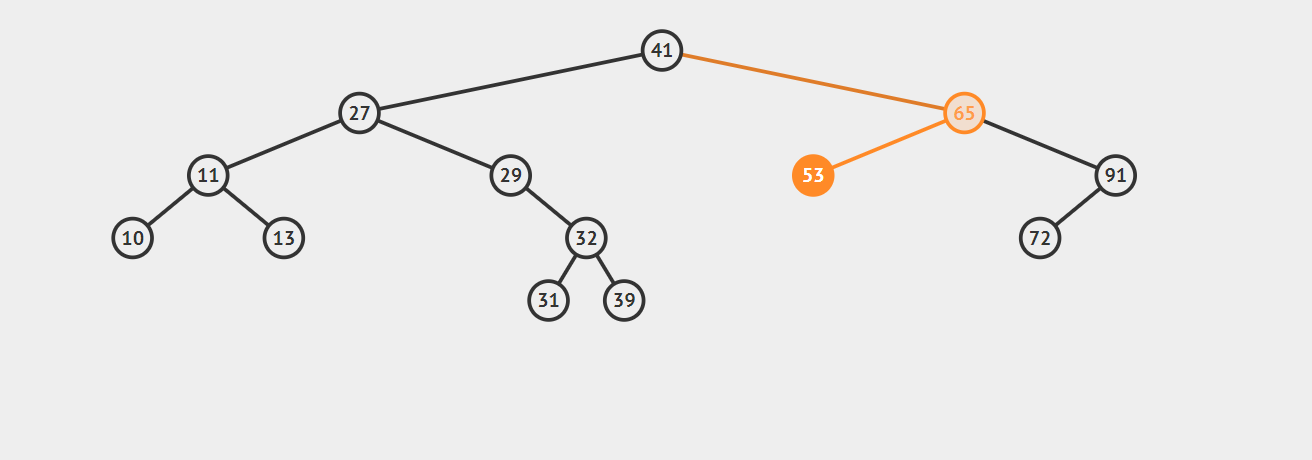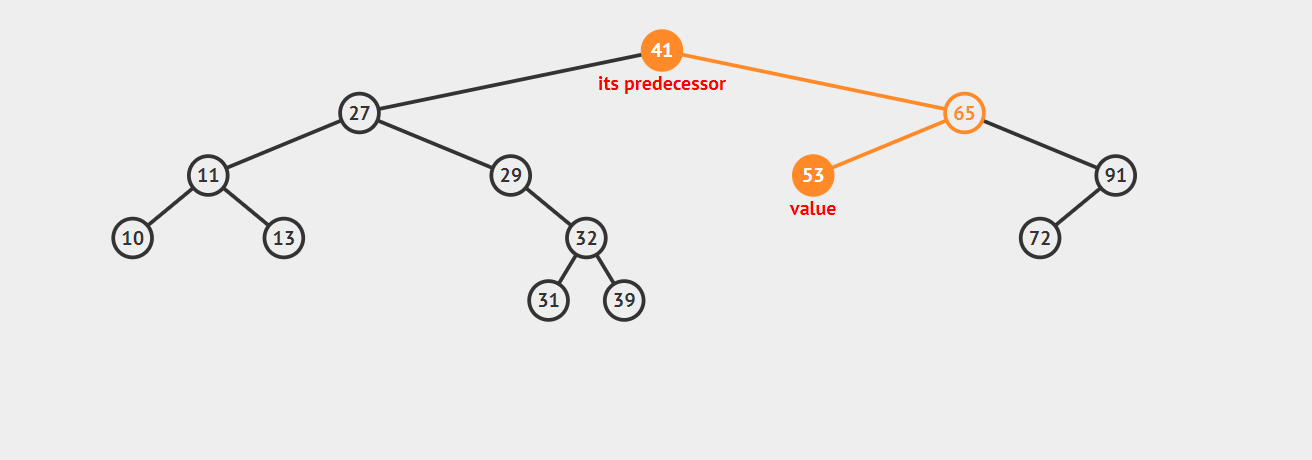
以上就是寻找的思路,不过实际上我们还有一步操作,就是找到这个给定的节点,在这个过程中,我们同时记录最近的一个向右走的节点first_parent。具体的代码如下(已测试):
1 | public int get_prenode(int key) |
向上取整和向下取整
向上取整是指大于等于该键的最小键,向下取整是指小于等于该键的最小值。
向下取整与前驱后继节点的区别在于查找前驱后继节点对应的参数是树中的某一个节点键,而向下取整则允许接受任意的键作为参数,另一方面,向下取整可以包含等于自己的键,是小于等于
关于向上取整与向下取整这两个操作,我只在算法(第四版)上面见到过,在其他的相关文章中没有遇到,不过我感觉咱们可以体会一下它的思想,毕竟我感觉这个操作也蛮重要的。
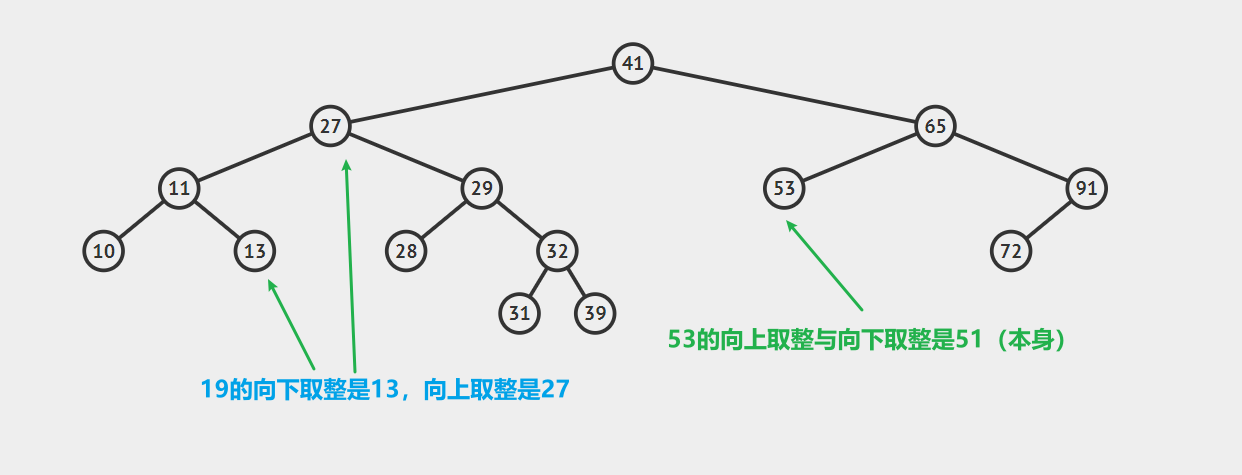
我们拿上图中查找19前驱节点为例说明一下流程:首先,在以41为根节点的树中查询,由于19<41,在41的左子树查询,即在以20为根节点的树中查询。接着因为19<20,继续向左,在以11为根结点的树中查询。集中注意力,因为19>11,所以11有可能是19的前驱节点,但是前提是11的右子树中没有比19小的元素。也就是说**我们应该先在11的右子树中寻找,然后判断寻找的情况(命中或未命中),如果命中,那就自动返回结果了,如果没有命中,则说明11就是19的前驱节点!**,这其中查找的过程是一个递归的过程!希望你仔细体会:)
我只能说到这里了,不好理解:(。具体实现如下:
1 | public int floor(int key){ |
向上取整的代码类似,我这里就不详细说了,你可以自己实现一下。
删除操作
二叉树的删除操作就相对比较复杂了。希望你打起十二分的精神!删除一个结点只会对一颗二叉查找树的局部产生一定的影响,所以,我们的任务就是恢复删除这个结点所带来的影响。
删除操作也有递归算法,不过我很迷,而且我见很多地方也不是用递归实现的,所以这里就不再介绍了,感兴趣的话可以看一下算法(第四版),上面有详细的介绍。好了,不啰嗦了,咱们继续~
针对待删除结点的子节点个数的不同,我们将它分为三种情况加以处理。
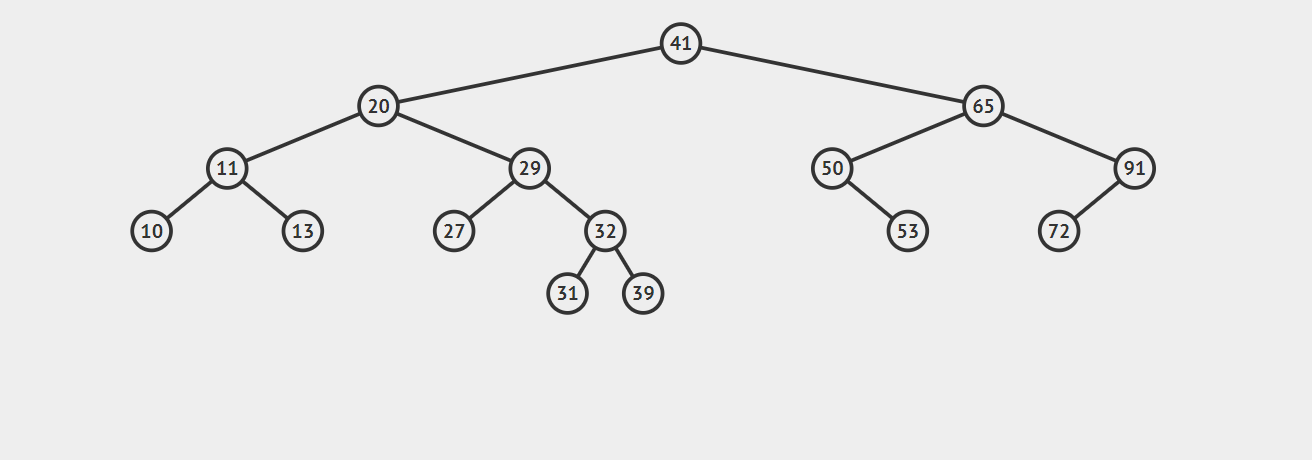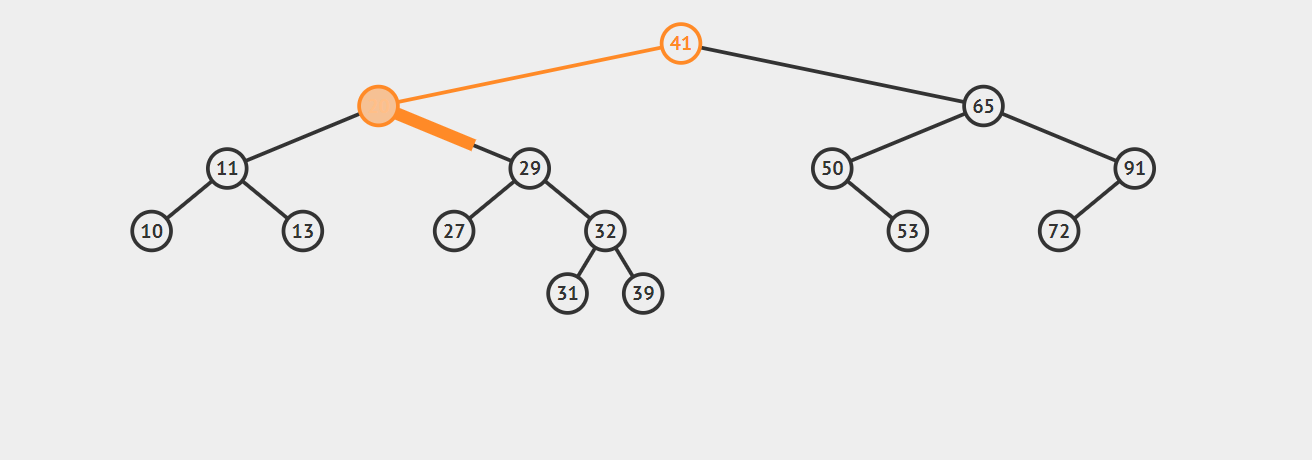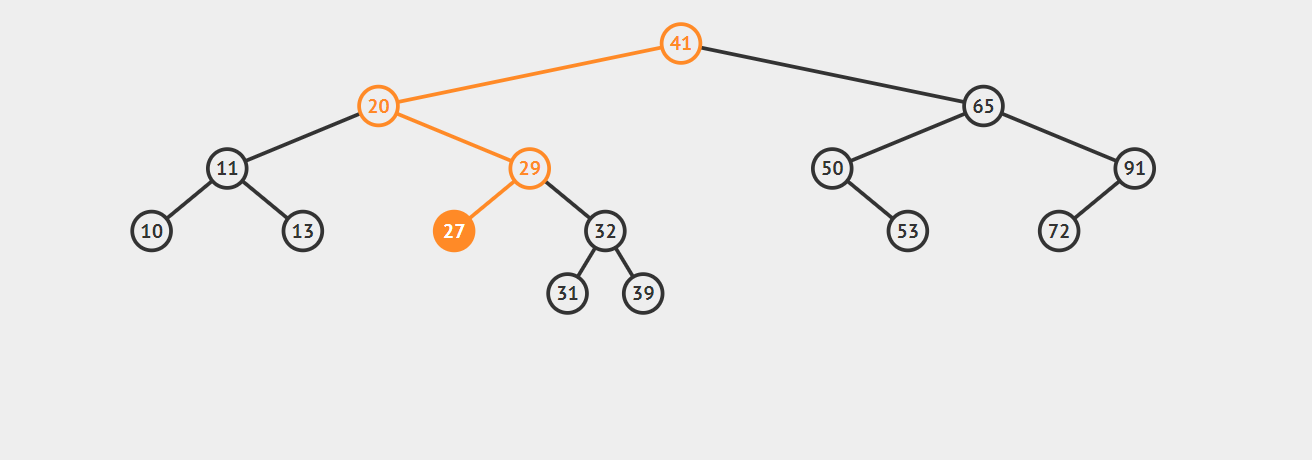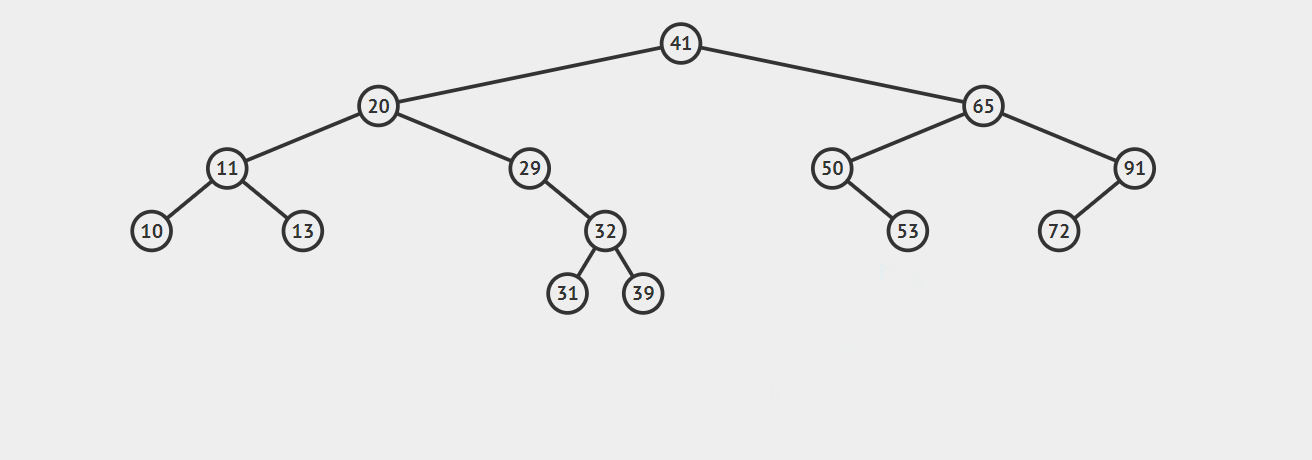
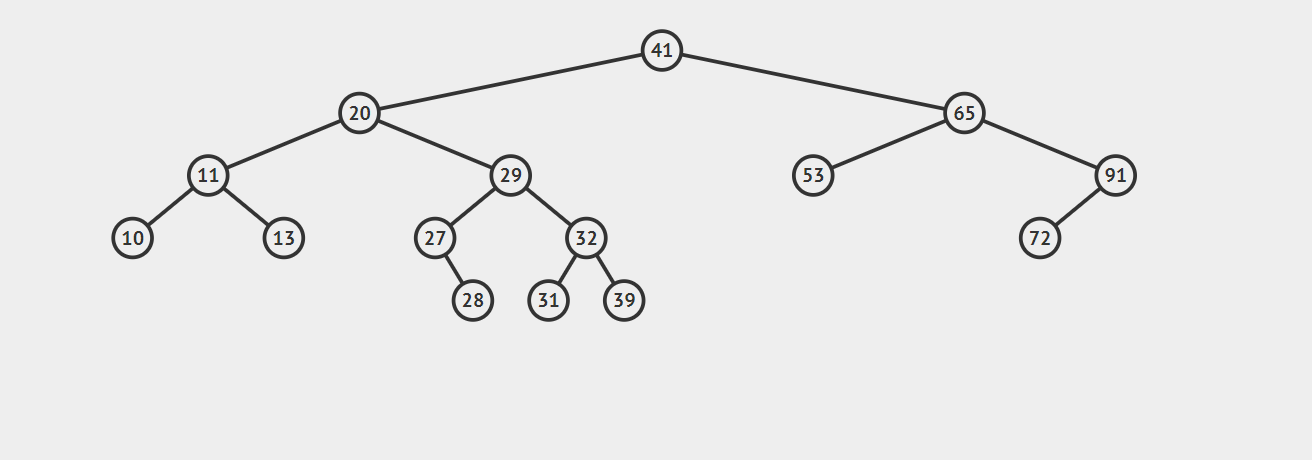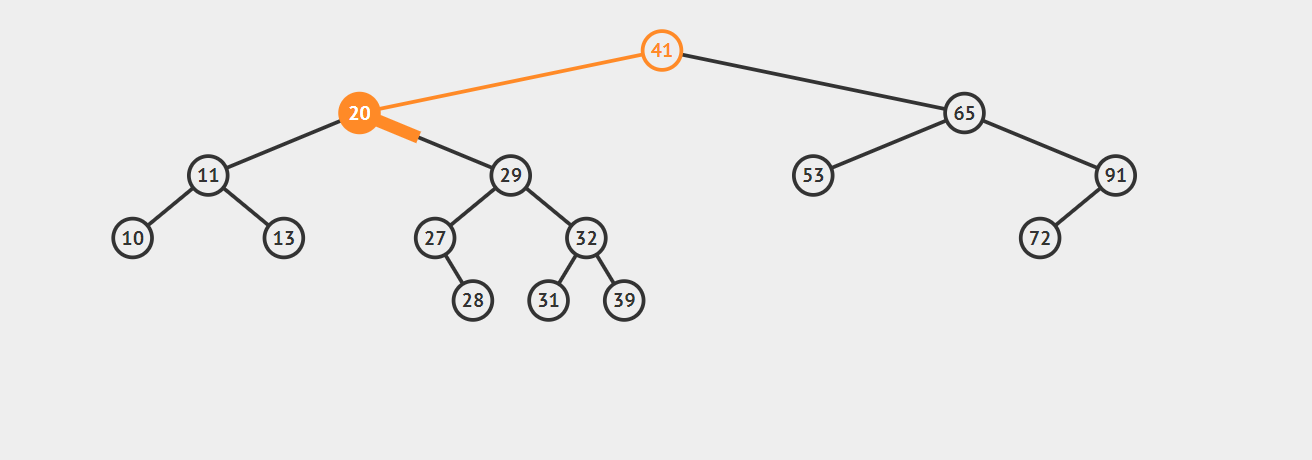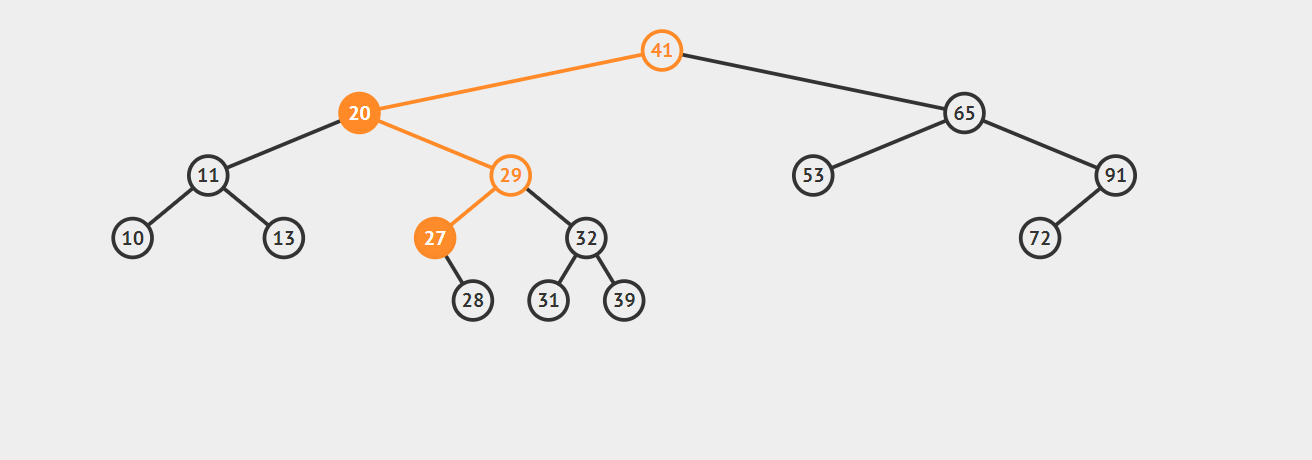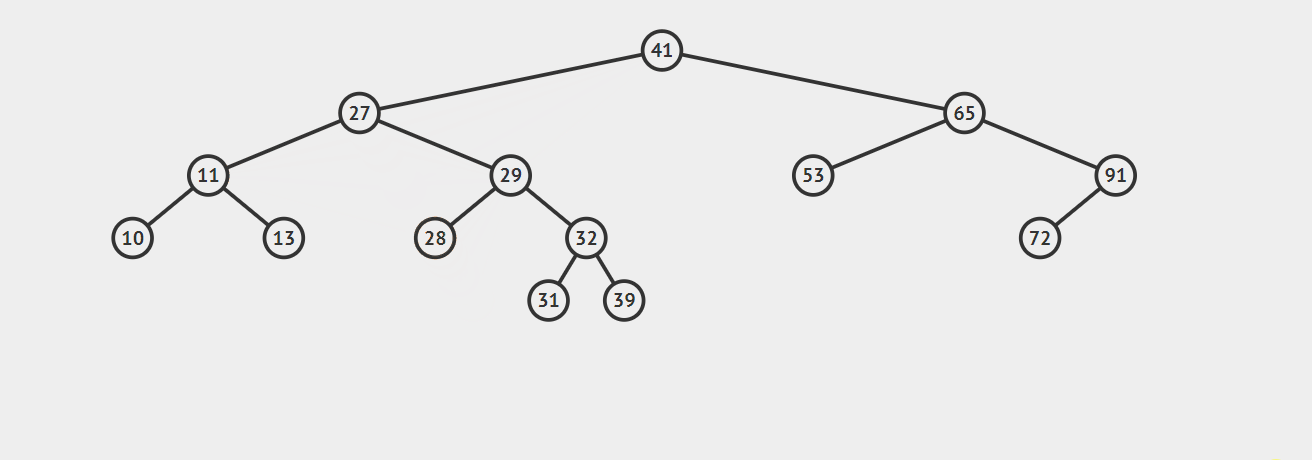
1.如果要删除的结点没有子节点,此时的操作时十分容易的,我们只需要将父节点中指向该节点的链接设置为null就可以了。请看下图,我们的任务是删除结点27,找到这个节点后直接抹去就 OK 了。
2.如果要删除的节点只有一个子节点(只有左子节点或只有右子节点),这种情况也不复杂。我们只需要更新父节点中的指向待删除结点的链接即可,让它指向待删除结点的子节点即可。请看下图,我们的目标是删除节点50:
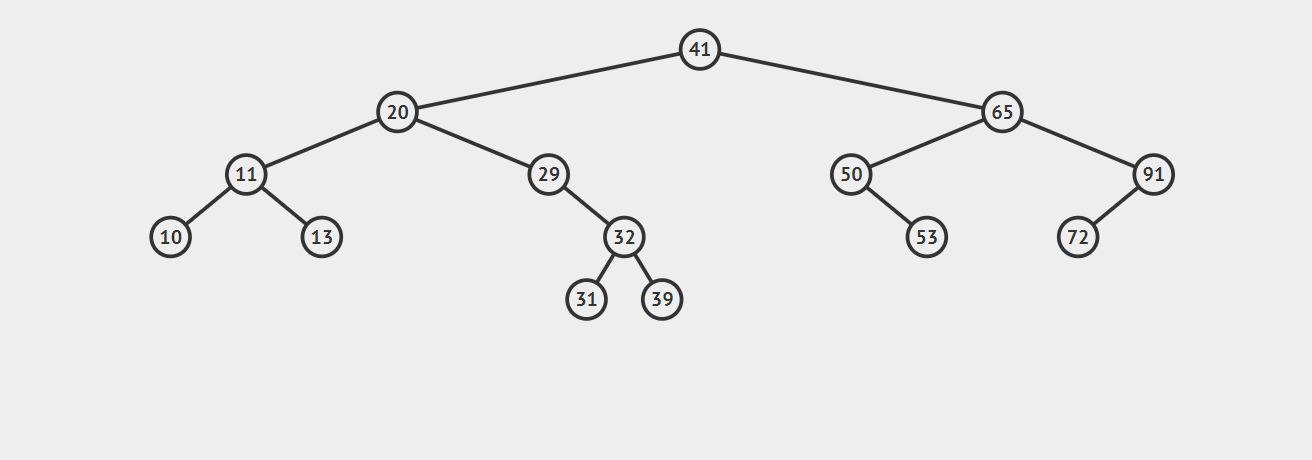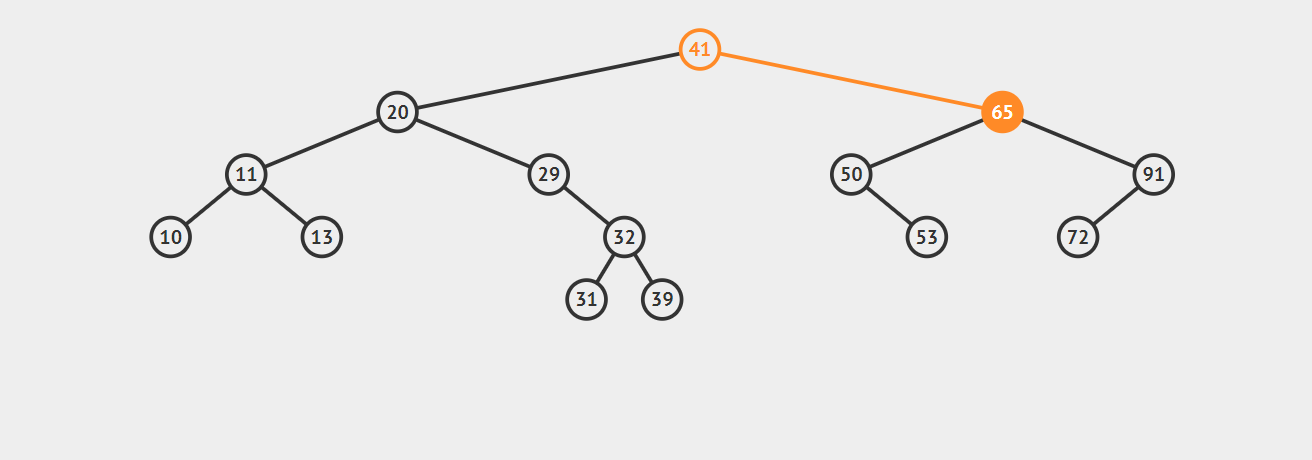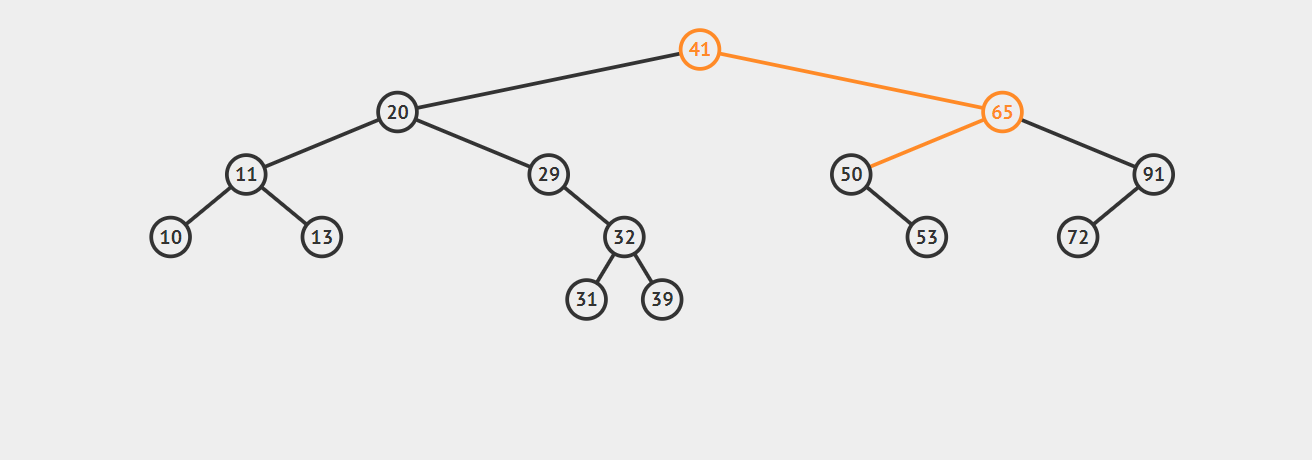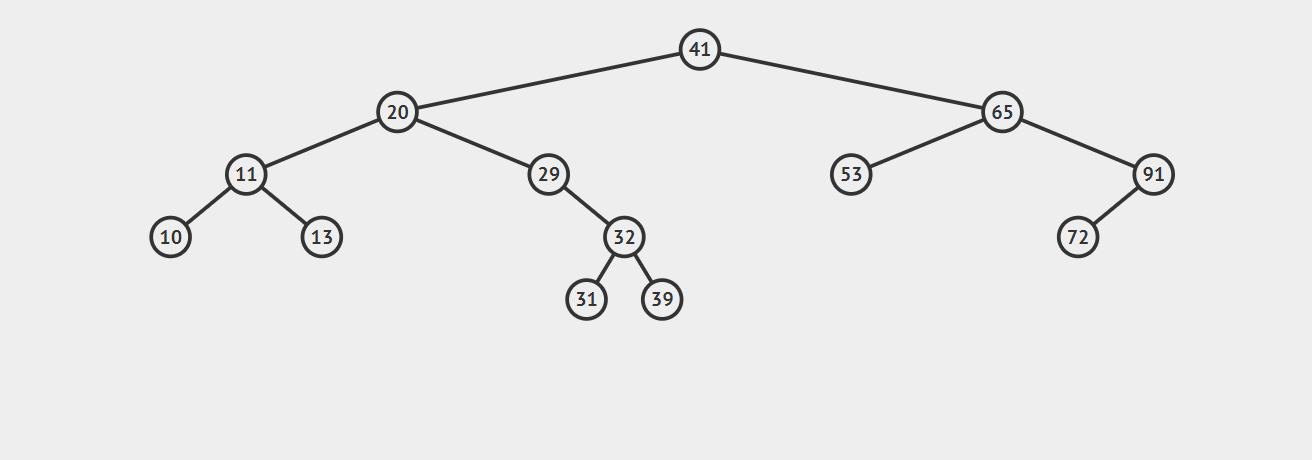
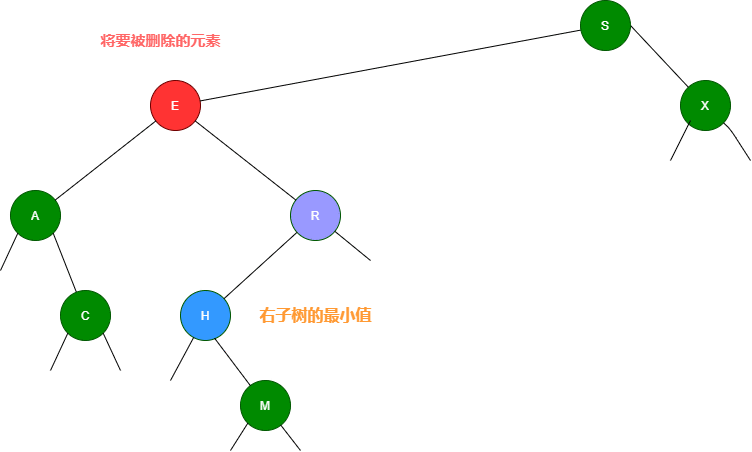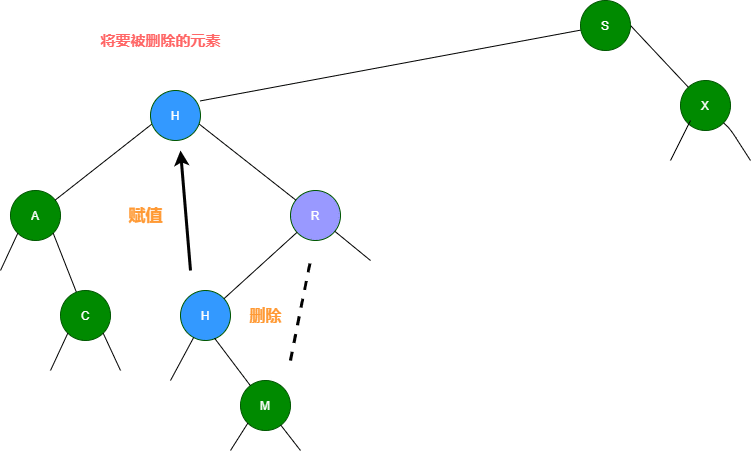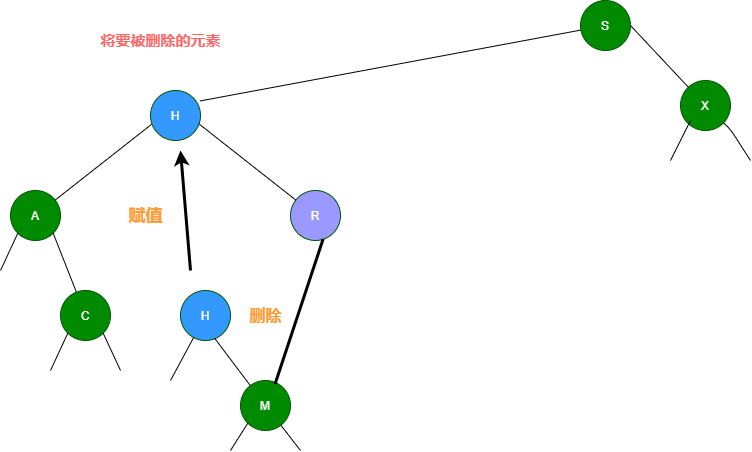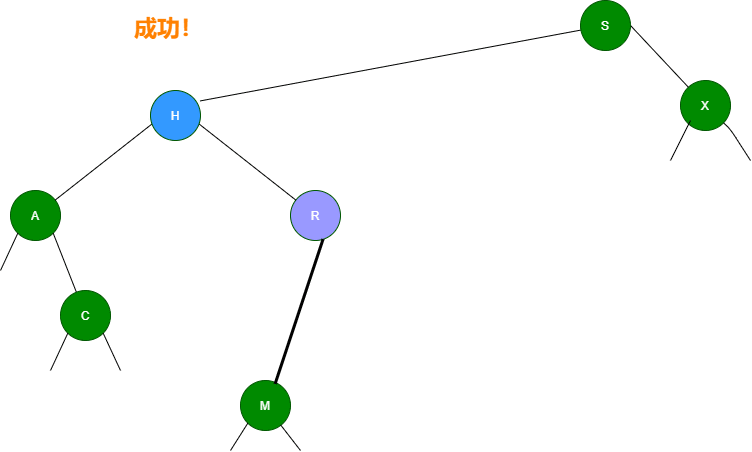
3.如果要删除的节点有两个子节点,这时就变得复杂了。你听我仔细描述以下这个过程:我们需要找到这个节点的右子树上的最小结点【记为H】(因为它没有左子节点),把【H】替换到我们计划删除的节点上;然后,再删除这个最小的节点【H】(因为它没有左子节点,所以可以转化成之前的两种情况之一),而且,你会发现,二叉查找树的性质被完美的保留了下来,惊不惊喜!
接下来请看下面这三个例子,它们分别能够转化为情况一和情况二:
第一幅图,想要删除节点20,它的右子树的最小节点【H】没有子节点
第二幅图,想要删除节点20,它的右子树的最小节点【H】存在右节点
注意:【H】不可能有左节点,因为它是最小的
具体的代码如下:
1 | public void delete(int key){ |
可以再根据下面这幅图理解一下:)
理论分析
我们前面用了那么大的力气来讲解二叉查找树,那么它的性能怎么样呢?
其实,对于二叉查找树来说,不管是插入、删除还是查找操作,时间复杂度都和树的高度成正比,也就是O(H),因为每次操作都对应了一条从根节点向下的一条路径。而对于树的高度,却很可能因树的形状的不同而不同。
理想情况下,二叉查找树是一颗完全二叉树,每层的节点依次为 1、2、4、8、16…………,不难发现,树的高度为log(N),所以时间复杂度为 O(logN),这是一个相当高效的算法了。下面是一张表格,对常见的符号表的耗时成本做了一个简单的对比。
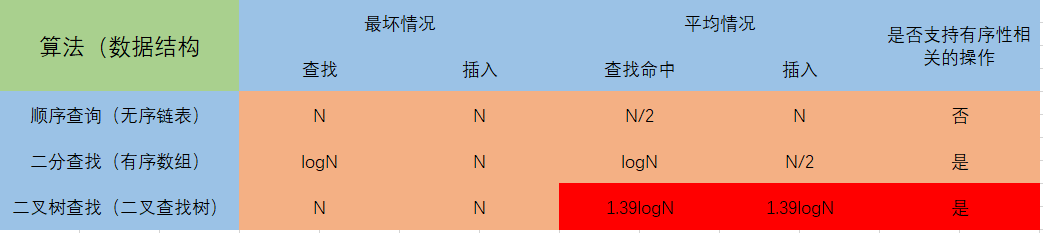
据此可见二叉查找树的性能,它能够在O(logN)的时间复杂度内完成查找和插入操作,我们花这么大力气学习它是值得的!
但是,你有没有注意到,它的最坏情况依旧是O(logN)。二叉查找树在一定条件下可能会退化成链表,就像下图所示,这明明就是一个弯曲的链表!
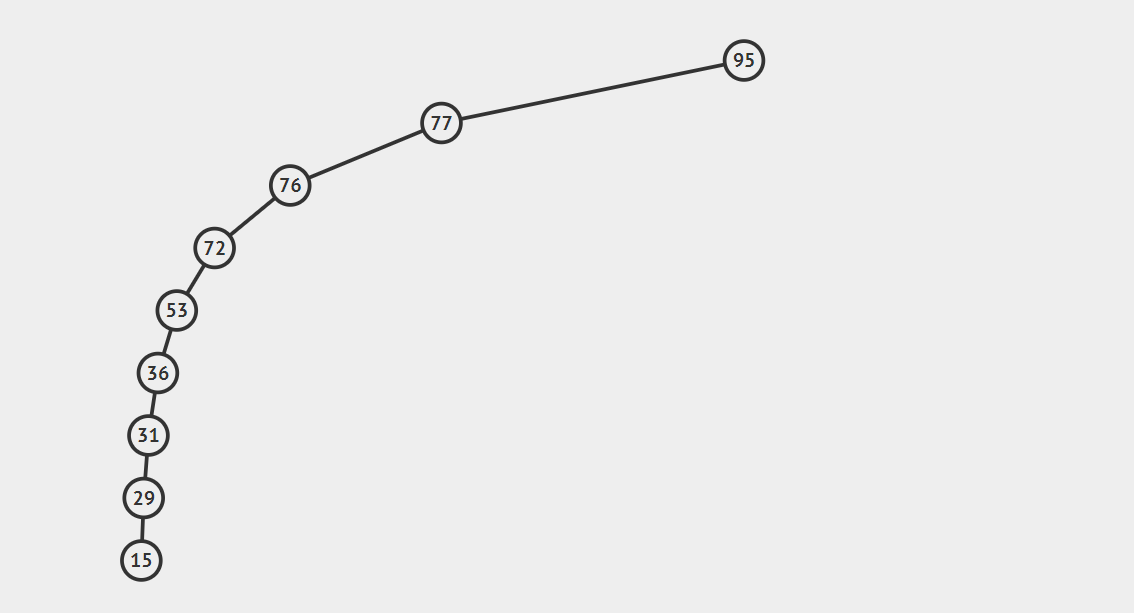
我们希望找到一种数据结构,它能保证无论键的插入顺序如何,树的高度将总是总键数的对数,这就是平衡二叉查找树,更精确一点,我们在下一篇文章中介绍红黑树!(预告一下)
全文完










